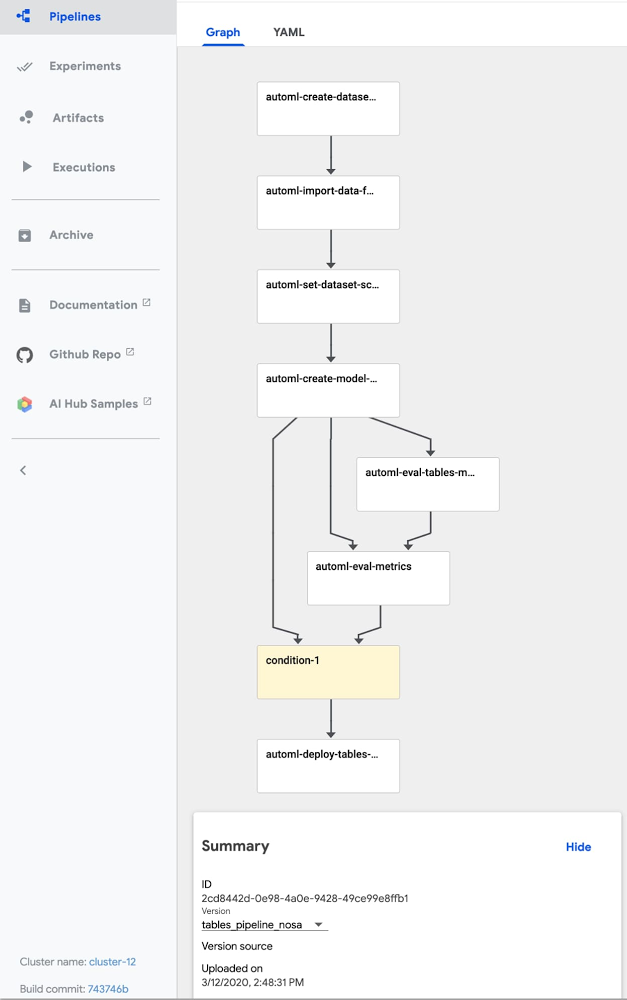
AutoML Tables lets you automatically build, analyze, and deploy state-of-the-art machine learning models using your own structured data. It’s useful for a wide range of machine learning tasks, such as asset valuations, fraud detection, credit risk analysis, customer retention prediction, analyzing item layouts in stores, solving comment section spam problems, quickly categorizing audio content, predicting rental demand, and more.To help make AutoML Tables more useful and user friendly, we’ve released a number of new features, including:An improved Python client libraryThe ability to obtain explanations for your online predictionsThe ability to export your model and serve it in a container anywhereThe ability to view model search progress and final model hyperparameters in Cloud LoggingThis post gives a tour of some of these new features via a Cloud AI Platform Pipelines example that shows end-to-end management of an AutoML Tables workflow. Cloud AI Platform Pipelines provides a way to deploy robust, repeatable machine learning pipelines along with monitoring, auditing, version tracking, and reproducibility, and delivers an enterprise-ready, easy to install, secure execution environment for your ML workflows. About our example pipelineThe example pipeline creates a dataset, imports data into the dataset from a BigQuery view, and trains a custom model on that data. Then, it fetches evaluation and metrics information about the trained model, and based on specified criteria about model quality, uses that information to automatically determine whether to deploy the model for online prediction. Once the model is deployed, you can make prediction requests, and obtain prediction explanations as well as the prediction result.The example also shows how to scalably serve your exported trained model from your Cloud AI Platform Pipelines installation for prediction requests.You can manage all the parts of this workflow from the Cloud Console Tables UI, as well, or programmatically via a notebook or script. But specifying this process as a workflow has some advantages: the workflow becomes reliable and repeatable, and Pipelines makes it easy to monitor the results and schedule recurring runs.For example, if your dataset is updated regularly—say once a day— you could schedule a workflow to run daily, each day building a model that trains on an updated dataset. (With a bit more work, you could also set up event-based triggering pipeline runs, for example when new data is added to a Google Cloud Storage bucket.)About our example dataset and scenarioThe Cloud Public Datasets Program makes available public datasets that are useful for experimenting with machine learning. To stay consistent with our previous post, Explaining model predictions on structured data, for our examples, we’ll use data that is essentially a join of two public datasets stored in BigQuery: London Bike rentals and NOAA weather data, with some additional processing to clean up outliers and derive additional GIS and day-of-week fields. Using this dataset, we’ll build a regression model to predict the duration of a bike rental based on information about the start and end rental stations, the day of the week, the weather on that day, and other data. If we were running a bike rental company, we could use these predictions—and their explanations—to help us anticipate demand and even plan how to stock each location.While we’re using bike and weather data here, as we mentioned above you can use AutoML Tables for a wide variety of tasks.Using Cloud AI Platform Pipelines to orchestrate a Tables workflowCloud AI Platform Pipelines, now in Beta, provides a way to deploy robust, repeatable machine learning pipelines along with monitoring, auditing, version tracking, and reproducibility. It also delivers an enterprise-ready, easy to install, secure execution environment for your ML workflows. AI Platform Pipelines is based on Kubeflow Pipelines (KFP) installed on a Google Kubernetes Engine (GKE) cluster, and can run pipelines specified via both the KFP and TFX SDKs. See this blog post for more detail on the Pipelines tech stack.You can create an AI Platform Pipelines installation with just a few clicks. After installing, you access AI Platform Pipelines by visiting the AI Platform Panel in the Cloud Console. (See the documentation as well as the sample’s README for installation details.)Upload and run the Tables end-to-end PipelineOnce a Pipelines installation is running, we can upload the example AutoML Tables pipeline. Click on Pipelines in the left nav bar of the Pipelines Dashboard, then on Upload Pipeline. In the form, leave Import by URLselected, and paste in this URL: https://storage.googleapis.com/aju-dev-demos-codelabs/KF/compiled_pipelines/tables_pipeline_caip.py.tar.gz. The link points to the compiled version of this pipeline, specified using the Kubeflow Pipelines SDK. The uploaded pipeline will look similar to this:The uploaded Tables “end-to-end” pipeline.Next, click the +Create Run button to run the pipeline. You can check out the example’s README for details on configuring the pipeline’s input parameters. You can also schedule a recurrent set of runs, instead. If your data is in BigQuery—as is the case for this example pipeline—and has a temporal aspect, you could define a view to reflect that, e.g. to return data from a window over the last N days or hours. Then, the AutoML pipeline could specify ingestion of data from that view, grabbing an updated data window each time the pipeline is run, and building a new model based on that updated window.The steps executed by the pipelineThe example pipeline creates a dataset, imports data into the dataset from a BigQuery view, and trains a custom model on that data. Then, it fetches evaluation and metrics information about the trained model, and based on specified criteria about model quality, uses that information to automatically determine whether to deploy the model for online prediction. In this section, we’ll take a closer look at each of the pipeline steps and how they’re implemented. You can also inspect your custom model graph in TensorBoard and export it for serving in a container, as described in a later section.Create a Tables dataset and adjust its schemaThis pipeline creates a new Tables dataset, and ingests data from a BigQuery table for the “bikes and weather” dataset described above. These actions are implemented by the first two steps in the pipeline—the automl-create-dataset-for-tables and automl-import-data-for-tables steps.While we’re not showing it in this example, AutoML Tables supports ingestion from BigQuery views as well as tables. This can be an easy way to do feature engineering: leveraging BigQuery’s rich set of functions and operators to clean and transform your data before you ingest it.When the data is ingested, AutoML Tables infers the data type for each field (column). In some cases, those inferred types may not be what you want. For example, for our “bikes and weather” dataset, several ID fields (like the rental station IDs) are set by default to be numeric, but we want them treated as categorical when we train our model. In addition, we want to treat the loc_cross strings as categorical rather than text.We make these adjustments programmatically, by defining a pipeline parameter that specifies the schema changes we want to make.Then, in the automl-set-dataset-schema pipeline step, for each indicated schema adjustment , we call update_column_spec:Before we can train the model, we also need to specify the target column—what we want our model to predict. In this case, we’ll train the model to predict rental duration. This is a numeric value, so we’ll be training a regression model.In the Tables UI, the result of these programmatic adjustments looks like this:Train a custom model on the datasetOnce the dataset is defined and its schema is set properly, the pipeline will train the model. This happens in the automl-create-model-for-tables pipeline step. Via pipeline parameters, we can specify the training budget, the optimization objective (if not using the default), and which columns to include or exclude from the model inputs. You may want to specify a non-default optimization objective depending upon the characteristics of your dataset. This table describes the available optimization objectives and when you might want to use them. For example, if you were training a classification model using an imbalanced dataset, you might want to specify use of AUC PR (MAXIMIZE_AU_PRC), which optimizes results for predictions for the less common class.View model search information via Cloud LoggingYou can view details about an AutoML Tables model via Cloud Logging. Using Logging, you can see the final model hyperparameters as well as the hyperparameters and object values used during model training and tuning.An easy way to access these logs is to go to the AutoML Tables page in the Cloud Console. Select the Models tab in the left navigation pane and click on the model you’re interested in, then click the Model link to see the final hyperparameter logs. To see the tuning trial hyperparameters, simply click the Trials link.Viewing a model’s search logs from its evaluation information.For example, here’s a look at the Trials logs a custom model trained on the “bikes and weather” dataset, with one of the entries expanded in the logs:The “Trials” logs for a “bikes and weather” model.Custom model evaluation Once your custom model has finished training, the pipeline moves on to its next step: model evaluation. We can access evaluation metrics via the API. We’ll use this information to decide whether or not to deploy the model. These actions are factored into two steps. The process of fetching the evaluation information can be a general-purpose component (pipeline step) used in many situations; and then we’ll follow that with a more special-purpose step that analyzes that information and uses it to decide whether or not to deploy the trained model. In the first of these pipeline steps—the automl-eval-tables-model step—we’ll retrieve the evaluation and global feature importance information.AutoML Tables automatically computes global feature importance for a trained model. This shows, across the evaluation set, the average absolute attribution each feature receives. Higher values mean the feature generally has greater influence on the model’s predictions.This information is useful for debugging and improving your model. If a feature’s contribution is negligible—if it has a low value—you can simplify the model by excluding it from future training. The pipeline step renders the global feature importance data as part of the pipeline run’s output:Global feature importance for the model inputs, rendered by a Kubeflow Pipeline step.For our example, based on the graphic above, we might try training a model without including bike_id.In the following pipeline step—the automl-eval-metrics step—the evaluation output from the previous step is grabbed as input and parsed to extract metrics that we’ll use with pipeline parameters to decide whether or not to deploy the model. One of the pipeline input parameters allows you to specify metric thresholds. In this example, we’re training a regression model, and we’re specifying a mean_absolute_error (MAE) value as a threshold in the pipeline input parameters:The pipeline step compares the model evaluation information to the given threshold constraints. In this case, if the MAE is < 450, the model will not be deployed. The pipeline step outputs that decision and displays the evaluation information it’s using as part of the pipeline run’s output:Information about a model’s evaluation, rendered by a Kubeflow Pipeline step.(Conditional) model deploymentYou can deploy any of your custom Tables models to make them accessible for online prediction requests. The pipeline code uses a conditional test to determine whether to run the step that deploys the model, based on the output of the evaluation step described above:Only if the model meets the given criteria, will the deployment step (called automl-deploy-tables-model) be run, and the model be deployed automatically as part of the pipeline run:You can always deploy a model later, via the UI or programmatically, if you prefer.Putting it together: The full pipeline executionThe figure below shows the result of a pipeline run. In this case, the conditional step was executed—based on the model evaluation metrics—and the trained model was deployed. Via the UI, you can view outputs and logs for each step, run artifacts and lineage information, and more. See this post for more detail.Execution of a pipeline run in progress. You can view outputs and logs for each step, run artifacts and lineage information, and more.Getting explanations about your model’s predictionsOnce a model is deployed, you can request predictions from that model, as well as explanations for local feature importance: a score showing how much (and in which direction) each feature influenced the prediction for a single example. See this blog post for more information on how those values are calculated.Here’s a notebook example of how to request a prediction and its explanation using the Python client libraries.The prediction response will have a structure like this. (The notebook above shows how to visualize the local feature importance results using matplotlib.)It’s easy to explore local feature importance through the Cloud Console’s AutoML Tables UI,as well. After you deploy a model, go to the TEST & USE tab of the Tables panel, select ONLINE PREDICTION, enter the field values for the prediction, and then check the Generate feature importance box at the bottom of the page. The result will show the feature importance values as well as the prediction. This blog post gives some examples of how these explanations can be used to find potential issues with your data or help you better understand your problem domain.The AutoML Tables UI in the Cloud ConsoleWith this example we’ve focused on how you can automate a Tables workflow using Kubeflow pipelines and the Python client libraries.All of the pipeline steps can also be accomplished via the AutoML Tables UI in the Cloud Console, including many useful visualizations, and other functionality not implemented by this example pipeline—such as the ability to export the model’s test set and prediction results to BigQuery for further analysis.Export the trained model and serve it on a GKE clusterTables also has a feature that lets you export your full custom model, packaged so that you can serve it via a Docker container. This lets you serve your models anywhere that you can run a container. For example, this blog post walks through the steps to serve the exported model using Cloud Run. Similarly, you can serve your exported model from any GKE cluster, including the cluster created for an AI Platform Pipelines installation. Follow the instructions in the blog post above to create your container. Then, you can create a Kubernetes deployment and service to serve your model, by instantiating this template.Once the service is deployed, you can send it prediction requests. The sample’s README walks through this process in more detail. View your custom model’s graphYou can also view the graph of your custom model using TensorBoard. This blog postgives more detail on how to do that.You can view the model graph for a custom Tables model using TensorBoard.Summary and what’s nextIn this post, we highlighted some of the newer AutoML Tables features, including an improved Python SDK, support for explanations of online predictions, the ability to export your model and serve it from a container anywhere, and the ability to track model search progress and final model hyperparametersin Cloud Logging. In addition, we showed how you can use Cloud AI Platform Pipelines to orchestrate end-to-end Tables workflows: from creating a dataset, ingesting your structured data, and training a custom model on your data; to fetching evaluation data and metrics on your model and determining whether to deploy it based on that information. The sample code also shows how you can scalably serve an exported trained model from your Cloud AI Platform Pipelines installation. You may also be interested to try a recently-launched BigQuery ML Beta feature: the ability to train an AutoML Tables model from inside BigQuery.A deeper dive into the pipeline codeSee the sample’s README for a more detailed walkthrough of the pipeline code. The new Python client library makes it very straightforward to build the Pipelines components that support each stage of the workflow.
Quelle: Google Cloud Platform
Published by