For teams building AI-governed systems, the EU AI Act adds compliance obligations to every stage of the development lifecycle, from documenting training data to reporting incidents in production. With phased enforcement already underway, now is the time to assess where your workflows stand.
The EU AI Act (Regulation (EU) 2024/1689) is the world’s first comprehensive AI regulation. It entered into force in August 2024 with requirements rolling out in phases through 2027. The Act applies, among others, to any organization that places an AI system on the EU market, deployers of AI systems established in the EU, or whose AI system’s output is used in the EU, regardless of where that organization is headquartered.
This guide covers what each risk tier requires, the full compliance timeline (including the 2026 Digital Omnibus adjustments), transparency obligations, penalties, and what compliance looks like for the teams building and operating AI systems.
Key takeaways
The EU AI Act uses a four-tier risk model; your obligations depend on how your system is classified.
Prohibited practices and GPAI rules are already in effect; high-risk deadlines run through 2027.
Article 50 regarding deepfake and synthetic content labeling obligations take effect August 2, 2026.
Penalties reach €35 million or 7% of global turnover, enforced by national authorities and the EU AI Office.
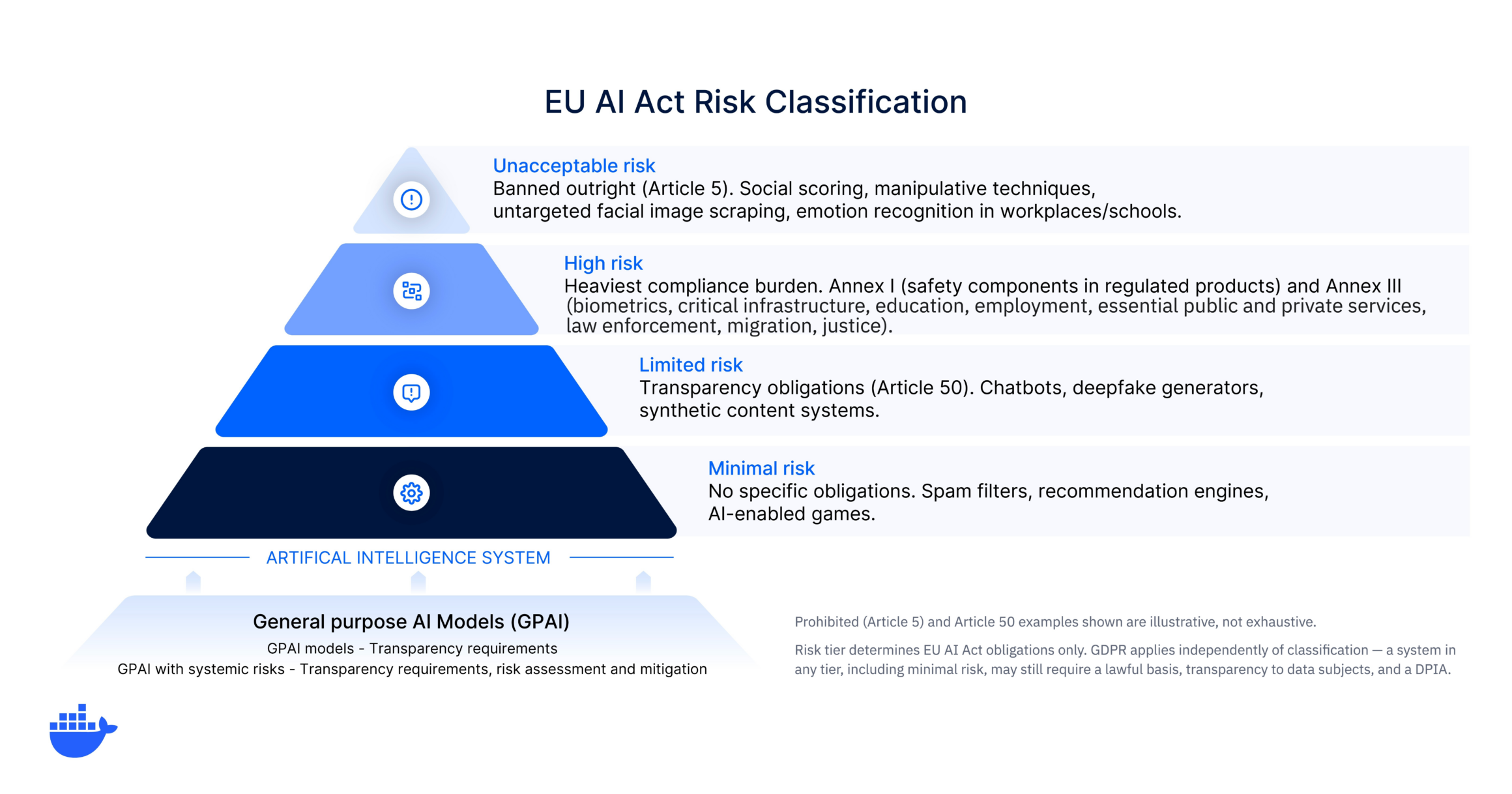
The four risk tiers
The AI Act takes a risk-based approach. Every AI system falls into one of four categories, and the category determines the regulatory obligations that apply. This classification drives the entire compliance process.
1. Unacceptable risk (prohibited)
AI systems in this tier are banned outright under Article 5. These prohibitions have been in effect since February 2, 2025. The prohibited practices include:
Subliminal, manipulative, or deceptive techniques that distort behavior and cause significant harm
Exploitation of vulnerabilities related to age, disability, or socioeconomic circumstances
Social scoring systems that evaluate individuals based on social behavior or personal traits
Predictive policing based solely on profiling or personality traits
Untargeted scraping of facial images from the internet or CCTV to build facial recognition databases
Emotion recognition in workplaces and educational institutions (except for medical or safety reasons)
Biometric categorization to deduce or infer certain protected characteristics (except for labelling or filtering of lawfully acquired biometric datasets)
Real-time remote biometric identification in publicly accessible spaces for law enforcement, with narrow exceptions for missing persons, imminent threats, and serious crime investigations
2. High risk (regulated)
High-risk AI systems are subject to the most extensive compliance obligations. The Act identifies two paths to high-risk classification:
Annex I systems: AI used as a safety component or product covered by existing EU product safety legislation (medical devices, machinery, vehicles) that requires a third-party conformity assessment.
Annex III systems: AI used in eight sensitive areas: biometrics, critical infrastructure, education, employment, essential public and private services, law enforcement, migration and border control, and administration of justice.
Any AI system used to profile individuals within an Annex III use case is automatically classified as high-risk, regardless of other exemptions. Providers who believe their Annex III system is not high-risk must document that assessment before placing it on the market.
This is the tier that puts the heaviest demands on your logging, testing, and documentation pipelines.
Annex III exceptions: An AI system listed under Annex III is not considered high-risk if it performs a narrow procedural task, improves a previously completed human activity, detects decision-making patterns without replacing human judgment, or performs a preparatory task for an Annex III assessment.
3. Limited risk (transparency risk)
AI systems in this tier face requirements focused on transparency and disclosure. Under Article 50, deployers must ensure that users know they are interacting with an AI system (e.g., chatbots), and providers of generative AI must mark synthetic content as AI-generated. This tier is where deepfake obligations sit, covered in detail below.
For software engineers, this comes down to marking generated content in a machine-readable way and surfacing the disclosure where users actually see it.
4. Minimal risk (unregulated)
The majority of AI systems currently on the market, including spam filters, AI-enabled games, and recommendation engines, fall here. No specific regulatory obligations apply, though the Act encourages voluntary codes of conduct.
The compliance timeline
The EU AI Act’s requirements take effect in phases, not all at once. Some obligations are already enforceable. Others will not apply until late 2027.
Date
What takes effect
August 1, 2024
AI Act enters into force (Regulation (EU) 2024/1689 published).
February 2, 2025
Prohibited AI practices under Article 5 become unlawful. AI literacy obligations begin (Article 4).
August 2, 2025
General-purpose AI (GPAI) model obligations take effect (Chapter V). Governance bodies established. Penalty provisions become applicable. Code of Practice for GPAI published.
August 2, 2026
General date of application of the AI Act. Transparency obligations under Article 50 take effect, including deepfake labeling and synthetic content marking. Member States must have at least one AI regulatory sandbox operational.
December 2, 2026*
Machine-readable marking obligations under Article 50(2) apply to AI systems, including GPAI systems, which have been placed on the market before August 2, 2026 (four-month grace period). Article 5 prohibition on AI-generated non-consensual intimate imagery and child sexual abuse material becomes applicable.
August 2, 2027
Obligations for high-risk AI systems embedded in regulated products under Annex I (Article 6(1)). GPAI models placed on the market before August 2025 must be in compliance.
December 2, 2027*
Standalone Annex III high-risk AI system requirements take full effect (risk management, conformity assessment, technical documentation, CE marking, EU database registration).
August 2, 2028*
High-risk AI systems that are components of products covered by Annex I product safety legislation.
*Omnibus adjustment: The Digital Omnibus package revised these high-risk deadlines, moving the Annex III standalone high-risk deadline from August 2026 to December 2, 2027, and the Annex I embedded high-risk deadline from August 2027 to August 2, 2028. The European Parliament approved the package on June 16, 2026.
Obligations for high-risk systems by role
The EU AI Act distinguishes between providers, deployers, importers, and distributors. Their obligations differ by role.
Providers+
Providers of high-risk AI systems carry the heaviest compliance burden. Among other obligations, they must:
Risk management system: Establish and maintain a risk management process throughout the AI system’s lifecycle, not just at launch.
Data governance: Ensure that training, validation, and testing datasets are subject to appropriate data governance and management practices and are relevant, sufficiently representative, and as free of errors as possible. Where these datasets contain personal data, the GDPR also applies: you need a lawful basis, data minimization, and, for any special-category data used to detect and correct bias, the specific safeguards.
Technical documentation: Produce documentation that demonstrates compliance and provides authorities with the information to assess it. It shall contain, at minimum, the elements contained in Annex IV.
Record-keeping and documentation: Design the system to automatically log events relevant to identifying risks and tracking modifications. Providers must keep certain documents for up to 10 years at the disposal of the competent authorities.
Transparency and instructions for use: Provide deployers with clear documentation on the system’s capabilities, limitations, intended use, and human oversight requirements, which allows deployers to interpret a system’s output and use it appropriately.
Human oversight: Design the system so that deployers can implement effective human oversight during use.
Accuracy, robustness, and cybersecurity: Achieve appropriate performance levels across all three dimensions.
Quality management system: Establish and document a QMS that covers the full compliance process.
Corrective actions: Take necessary corrective action in case of suspected non-conformity of the AI system with the AI Act, including bringing it into conformity, withdrawing it, disabling it or recall it, as appropriate.
Cooperation with authorities: Provide information and documentation necessary to competent authorities and giving access to automatically generated logs, upon request, to demonstrate conformity of the AI system with the AI Act.
Authorized representatives: Providers established in third-party countries must appoint a representative established in the Union prior to making the high-risk AI system available on the Union market.
Conformity assessment: Ensure that the appropriate conformity assessment procedure is completed prior to placing the AI system on the market. Additionally, drawing up an EU declaration of conformity, affix CE marking, and register the system in the EU database before placing it on the market.
Post-market monitoring: Providers shall establish and document a post-market monitoring system in a manner that is proportionate to the nature of the AI technologies and the risks of the high-risk AI system.
Reporting: Providers shall report any serious incident to the market surveillance authorities. The AI Act establishes different terms for reporting, which vary according to the incident’s severity.
Deployers+
Deployers are natural or legal persons, public authorities, agencies or other bodies that use an AI system under its authority. Those using AI systems in the course of a personal non-professional activity are not considered deployers. Under Article 26, deployers of high-risk systems must:
Use the system as instructed: Operate it the way the provider’s instructions for use specify.
Assign human oversight: Put oversight in the hands of people with the competence and authority to exercise it.
Govern input data: Where the deployer controls the input data, make sure it’s relevant and sufficiently representative for the system’s intended purpose.
Monitor and escalate: Monitor the operation of the AI system, and if it starts to present a risk, notify the provider or the distributor and the market surveillance authority and suspend use.
Keep logs: Retain the logs the system generates automatically, to the extent they’re under the deployer’s control, for at least six months.
Notify the workforce: Tell affected workers and their representatives before a high-risk system goes live in the workplace.
Inform affected people: When an Annex III system makes decisions, or assists in making decisions, about individuals, those individuals have to be told. This overlaps with GDPR transparency and where the system makes solely automated decisions with legal or similarly significant effects, so coordinate the AI Act notice with your GDPR notices.
Support data protection assessments: Use the information the provider supplies to meet any data protection impact assessment obligation under the GDPR.
Cooperate with authorities: Work with competent authorities on any action they take regarding the system.
Register, if public: Public authorities must register the deployment in the EU database and shall not run a system while it isn’t.
Article 27 adds a fundamental rights impact assessment for a narrower group: public bodies, private entities providing public services, and deployers using Annex III systems for credit scoring or insurance pricing. Before first use, they document how the system will be used, who it could affect, the risks involved, and the human oversight in place, then file the results with the market surveillance authority.
For engineering teams, most of these duties come down to monitoring, log retention, and the ability to suspend a system fast. They get solved in your infrastructure, not in a policy document.
Important: Under the EU AI Act, operators in the AI-value chain can be considered both providers and deployers. Put your name on a high-risk system, modify one substantially, or repurpose a non-high-risk system into a high-risk use, and you’re reclassified as a provider with the full obligation set (Article 25).
Importers+
Importers are the EU-based persons or organizations that place a non-EU provider’s high-risk AI system on the market, and Article 23 makes them a checkpoint for conformity before the system reaches EU users. Importers must:
Verify conformity before import: Confirm the provider has completed the conformity assessment, drawn up the technical documentation (Annex IV), affixed CE marking with the EU declaration of conformity and instructions for use, and appointed an authorized representative.
Block non-conforming systems: If there’s reason to believe a system isn’t in conformity, or its documentation is falsified, don’t place it on the market until it’s corrected. If the system presents a risk, inform the provider, the authorized representative, and the market surveillance authorities.
Add contact details: Put the importer’s name, registered trade name or trademark, and contact address on the system, its packaging, or its accompanying documentation.
Protect compliance in storage and transit: Make sure storage and transport conditions under the importer’s responsibility don’t compromise the system’s compliance.
Keep records for 10 years: Retain a copy of the notified-body certificate (where applicable), the instructions for use, and the EU declaration of conformity for 10 years after the system is placed on the market or put into service.
Respond to authorities: On a reasoned request, give competent authorities the information and documentation needed to demonstrate conformity, in a language they can readily understand.
Cooperate with authorities: Work with competent authorities on any action they take to reduce or mitigate the risks of a system the importer placed on the market.
An importer that puts its own name or trademark on a high-risk system, or substantially modifies one already on the market, is reclassified as a provider and takes on the full provider obligation set (Article 25).
Distributors+
Distributors are the other parties in the supply chain who make a high-risk system available on the EU market. Their duties under Article 24 overlap with an importer’s but focus on what happens at and after the point of sale. Distributors must:
Verify documentation before distribution: Confirm the system bears CE marking, comes with the EU declaration of conformity and instructions for use, and that the provider and importer have met their own obligations.
Block non-conforming systems: If there’s reason to believe a system isn’t in conformity, don’t make it available until it’s corrected. If it presents a risk, inform the provider or importer.
Protect compliance in storage and transit: Make sure storage and transport conditions under the distributor’s responsibility don’t compromise the system’s compliance.
Act on non-conformity after sale: If a system already made available turns out to be non-conforming, take corrective action to fix, withdraw, or recall it, or ensure the provider or importer does. If it presents a risk, immediately inform the provider or importer and the competent authorities.
Respond to authorities: On a reasoned request, provide the information and documentation on these actions needed to demonstrate conformity.
Cooperate with authorities: Work with competent authorities on any action they take regarding a system the distributor made available.
The same reclassification rule applies: a distributor that brands a high-risk system as its own or substantially modifies one already on the market becomes a provider under Article 25.
Deepfake and transparency obligations (Article 50)
Article 50 creates specific transparency requirements for AI systems that interact with people or generate synthetic content. These obligations generally apply from August 2, 2026 and are relevant regardless of the system’s risk classification.
Who must comply
Providers of AI systems that interact directly with people must ensure that individuals are informed they’re interacting with an AI system, unless this is obvious from the circumstances.
Providers of AI systems that generate synthetic content (audio, image, video, or text) must mark that output in a machine-readable format that’s detectable as AI-generated or manipulated. The marking must be effective, interoperable, robust, and reliable.
Deployers who use AI to create deepfakes must disclose that the content has been artificially generated or manipulated. The Act defines a deepfake as AI-generated or manipulated image, audio, or video content that resembles existing persons, objects, places, or events and would falsely appear authentic.
Deployers who publish AI-generated text on matters of public interest must label it as AI-generated, unless the content has been through human editorial review and a natural or legal person holds editorial responsibility.
Deployers of emotion recognition or biometric categorisation systems must inform the people exposed to the system that it’s operating, and handle their personal data in line with the GDPR.
Artistic exception regarding deepfakes: When AI-generated content is part of an evidently artistic, creative, satirical, or fictional work, only minimal and non-intrusive disclosure is required. The deepfake labeling obligation still applies, but the disclosure format can be lighter.
The Code of Practice for transparency
The European Commission developed a Code of Practice on marking and labeling AI-generated content to operationalize Articles 50(2) through 50(5). The code provides practical and technical guidance for real-world implementation of the marking and disclosure requirements. Its final version was published on June 10, 2026.
General-purpose AI model obligations
Chapter V of the Act creates a separate set of obligations for providers of general-purpose AI (GPAI) models. These rules have been applicable since August 2, 2025 (models placed on the market before that date have until August 2, 2027 to comply). The European Commission has published guidelines to support providers in meeting these requirements.
General-purpose AI models are the broad, multi-purpose models that show significant generality, perform a wide range of distinct tasks, and can be used directly as well as integrated into other AI systems.
All GPAI model providers
Every provider of a GPAI model must draw up and maintain technical documentation (which shall contain at minimum the information set out in Annex VI), provide information and documentation to downstream providers integrating the model, establish a policy to respect the EU Copyright Directive, and publish a sufficiently detailed summary of the content used for training.
Providers of free and open-license GPAI models (where parameters, architecture, and usage information are publicly available) do not need to comply with the obligations regarding technical documentation and provision of information to downstream providers, unless the model presents a systemic risk.
GPAI models with systemic risk
A GPAI model is presumed to carry systemic risk if it was trained using more than 10²⁵ floating point operations (FLOPs) of compute. That bar was set to capture the frontier models of the day: GPT-4 is widely estimated to sit above it, while the earlier GPT-3 was trained on roughly 30 times less. The Commission can also designate other models as systemic on criteria like the number of end users, high-impact capabilities, or output modalities.
Providers of systemic-risk models carry every GPAI obligation above, plus four more:
Model evaluation: Run model evaluations, including adversarial testing.
Risk mitigation: Assess and mitigate the systemic risks the model could pose.
Incident reporting: Track and report serious incidents to the AI Office.
Cybersecurity: Maintain an adequate level of protection for the model.
A voluntary Code of Practice for general-purpose AI models was published in July 2025. Following a code of practice creates a presumption of conformity until European harmonized standards are in place.
Penalties and enforcement
The EU AI Act establishes a three-tier penalty structure under Article 99, designed to be effective, proportionate, and dissuasive.
Violation
Maximum fine
Turnover threshold
Prohibited AI practices (Article 5)
€35 million
7% of global annual turnover
High-risk AI system non-compliance (specific provisions)
€15 million
3% of global annual turnover
Supplying incorrect or misleading information to authorities
€7.5 million
1% of global annual turnover
Enforcement is split between the European AI Office, which oversees GPAI model providers, and national competent authorities in each Member State, which handle all other operators.
Each Member State must designate at least one national authority for implementation and market surveillance. The penalty provisions are designed to account for the interests of small and medium-sized enterprises and startups, and Member States report annually to the Commission on fines issued.
What compliance looks like for engineering teams
The EU AI Act’s requirements are written in regulatory language, but they translate to concrete engineering concerns. If your team builds or deploys AI systems that serve EU users, here’s where the Act’s obligations intersect with your development workflow.
Inventory and classification come first
Compliance starts with knowing what you have. Every AI system the organization builds, uses, or procures needs to be cataloged and classified against the Act’s risk tiers. Record, for each system, whether it processes personal data and link the entry to your GDPR records of processing (Article 30) so the AI inventory and the privacy record stay aligned.
This is not a legal exercise alone. Engineering teams are typically the only ones who understand the actual capabilities, data flows, and deployment contexts of the systems they build. If your organization has an AI governance framework in place, the AI inventory is usually its foundation.
Audit trails are non-negotiable
The Act requires automatic event logging for high-risk systems and structured documentation across almost every tier. This means every decision an AI system makes, the categories of data sources it accesses, and every action it takes needs to be logged in a way that is auditable.
Teams already shipping AI agents need structured event capture of system actions, including timestamp, session context, the tool or rule invoked, and the agent or service identity, scoped to system-health and security telemetry rather than individual worker performance. Exporting these logs to existing SIEM and compliance systems closes the gap between agent behavior and audit requirements.
Prepare your risk management system
Article 9 requires a continuous risk management process, including control measures for risks that can’t be removed by design.
The ability to enforce policies is the mechanism that makes your chosen controls binding at the moment the agent acts, therefore acting as a risk mitigating strategy. This can happen at the agent level, by applying policies and rules to sandboxed agents, and at the tool level, with policies applied to the gateway that manages agent tool access.
Runtime isolation supports human oversight
The EU AI Act requires that high-risk AI systems be designed for human oversight, and that deployers can intervene during operation. For agentic workloads, where AI acts autonomously, this maps directly to runtime isolation: running agents inside sandboxed environments where network access, filesystem scope, and tool permissions are policy-controlled.
If an agent exceeds its intended scope, isolation constrains the blast radius. This is the mechanism that makes oversight enforceable at the infrastructure level.
Transparency can be instrumented
Article 50’s deepfake and synthetic content marking requirements are a metadata problem. Providers need to embed machine-readable markers in generated content, and deployers need to surface human-readable disclosures.
For teams building generative AI systems, this means integrating content provenance marking (such as C2PA or IPTC standards) into the generation pipeline. Where generated content depicts a real, identifiable person, it is also personal data under the GDPR, so the marking is necessary but not sufficient and the usual lawful-basis and rights obligations still apply. The AI governance controls your organization uses can enforce these policies at the platform layer rather than relying on each application to implement them independently.
Use the official compliance tools
The European Commission has launched the AI Act Service Desk, a single information platform that includes an official Compliance Checker to help organizations determine which obligations apply to their AI systems, an AI Act Explorer for navigating the full regulation text, and a helpdesk for submitting questions. These tools are free, official, and available in English, French, and German (with all 24 EU languages planned for 2026).
Start building compliance into your AI infrastructure
EU AI Act compliance is not a document you file. It’s a set of technical controls, organizational processes, and audit practices that need to be embedded in how your team builds and operates AI systems.
To make things easier, Docker AI Governance supports operationalizing these requirements. It does not replace the human oversight, classification, and legal accountability the AI Act assigns to providers and deployers, and customer code, configurations, and telemetry are not used to train Docker’s or third-party models. Instead, Docker AI Governance includes sandbox-based runtime isolation for blast-radius risk mitigation and real time monitoring, policy enforcement across network, filesystem, and MCP tool access, and structured audit logging that exports to existing SIEM and compliance systems.
Explore Docker AI Governance to see how runtime policy, audit trails, and agent isolation support the regulatory controls the EU AI Act requires.
Frequently asked questions
Does the EU AI Act apply to companies outside the EU?
Yes. Under Article 2, the EU AI Act applies to providers and deployers of AI systems regardless of whether they’re established in the EU. You are in scope if you place an AI system on the EU market, or if the system’s output is used in the EU.
Is there an official EU AI Act compliance checker?
The European Commission’s AI Act Service Desk includes a Compliance Checker tool that helps organizations determine which obligations apply to their AI systems. It walks through a series of questions about the system’s purpose, deployment context, and risk profile to identify relevant articles and requirements.
What are the EU AI Act deepfake requirements?
Under Article 50, providers of AI systems that generate synthetic audio, image, video, or text must mark the output in a machine-readable format as AI-generated. Deployers who use AI to create deepfakes (content resembling existing persons or events that would falsely appear authentic) must disclose that the content is artificially generated, even when the content is lawful. Artistic, creative, and satirical uses require only minimal disclosure.
These obligations take effect on August 2, 2026. Where a deepfake depicts a real, identifiable person, that content is also personal data under the GDPR, so labeling is necessary but not sufficient.
What is the difference between the AI Act and the Cyber Resilience Act?
The EU Cyber Resilience Act (CRA) targets products with digital elements and focuses on cybersecurity requirements across their lifecycle. The AI Act specifically targets AI systems and AI models, with requirements that scale based on risk classification. A product could be subject to both regulations, for example an AI-powered medical device that is both a product with digital elements (CRA) and a high-risk AI system (AI Act).
When do the high-risk AI system rules actually take effect?
The timeline depends on the type of high-risk system. Under the Digital Omnibus package, approved by the European Parliament on June 16, 2026, standalone Annex III high-risk systems must comply by December 2, 2027. Annex I embedded high-risk systems (products covered by EU product safety legislation) must comply by August 2, 2028. Check the official implementation timeline for the latest confirmed dates.
Quelle: https://blog.docker.com/feed/