New Application Manager brings GitOps to Google Kubernetes Engine
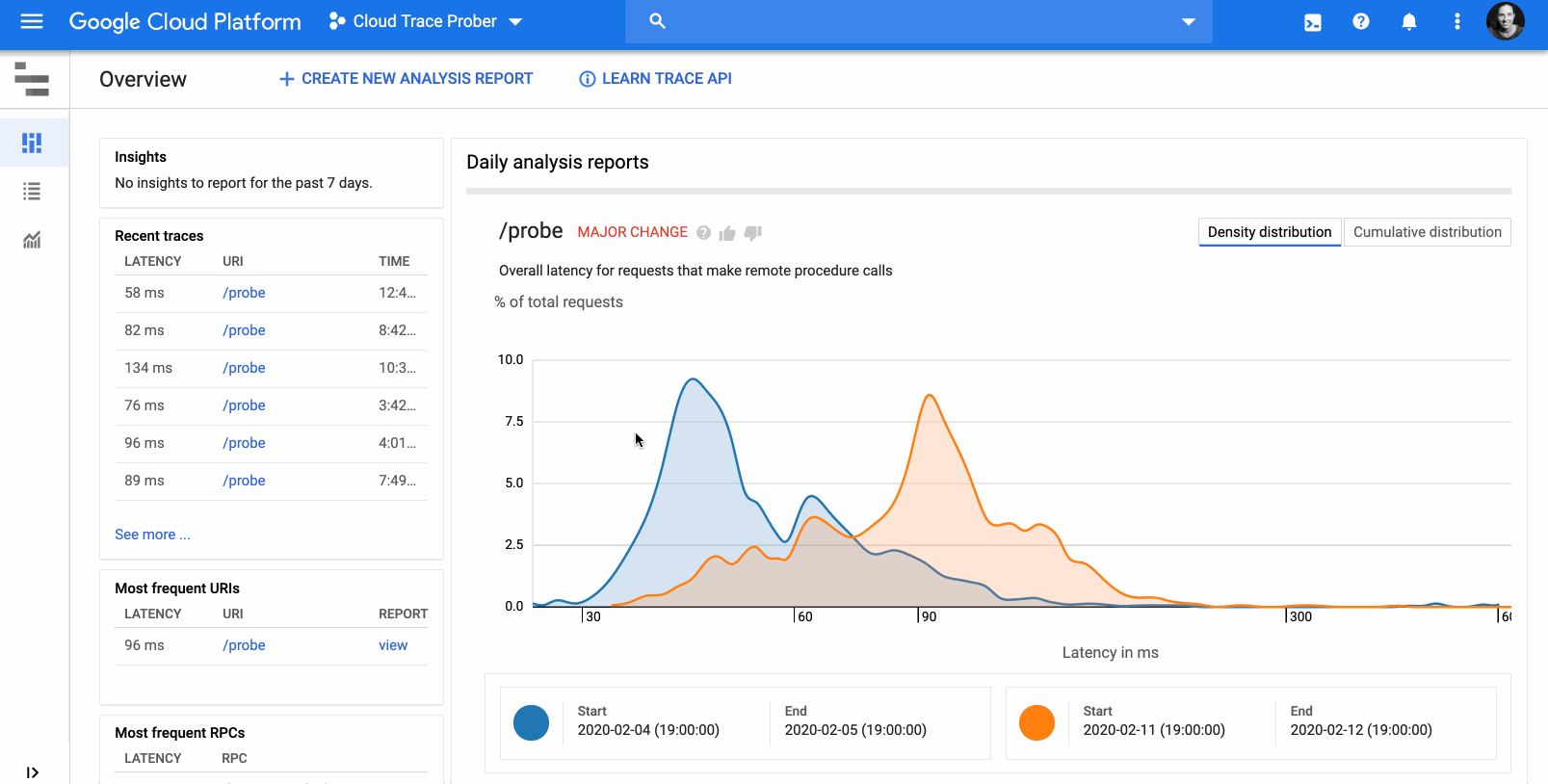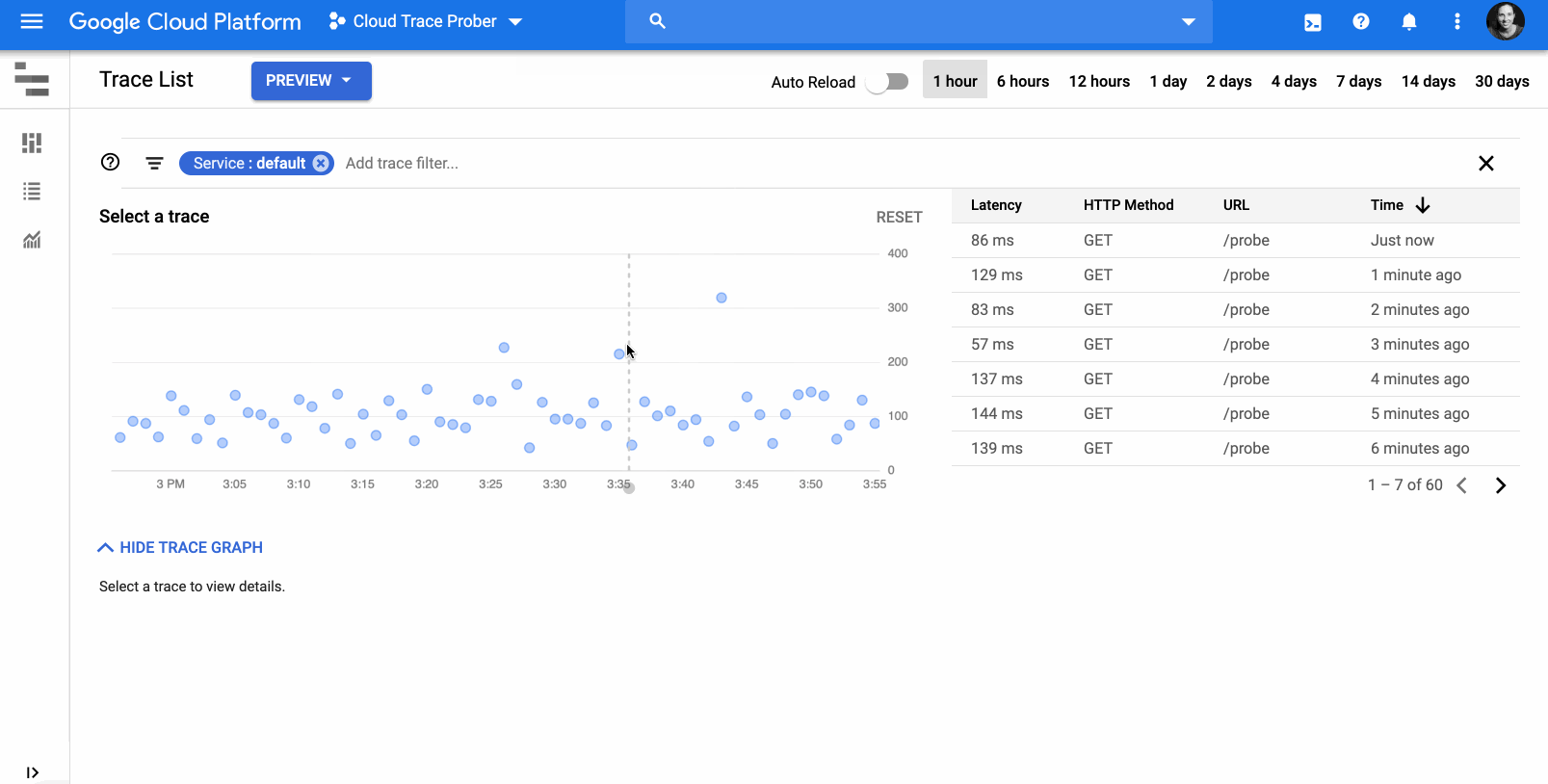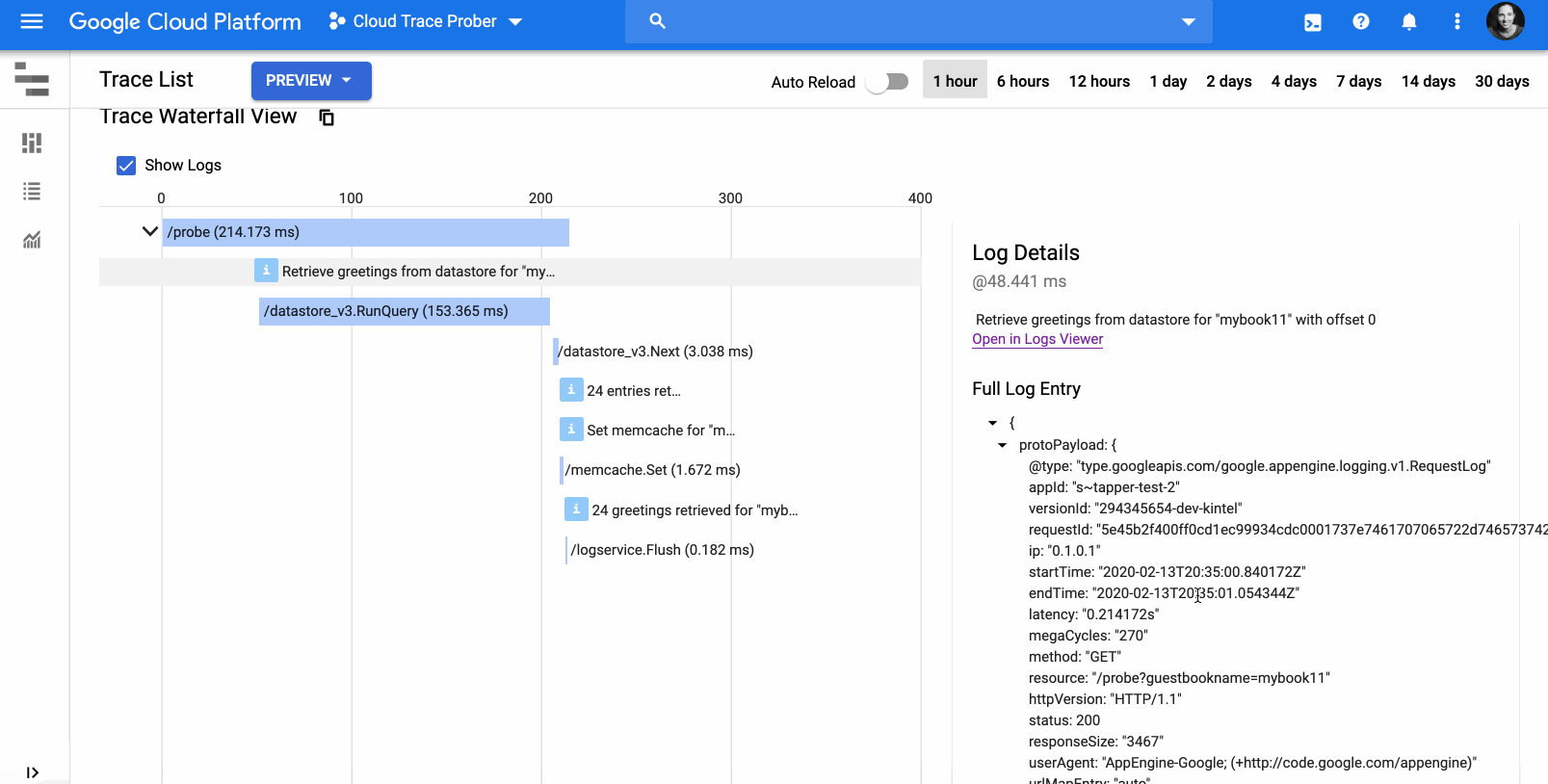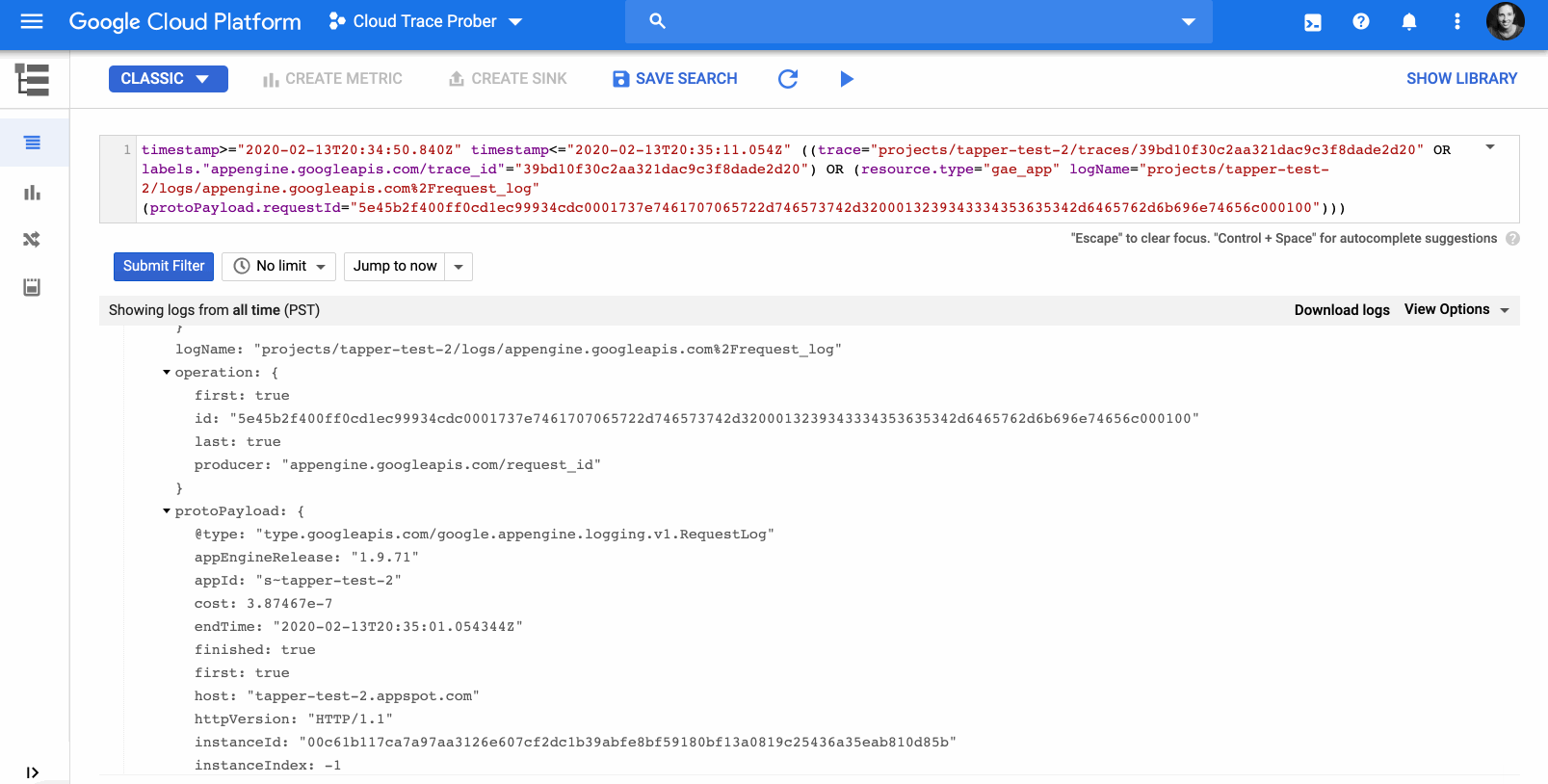
Kubernetes is the de facto standard for managing containerized applications, but developers and app operators often struggle with end-to-end Kubernetes lifecycle management—things like authoring, releasing and managing Kubernetes applications. To simplify the management of application lifecycle and configuration, today we are launching Application Manager, an application delivery solution delivered as an add-on to Google Kubernetes Engine (GKE). Now available in beta, Application Manager allows developers to easily create a dev-to-production application delivery flow, while incorporating Google’s best practices for managing release configurations. Application Manager lets you get your applications running in GKE efficiently, securely and in line with company policy, so you can succeed with your application modernization goals. Addressing the Kubernetes application lifecycleThe Kubernetes application lifecycle consists of three main stages: authoring, releasing and managing. Authoring includes writing the application source code and app-specific Kubernetes configuration. Releasing includes making changes to code and/or config, then safely deploying those changes to different release environments. The managing phase includes operationalizing applications at scale and in production. Currently, there are no well defined standards for these stages and users often ask us for best practices and recommendations to help them get started.Lifecycle of Kubernetes applicationIn addition, Kubernetes application configurations can be too long and complex to manage at scale. In particular, an application that is deployed across test, staging and production release environments might have duplicate configurations stored in multiple Git repositories. Any change to one config needs to be replicated to the others, creating the potential for human error. Application Manager embraces GitOps principles, leveraging Git repositories to enable declarative configuration management. It allows you to audit and review changes before they are deployed to environments. It also automatically scaffolds and enforces recommended Git repository structures, and allows you to perform template-free customization for configurations with Kustomize, a Kubernetes-native configuration management tool.Application Manager runs inside your GKE cluster as a cluster add-on, and performs the following tasks: It pulls Kubernetes manifests from a Git repository (within a git branch, tag or commit) and deploys the manifests as an application in the cluster. It reports metadata about deployed applications (e.g. version, revision history, health, etc.) and visualizes the applications in Google Cloud Console.Releasing an application with Application ManagerNow, let’s dive into more details on how to use Application Manager to release or deploy an application, from scaffolding Git repositories, defining application release environments, to deploying it in clusters. You can do all those tasks by executing simple commands in appctl, Application Manager’s command line interface. Here’s an example workflow of how you can release a “bookstore” app to both staging and production environments. First, initialize it by running appctl init bookstore –app-config-repo=github.com/$USER_OR_ORG/bookstore. This creates two remote Git repositories: 1) an application repository, for storing application configuration files in kustomize format (for easier configuration management), and 2) a deployment repository, for storing auto-generated, fully-rendered configuration files as the source of truth of what’s deployed in the cluster. After the Git repositories are initialized, you can add a staging environment to the bookstore app by running appctl env add staging –cluster=$MY_STAGING_CLUSTER, and do the same for prod environment. At this point, the application repository looks like this: Here, we are using kustomize to manage environment-specific differences in the configuration. With kustomize, you can declaratively manage distinctly customized Kubernetes configurations for different environments using only Kubernetes API resource files, by patching overlays on top of the base configuration.When you’re ready to release the application to the staging environment, simply create an application version with git tag in the application repository, and then run appctl prepare staging. This automatically generates hydrated configurations from the tagged version in the application repository, and pushes them to the staging branch of the deployment repository for an administrator to review. With this Google-recommended repository structure, Application Manager provides a clean separation between the easy-to-maintain kustomize configurations in the application repository, and the auto-generated deployment repository—an easy-to-review single source of truth; it also prevents these two repositories from diverging. Once the commits to hydrated configurations are reviewed and merged into the deployment repository, run appctl apply staging to deploy this application to the staging cluster. Promotion from staging to prod is as easy as appctl apply prod –from-env staging. To do rollback in case of failure, simply run appctl apply staging –from-tag=OLD_VERSION_TAG. What’s more, this appctl workflow can be automated and streamlined by executing it in scripts or pipelines. Application Manager for all your Kubernetes apps Now, with Application Manager, it’s easy to create a dev-to-production application delivery flow with a simple and declarative approach that’s recommended by Google. We are also working with our partners on the Google Cloud Marketplace to enable seamless updates of the Kubernetes applications you procure there, so you get automated updates and rollbacks of your partner applications. You can find more information here. For a detailed overview of Application Manager, please see this demo video. When you’re ready to get started, follow the steps in this tutorial.
Quelle: Google Cloud Platform