GKE best practices: Exposing GKE applications through Ingress and Services
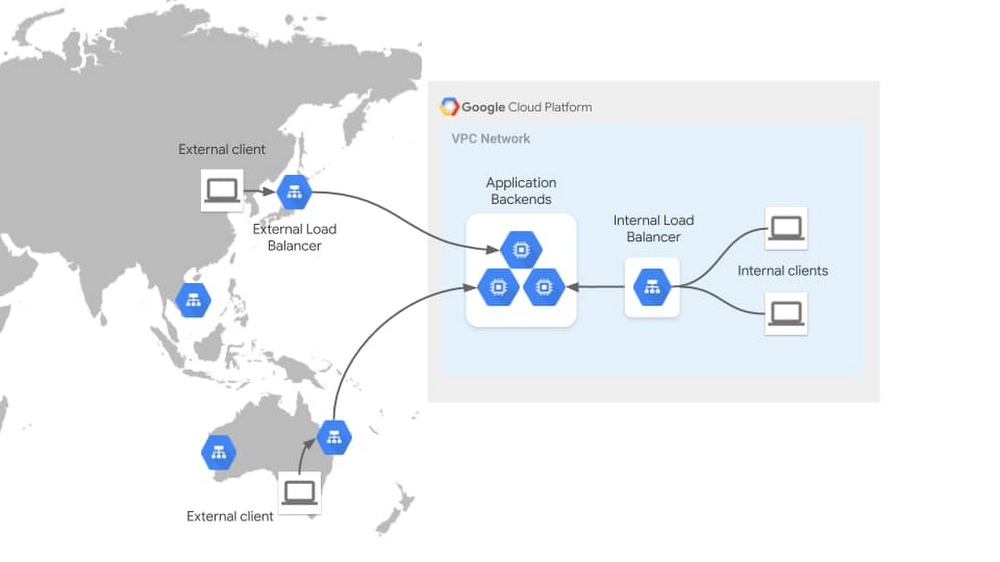
One critical part of designing enterprise applications running on Google Kubernetes Engine (GKE) is considering how your application will be consumed by its clients. This could be as simple as exposing your application outside the cluster, to be consumed by other internal clients, or might involve routing traffic to your application from public clients across the globe.How you should do this depends on many factors. Is the client from the internet or an internal network? Which networking protocols does the application speak? Is the application hosted in a single region or cluster, or is it deployed globally? Determining which solution to use to expose your application requires considering your application requirements in a few key areas. These requirements shouldn’t be assessed in isolation—you should look at them holistically to determine the most appropriate networking solution to expose your application.Let’s walk through the different factors that should be considered when exposing applications on GKE, explain how they impact application exposure, and highlight which networking solutions each requirement will drive you toward. Assuming you’re familiar with Kubernetes concepts such as Deployments, Services, and Ingress resources, we’ll differentiate between different exposure methods from internal, to external, to multi-cluster, and more.Understanding application exposureExposing an application to external clients involves three key elements, which together allow you to route traffic to your application: Frontend: The load balancer frontend defines the scope in which clients can access and send traffic to the load balancer. This is the network location that is listening for traffic—a network, a specific region or subnet within the network, one or more IPs in the network, ports, specific protocols, and TLS certificates presented to establish secure connections. Routing and load balancing: Routing and load balancing define how traffic is processed and routed. Traffic can be routed to services based on parameters such as protocol, HTTP headers, and HTTP paths. Depending on the load balancer you use, it may balance traffic across multiple zones or regions to provide lower latency and increased resiliency to your customers. Backends: Backends are defined by the type of endpoints, application platform, and backend service discovery integration. Specific application environments such as GKE are aided by service discovery integration, which updates load balancer backends dynamically as GKE endpoints come up and down. The following diagram illustrates these concepts for two very different types of traffic flows—external and internal traffic. The External HTTP(S) Load Balancer is listening for traffic on the public internet through hundreds of Google points of presence around the world. This global frontend allows traffic to be terminated at the edge, close to clients, before it load balances it to its backends in a Google data center. The Internal HTTP(S) load balancer depicted here listens within the scope of your VPC network, allowing private communications to take place internally. These load balancer properties make them suited for different kinds of application use cases.GKE load balancing through Ingress and Service controllersTo expose applications outside of a GKE cluster, GKE provides a built-in GKE Ingress controller and GKE Service controller which deploy Google Cloud Load Balancers (GCLBs) on behalf of GKE users. This is the same VM load balancing infrastructure, except its lifecycle is fully automated and controlled by GKE. The GKE network controllers provide container-native Pod IP load balancing via opinionated, higher-level interfaces that conform to the Ingress and Service API standards. The following diagram illustrates how the GKE network controllers automate the creation of load balancers: An infrastructure or app admin deploys a declarative manifest against their GKE cluster. Ingress & Service controllers watch for GKE networking resources (such as Ingress or MultiClusterIngress objects) and deploy Cloud load balancers (plus IP addressing, firewall rules etc) based on the manifest. The controller continues managing the LB and backends based on environmental and traffic changes. Thus, GKE load balancing becomes a dynamic and self-sustaining load balancer with a simple and developer-oriented interface.Factors that influence application exposureThere are numerous factors that will influence choosing a method for exposing your application in GKE. There are a few core factors that live at the base of your decision tree and will help narrow down the set of networking solutions. These factors are client network, protocol, and application regionality.Client network refers to the network from where your application clients are accessing the application. This influences where the frontend of your load balancer should be listening. For example, clients could be within the same GKE cluster as the application. In this case, they would be accessing your application from within the cluster network, allowing them to use Kubernetes native ClusterIP load balancing. Clients could also be internal network clients, accessing your application from within the Google Cloud VPC or from your on-premises network across a Google Cloud Interconnect. Clients could also be external, accessing your application from across the public internet. Each type of network dictates a different load balancing topology.Protocol is the language your clients speak to the application. Voice, gaming, and low-latency applications commonly speak directly on top of TCP or UDP, requiring load balancers that have granular control at L4. Other applications speak HTTP, HTTPS, gRPC, or HTTP2, and require load balancers with explicit support of these protocols. Protocol requirements further define which kinds of application exposure methods are the best fit. Application regionality refers to the degree that your application is distributed across more than one GCP region or GKE cluster. Hosting a single instance of an application has different requirements than hosting an active-passive application across two independent GKE clusters. Hosting a geographically distributed application across five GKE clusters to place workloads closer to the end user for lower latency requires even more multi-cluster and multi-regional awareness for the load balancer.There may be additional factors that will influence your networking design that aren’t covered below—things like latency requirements, source IP address preservation, or high bandwidth. This list is not intended to be exhaustive, but should help you narrow down your solution options and increase your understanding of the trade-offs between requirements.Application exposure through Ingress and ServicesFortunately, GKE’s suite of native Ingress and Service controllers makes exposing applications seamless, secure, and production-ready by default. These network controllers are tightly integrated with GCLBs, allowing Kubernetes-native interfaces to deploy GCLBs that load-balance natively to container IPs. The following table breaks down all of the GKE Ingress and Service types and details their primary characteristics. For a more detailed comparison of all the GKE and Anthos Ingress capabilities see Ingress Features.There are many native options, all with different capabilities from a protocol, network access, and regional perspective. The following section categorizes these networking solutions by the factors discussed above. Client networkLoad balancers in GKE can broadly be categorized as internal and external load balancers. Internal refers to the VPC network which is an internal private network not directly accessible from the internet. External refers to the public internet. Note that ClusterIP Services are internal to a single GKE cluster so they are scoped to an even smaller network than the VPC network.*Public GKE clusters provide public and private IPs to each GKE node and so NodePort Services can be accessible internally and externally.ProtocolLoad balancers are often categorized as Layer 4, which route traffic based on network information like port and protocol, and Layer 7, which have awareness of application information like client sessions. GKE load balancers can also be categorized as L4 and L7, with specific protocol support in the table below.Application regionalityThe regionality of GKE load balancing solutions can be broken down into two areas:Backend scope (or cluster scope) refers to whether a load balancer can send traffic to backends across multiple GKE clusters. Ingress for Anthos (or multi-cluster Ingress) has the ability to expose a single VIP that directs traffic to pods from different clusters and different Google Cloud regions.Frontend scope refers to whether a load balancer IP listens within a single region or across multiple regions. All of the external load balancers listen on the internet, which is inherently multi-region, but some internal load balancers listen within a single region only.The table below breaks down the GKE load balancing solutions across these two dimensions.While these don’t cover every aspect of application networking, working through each of the factors above can help triangulate which solutions are best for your applications. Most GKE environments host many different types of applications, all with unique requirements, so it’s likely that you’ll be using more than one in any given cluster. For detailed information about their capabilities, check out some of the following resources:Ingress FeaturesMulti-Cluster Ingress (Ingress for Anthos)External IngressInternal IngressExternal LoadBalancer ServicesInternal LoadBalancer ServicesOther solutions for GKE application exposureThe Kubernetes ecosystem is vast, and the above solutions are not the only ones available for exposing applications. The solutions below may also be viable replacements or complements to the native GKE load balancers.In-cluster IngressIn-cluster Ingress refers to software Ingress controllers which have their Ingress proxies hosted inside the Kubernetes cluster itself. This is differentiated from Cloud Ingress controllers, which host and manage their load balancing infrastructure separately from the Kubernetes cluster. These third-party solutions are commonly self-deployed and self-managed by the cluster operator. istio-ingressgateway and nginx-ingress are two examples of commonly used and open source in-cluster Ingress controllers. The in-cluster Ingress controllers typically conform to the Kubernetes Ingress specification, and provide varying capabilities and ease of use. The open-source solutions are likely to require closer management and a higher level of technical expertise, but may suit your needs if they provide specific features your applications require. There is also a vast ecosystem of Enterprise Ingress solutions built around the open-source community which provide advanced features and enterprise support.Standalone NEGsGKE Ingress and Service controllers provide automated, declarative, and Kubernetes-native methods of deploying Google Cloud Load Balancing. There are also valid use cases for deploying load balancers manually for GKE backends, for example having direct and more granular control over the load balancer, or load balancing between container and VM backends. Standalone NEGs provide this ability by updating Pod backend IPs dynamically for a Network Endpoint Group (NEG), but allowing the frontend of the load balancer to be deployed manually through the Google Cloud API. This provides maximum and direct control of the load balancer while retaining dynamic backends controlled by the GKE cluster.Service meshService meshes provide client-side load balancing through a centralized control plane. While the Istio project introduced L7 service meshes to Kubernetes for internal communications, the service mesh ecosystem has rapidly expanded in scope and capabilities. Traffic Director and Anthos Service Mesh power the ability to load balance internal traffic across GKE clusters, across regions, and also between containers and VMs. This blurs the line between internal load balancing (east-west traffic) and application exposure (north-south traffic). With the flexibility and reach of modern service mesh control planes, it’s more likely than ever to have both the client and server within the same service mesh scope. The above GKE Ingress and Service solutions generally deploy middle-proxy load balancers for clients that do not have their own sidecar proxies. However, if a client and server are in the same mesh, then traditional application exposure can be handled via the mesh rather than middle-proxy load balancing.GKE at your serviceDepending on your use case, Google Cloud supports many different ways of exposing a GKE application as a service. We hope that it’s evident that GKE provides the most comprehensive support for all of your container use cases. If this blog post has helped you better understand how to architect application access, feel free to share it so that you can help others understand too.
Quelle: Google Cloud Platform