Russland: Ukrainische KI-fähige Drohnen greifen Ölraffinerien an
Um die russische Energiewirtschaft zu stören, soll die Ukraine KI-fähige Drohnen eingesetzt haben. So konnten russische Ölraffinerien angegriffen werden. (Drohne, KI)
Quelle: Golem

Um die russische Energiewirtschaft zu stören, soll die Ukraine KI-fähige Drohnen eingesetzt haben. So konnten russische Ölraffinerien angegriffen werden. (Drohne, KI)
Quelle: Golem

1&1 und Vodafone führen eine Wortschlacht bei Linkedin. 1&1 postet Stellenanzeigen neben Entlassungsmeldungen von Vodafone. “Billige HR-Maßnahme auf dem Schicksal von 2.000 Menschen”, entgegnet Vodafone. (Arbeit, Vodafone)
Quelle: Golem
Hi there! I’m Zander Rose and I’ve recently started at Automattic to work on long-term data preservation and the evolution of our 100-Year Plan. Previously, I directed The Long Now Foundation and have worked on long-term archival projects like The Rosetta Project, as well as advised/partnered with organizations such as The Internet Archive, Archmission Foundation, GitHub Archive, Permanent, and Stanford Digital Repository. More broadly, I see the content of the Internet, and the open web in particular, as an irreplaceable cultural resource that should be able to last into the deep future—and my main task is to make sure that happens.
I recently took a trip to one of Automattic’s data centers to get a peek at what “the cloud” really looks like. As I was telling my family about what I was doing, it was interesting to note their perception of “the cloud” as a completely ephemeral thing. In reality, the cloud has a massive physical and energy presence, even if most people don’t see it on a day-to-day basis.
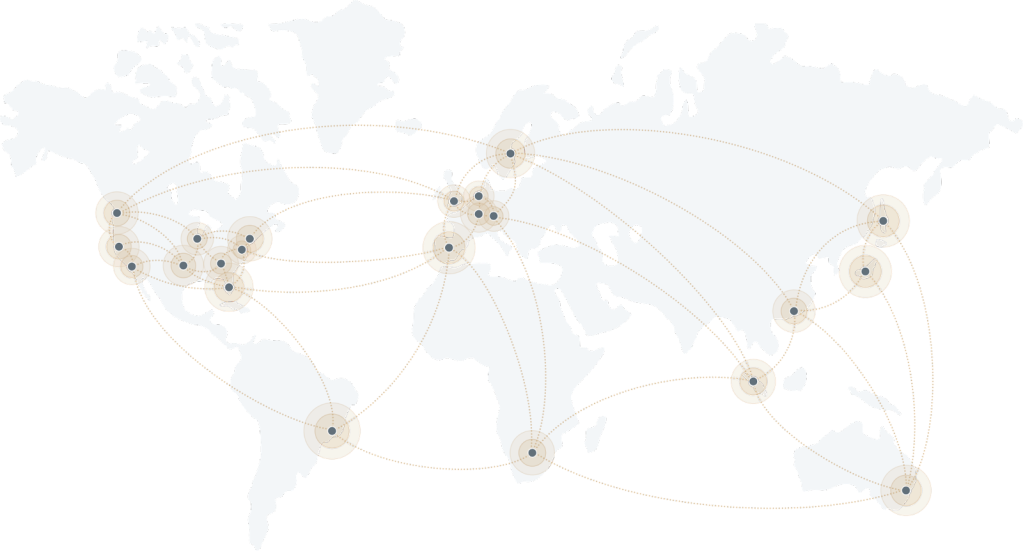
Automattic’s data center network. You can see a real-time traffic map right here.
A trip to the cloud
Given the millions of sites hosted by Automattic, figuring out how all that data is currently served and stored was one of the first elements I wanted to understand. I believe that the preservation of as many of these websites as possible will someday be seen as a massive historic and cultural benefit. For this reason, I was thankful to be included on a recent meetup for WordPres.com’s Explorers engineering team, which included a tour of one of Automattic’s data centers.
The tour began with a taco lunch where we met amazing Automatticians and data center hosts Barry and Eugene, from our world-class systems and operations team. These guys are data center ninjas and are deeply knowledgeable, humble, and clearly exactly who you would want caring about your data.
The data center we visited was built out in 2013 and was the first one in which Automattic owned and operated its servers and equipment, rather than farming it out. By building out our own infrastructure, it gives us full control over every bit of data that comes in and out, as well as reduces costs given the large amount of data stored and served. Automattic now has a worldwide network of 27 data centers that provide both proximity and redundancy of content to the users and the company itself.
The physical building we visited is run by a contracted provider, and after passing through many layers of security both inside and outside, we began the tour with the facility manager showing us the physical infrastructure. This building has multiple customers paying for server space, with Automattic being just one of them. They keep technical staff on site that can help with maintenance or updates to the equipment, but, in general, the preference is for Automattic’s staff to be the only ones who touch the equipment, both for cost and security purposes.
The four primary things any data center provider needs to guarantee are uninterruptible power, cooling, data connectivity, and physical security/fire protection. The customer, such as Automattic, sets up racks of servers in the building and is responsible for that equipment, including how it ties into the power, cooling, and internet. This report is thus organized in that order.
Power
On our drive in, we saw the large power substation positioned right on campus (which includes many data center buildings, not just Automattic’s). Barry pointed out this not only means there is a massive amount of power available to the campus, but it also gets electrical feeds from both the east and west power grids, making for redundant power even at the utility level coming into the buildings.
The data center’s massive generators.
One of the more unique things about this facility is that instead of battery-based instant backup power, it uses flywheel storage by Active Power. This is basically a series of refrigerator-sized boxes with 600-pound flywheels spinning at 10,000 RPM in a vacuum chamber on precision ceramic bearings. The flywheel acts as a motor most of the time, getting fed power from the network to keep it spinning. Then if the power fails, it switches to generator mode, pulling energy out of the flywheel to keep the power on for the 5-30 seconds it takes for the giant diesel generators outside to kick in.
Flywheel energy storage diagram.
Those generators are the size of semi-truck trailers and supply four megawatts each, fueled by 4,500-gallon diesel tanks. That may sound like a lot, but that basically gives them 48 hours of run time before needing more fuel. In the midst of a large disaster, there could be issues with road access and fuel shortages limiting the ability to refuel the generators, but in cases like that, our network of multiple data centers with redundant capabilities will still keep the data flowing.
Cooling
Depending on outside ambient temperatures, cooling is typically around 30% of the power consumption of a data center. The air chilling is done through a series of cooling units supplied by a system of saline water tanks out by the generators.
Barry and Eugene pointed out that without cooling, the equipment will very quickly (in less than an hour) try to lower their power consumption in response to the heat, causing a loss of performance. Barry also said that when they start dropping performance radically, it makes it more difficult to manage than if the equipment simply shut off. But if the cooling comes back soon enough, it allows for faster recovery than if hardware was fully shut off.
Handling the cooling in a data center is a complicated task, but this is one of the core responsibilities of the facility, which they handle very well and with a fair amount of redundancy.
Data connectivity
Data centers can vary in terms of how they connect to the internet. This center allows for multiple providers to come into a main point of entry for the building.
Automattic brings in at least two providers to create redundancy, so every piece of equipment should be able to get power and internet from two or more sources at all times. This connectivity comes into Automattic’s equipment over fiber via overhead raceways that are separate from the power and cooling in the floor. From there it goes into two routers, each connected to all the cabinets in that row.
Server area
As mentioned earlier, this data center is shared among several tenants. This means that each one sets up their own last line of physical security. Some lease an entire data hall to themselves, or use a cage around their equipment; some take it even further by obscuring the equipment so you cannot see it, as well as extending the cage through the subfloor another three feet down so that no one could get in by crawling through that space.
Automattic’s machines took up the central portion of the data hall we were in, with some room to grow. We started this portion of the tour in the “office” that Automattic also rents to both store spare parts and equipment, as well as provide a quiet place to work. On this tour it became apparent that working in the actual server rooms is far from ideal. With all the fans and cooling, the rooms are both loud and cold, so in general you want to do as much work outside of there as possible.
What was also interesting about this space is that it showed all the generations of equipment and hard drives that have to be kept up simultaneously. It is not practical to assume that a given generation of hard drives or even connection cables will be available for more than a few years. In general, the plan is to keep all hardware using identical memory, drives, and cables, but that is not always possible. As we saw in the server racks, there is equipment still running from 2013, but these will likely have to be completely swapped in the near future.
Barry also pointed out that different drive tech is used for different types of data. Images are stored on spinning hard drives (which are the cheapest by size, but have moving parts so need more replacement), and the longer lasting solid state disk (SSD) and non-volatile memory (NVMe) technology are used for other roles like caching and databases, where speed and performance are most important.
Barry showing us all the bins of hardware they use to maintain the servers.
Barry explained that data at Automattic is stored in multiple places in the same data center, and redundantly again at several other data centers. Even with that much redundancy, a further copy is stored on an outside backup. Each one of the centers Automattic uses has a method of separation, so it is difficult for a single bug to propagate between different facilities. In the last decade, there’s only been one instance where the outside backup had to come into play, and it was for six images. Still, Barry noted that there can never be too many backups.
An infrastructure for the future
And with that, we concluded the tour and I would soon head off to the airport to fly home. The last question Barry asked me was if I thought this would all be around in 100 years. My answer was that something like it most certainly will, but that it would look radically different, and may be situated in parts of the world with more sustainable cooling and energy, as more of the world gets large bandwidth connections.
As I thought about the project of getting all this data to last into the deep future, I was very impressed by what Automattic has built, and believe that as long as business continues as normal, the data is incredibly safe. However, on the chance that things do change, I think developing partnerships with organizations like The Internet Archive, Permanent.org, and perhaps national libraries or large universities will be critically important to help make sure the content of the open web survives well into the future. We could also look at some of the long-term storage systems that store data without the need for power, as well as systems that cannot be changed in the future (as we wonder if AI and censorship may alter what we know to be “facts”). For this, we could look at stable optical systems like Piql, Project Silica, and Stampertech. It breaks my heart to think the world would have created all this, only for it to be lost. I think we owe it to the future to make sure as much of it as possible has a path to survive.
Our group of Automatticians enjoyed the tour—thank you Barry and Eugene!
Quelle: RedHat Stack

Vor über 25 Jahren hat Intel erstmals eine Grafikkarte auf den Markt gebracht. Wir testen, warum Intel damals nicht erfolgreich war. Von Martin Böckmann (Grafikkarten, Intel)
Quelle: Golem

Der deutsche Anbieter soll eine private Cloud mit dem ITZBund betreiben – und erhält dafür den Zuschlag einer Millionen-Ausschreibung. (Strato, Datenschutz)
Quelle: Golem

Apple soll eine Maschine entwickelt haben, um iPhones in der verschweißten Originalverpackung aktualisieren zu können. Nun gibt es ein erstes Foto. (iPhone, Smartphone)
Quelle: Golem

Einige der Apollo-Daten der Nasa sind fast verloren gegangen. Eine neue Datenanalyse zeigt, dass der Mond fast dreimal mehr Beben hat, als bisher angenommen wurde. (Mond, Nasa)
Quelle: Golem

Wie eine freie Befehlssatz-Architektur fast unbemerkt in unseren Alltag einzieht, besprechen wir im Podcast. (Besser Wissen, Intel)
Quelle: Golem

I have been recently watching The Americans, a decade-old TV series about undercover KGB agents living disguised as a normal American family in Reagan’s America in a paranoid period of the Cold War. I was not expecting this weekend to be reading mailing list posts of the same type of operation being performed on open source maintainers by agents with equally shadowy identities (CVE-2024-3094).
As The Grugq explains, “The JK-persona hounds Lasse (the maintainer) over multiple threads for many months. Fortunately for Lasse, his new friend and star developer is there, and even more fortunately, Jia Tan has the time available to help out with maintenance tasks. What luck! This is exactly the style of operation a HUMINT organization will run to get an agent in place. They will position someone and then create a crisis for the target, one which the agent is able to solve.”
The operation played out over two years, getting the agent in place, setting up the infrastructure for the attack, hiding it from various tools, and then rushing to get it into Linux distributions before some recent changes in systemd were shipped that would have stopped this attack from working.
An equally unlikely accident resulted when Andres Freund, a Postgres maintainer, discovered the attack before it had reached the vast majority of systems, from a probably accidental performance slowdown. Andres says, “I didn’t even notice it while logging in with SSH or such. I was doing some micro-benchmarking at the time and was looking to quiesce the system to reduce noise. Saw sshd processes were using a surprising amount of CPU, despite immediately failing because of wrong usernames etc. Profiled sshd. Which showed lots of cpu time in code with perf unable to attribute it to a symbol, with the dso showing as liblzma. Got suspicious. Then I recalled that I had seen an odd valgrind complaint in my automated testing of Postgres, a few weeks earlier, after some package updates were installed. Really required a lot of coincidences.”
It is hard to overstate how lucky we were here, as there are no tools that will detect this vulnerability. Even ex-post it is not possible to detect externally as we do not have the private key needed to trigger the vulnerability, and the code is very well hidden. While Linus’s law has been stated as “given enough eyeballs all bugs are shallow,” we have seen in the past this is not always true, or there are just not enough eyeballs looking at all the code we consume, even if this time it worked.
In terms of immediate actions, the attack appears to have been targeted at subset of OpenSSH servers patched to integrate with systemd. Running SSH servers in containers is rare, and the initial priority should be container hosts, although as the issue was caught early it is likely that few people updated. There is a stream of fixes to liblzma, the xz compression library where the exploit was placed, as the commits from the last two years are examined, although at present there is no evidence that there are exploits for any software other than OpenSSH included. In the Docker Scout web interface you can search for “lzma” in package names, and issues will be flagged in the “high profile vulnerabilities” policy.
So many commentators have simple technical solutions, and so many vendors are using this to push their tools. As a technical community, we want there to be technical solutions to problems like this. Vendors want to sell their products after events like this, even though none even detected it. Rewrite it in Rust, shoot autotools, stop using GitHub tarballs, and checked-in artifacts, the list goes on. These are not bad things to do, and there is no doubt that understandability and clarity are valuable for security, although we often will trade them off for performance. It is the case that m4 and autotools are pretty hard to read and understand, while tools like ifunc allow dynamic dispatch even in a mostly static ecosystem. Large investments in the ecosystem to fix these issues would be worthwhile, but we know that attackers would simply find new vectors and weird machines. Equally, there are many naive suggestions about the people, as if having an identity for open source developers would solve a problem, when there are very genuine people who wish to stay private while state actors can easily find fake identities, or “just say no” to untrusted people. Beware of people bringing easy solutions, there are so many in this hot-take world.
Where can we go from here? Awareness and observability first. Hyper awareness even, as we see in this case small clues matter. Don’t focus on the exact details of this attack, which will be different next time, but think more generally. Start by understanding your organization’s software consumption, supply chain, and critical points. Ask what you should be funding to make it different. Then build in resilience. Defense in depth, and diversity — not a monoculture. OpenSSH will always be a target because it is so widespread, and the OpenBSD developers are doing great work and the target was upstream of them because of this. But we need a diverse ecosystem with multiple strong solutions, and as an organization you need second suppliers for critical software. The third critical piece of security in this era is recoverability. Planning for the scenario in which the worst case has happened and understanding the outcomes and recovery process is everyone’s homework now, and making sure you are prepared with tabletop exercises around zero days.
This is an opportunity for all of us to continue working together to strengthen the open source supply chain, and to work on resilience for when this happens next. We encourage dialogue and discussion on this within Docker communities.
Learn more
Docker Scout dashboard: https://scout.docker.com/vulnerabilities/id/CVE-2024-3094
NIST CVE: https://nvd.nist.gov/vuln/detail/CVE-2024-3094
Quelle: https://blog.docker.com/feed/
Amazon WorkMail unterstützt jetzt die Prüfungsprotokollierung, mit der Sie Einblicke in Postfachzugriffsmuster erhalten. Mithilfe von der Prüfungsprotokollierung können Sie wählen, ob Sie Authentifizierungs-, Zugriffskontroll- und Postfachzugriffsprotokolle auf Amazon CloudWatch Logs, Amazon S3 und Amazon Data Firehose empfangen möchten. Außerdem erhalten Sie in CloudWatch neue Postfach-Metriken über Ihre WorkMail-Organisationen.
Quelle: aws.amazon.com