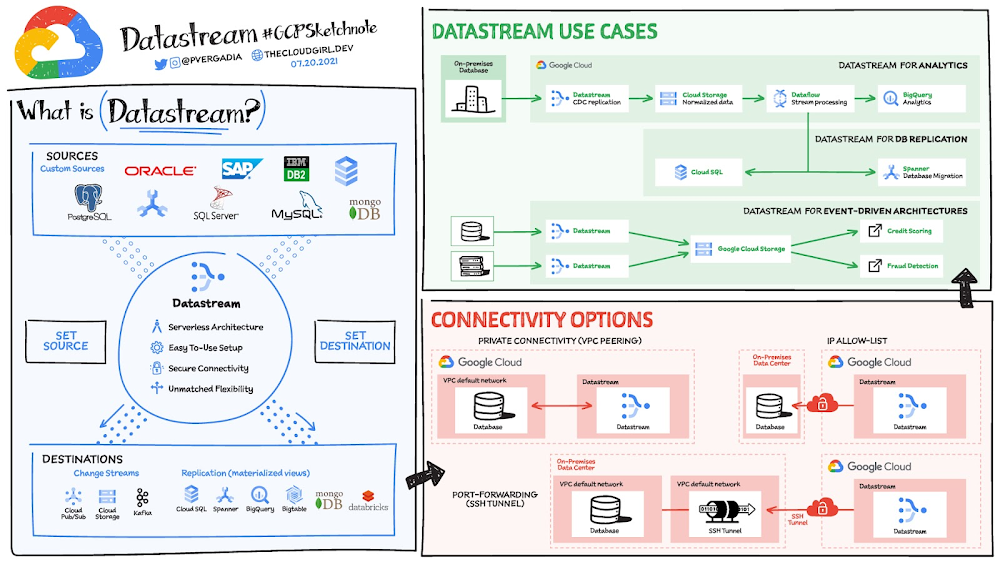
Compliance Engineering – From manual attestation to continuous compliance
Risk Management and Compliance is as important in the cloud as it is in conventional on-premises environments. To help organizations in regulated industries meet their compliance requirements, Google Cloud offers automated capabilities that ensure the effectiveness of productionalization processes. Continuous compliance in the banking industryBanks have a formidable responsibility in managing the world’s wealth, and are therefore champions in diligently managing risk. Financial regulators in turn publish banking regulations to ensure banks assess and manage their risks accurately. Since banks are heavily reliant on information technology (IT), these regulations also cover the use of IT within banks.Regulated industries typically have an extended governance framework to ensure their deployed IT assets comply with the regulations, have a managed security posture and meet corporate risk appetites. Before a new application can be deployed in production, IT application owners typically look at a historical duration of several months to complete the necessary regulatory evidence. Control questions are typically based on the architectures of conventional on-premises technologies, and often lack relevance to cloud-specific technologies and hence do not benefit from using cloud automation capabilities. For example, current IT models within many banks are built to have only a few changes per month, whereas the cloud is capable of rolling out hundreds of changes every day. Let’s hear from one of the top regulated financial institutions what their challenges were before starting the transformation:“It was not just some of the significantly different technologies we’d be operating on and within, it was the foundational approach of having strong controls and control solutions embedded within the cloud platform. The changes in operating model from adopting Google Cloud made it evident to us that we’d need to revisit each and every control within our current control set.”—Bill Walker – Head of Operational Readiness at Deutsche BankThe following sections will help chief security and compliance officers assess their current estate and start the transformation of their IT-related risks with a set of key recommendations. Transforming processes from On-Premises to CloudThe objectives behind existing controls may still be relevant, however the definition and attestation often need to evolve to accurately address the operational risk. The strict control environment in combination with the ability for speed and go-to-market emphasizes the importance of effective controls and automated attestation in a cloud-based environment. For a broader digital transformation in regulated environments please refer to the Google Cloud whitepaper “Risk Governance of Digital Transformation in the Cloud”.Before we deep dive into the topic, let’s define some terms in this context. A control in its core helps to manage different types of risks. Security controls focus on addressing the risk of lapses of confidentiality, integrity and availability of information. Compliance controls focus on addressing the risk of failure to act in accordance with industry laws, regulations and internal policies. The fulfilment of a control is often reached by evidencing one or multiple underlying control questions. Group the controlsThe highly integrated services of the cloud allow the application owner to focus on the application relevant controls, while underlying platform services should be already evidenced centrally for the entire workload landscape. The following proposed grouping of controls will result in a reduction of controls every single workload has to evidence. Control owners and engineering teams can focus on the group of controls within their specialization, in other words the corresponding application engineers may not need to have full awareness of the implementation on the platform layer.The group of enterprise-wide controls are part of a vendor risk assessment assessing the cloud provider and cloud services. The evidence for these controls is not influenced by how the services would be configured or used within the corporation. A practical example is the provider’s employee on- and off-boarding process.The group of platform-wide controls are automatically enforced in each workload running on top of this landing zone. Practical examples are audit logging (on Org and Folder level), privileged user access management (PUAM) or encryption type used for data at rest. The use of Organization Policies allow the definition of configurations across the whole GCP resource hierarchy. The group of workload specific controls are evidenced on application level and focus on the custom application architecture. The evidenced configurations are specific to the deployed application and can include the used authentication providers, user access management and disaster recovery setup. In large landscapes an additional group of workload class would allow for clustering application specific controls by commonalities like processed data confidentiality or internet facing networks.Figure 1 – Grouping of controlsThe grouping helps to place the automation in the right stage of the productionalization. Enterprise wide controls are often only assessed once, so there is no big return on investing in automation. Platform wide controls should be automated in the Security Posture Management system allowing for continuous and close to real-time compliance auditing across all applications. Workload or Workload class specific controls should find their automation as part of the Continuous Integration / Continuous Deployment (CICD) pipeline. Assess cloud adequacyCloud offers many capabilities to make IT more secure, however many companies see their Cloud adoption as an opportunity to address technical debt and decrease risk posture in one go. Moving workloads to the Cloud influences the types of risks which need to be managed but should not lead to a less secure environment. Therefore it is key to review the existing controls and control questions to be effective.Let me illustrate this in a practical example where an existing on-prem control would check for a manual or automated procedure to deploy an application release including roll-back section for the failure case. Infrastructure as Code automates the end-to-end deployment and roll-back of an application, this means a Terraform script should be sufficient to evidence this control. Another example in the same area would be the governance around production access for engineers (i.e. approval process, managing lists who has access) will change significantly when human access to production infrastructure is by exception only.In short the controls and control questions have to be assessed to be:Effective – Control accurately evidences the cloud environmentAdjustment required – Control is relevant but has to be adapted to reflect cloud technologyObsolete – Control is not effective for assessing the cloud environment, can be deprecatedPublicly available cloud control frameworks form a solid base to incorporate into your specific controls and assessing for cloud adequacy. Furthermore possible gaps in your control framework can be identified and new adequate cloud native controls being introduced. Move more ops into devThe transformation of the productionalization process is not only about technology and compliance frameworks but also about people. People who have been maintaining and strengthening the current process for a long time. The control owners ultimately responsible for their control area may not be fully versed in the new Cloud technology, therefore they might naturally be a little sceptical. The transformation stands and falls with their involvement.Make the control owners get confident with the technologies by allocating education time, make them part of the design and engineering process from the very beginning and turn them into advocates for the cloud transformation in their respective organization. This recommendation follows the Site Reliability Engineering practice to make operations part of the development team. The benefit is that control owners can get confident in the technology and are sure their control is properly assessed. As the controls stem from different organizations (Security, Business Continuity, Regulations, etc.) they in turn will advocate for the control change in their respective organization.Have traceability of the controls and clear pass/fail criteriaClear traceability of the control questions to controls, to policies and to regulations help to clean up interpretations and enable large-scale automation.This one may sound obvious, however productionalization processes have grown over the years and sometimes it’s not entirely clear what risk shall be assessed and how the provided evidence is being used. In order to allow the application owners to move to production as quickly as possible it’s inevitable that controls are automated. Automation is only possible with clear pass/fail criteria without any aspect of interpretation. Controls which existed due to historical reasons without any clear traceability can be filtered and potentially missing controls can be identified.Banks excel at managing their risk as they have the great responsibility in managing the world’s wealth. With their digital transformation into the cloud, banks are facing the challenge to adapt their existing controls processes and automate the attestation. The control has to be understood, made effective for the new IT delivery paradigm, automated to accelerate the migration and moved to a continuous compliance model. Subsequent articles in this series will explore the concrete automation case studies and show how “infrastructure as code” and “compliance as code” allow regulatory audits to move from a cyclical assessment to continuous posture management during the entire lifetime of an IT asset.Related ArticleNew Paper: Assuring Compliance in the CloudToday we are releasing the new paper by the Office of the CISO of Google Cloud. In the paper we reveal a new approach for modernizing you…Read Article
Quelle: Google Cloud Platform