TIM Group chooses Cloud SQL over Oracle to power its billing apps
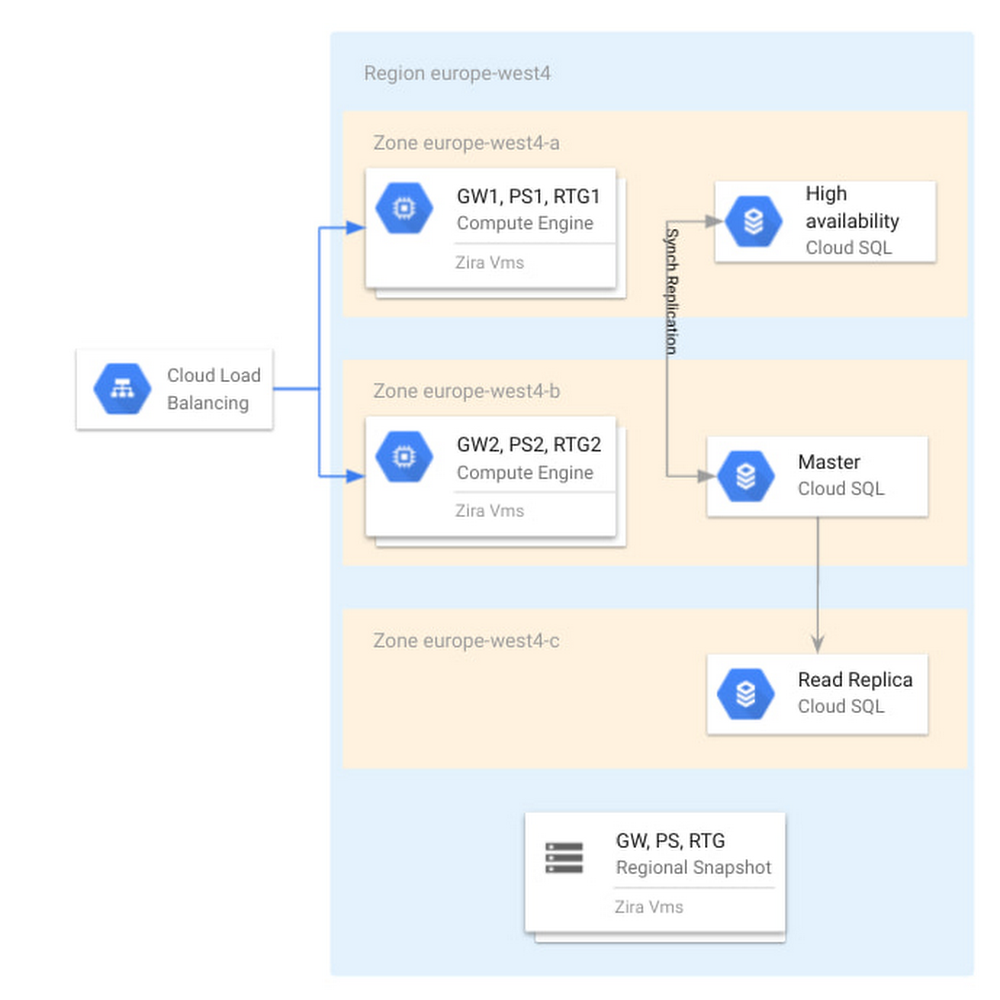
Editor’s note: In this blog, we look at how TIM Group, a leading information and communication technology (ICT) company in Italy and Brazil, used Cloud SQL for PostgreSQL to deliver a new billing application and saw 45% savings in database maintenance and infrastructure costs.In early 2020, TIM Group set out to solve a common challenge faced by large enterprises in order to keep up with competitive trends and new technological developments. One of our core IT systems, our billing function, was in need of a modernization overhaul and so we began a digital transformation project to build a new billing system on Google Cloud powered by Cloud SQL for PostgreSQL and Google Compute Engine. The new system was designed to automate important billing and credit systems that had been previously processed manually, and has already resulted in a 45% cost savings in database management, and a 20% savings in infrastructure costs. Designing a new digital journey My team is responsible for the development and maintenance of new billing systems for wholesale network access services. We began building a new system in 2020 that would modernize the way we bill for our B2B services with other telecom operators in the wholesale market, which in terms of revenue is an enormous market segment for TIM Group. The new billing system will help us to automate the formerly manual business processes for billing and credit management, and will eventually allow our IT department to decommission 16 legacy on-premise systems. Some of these legacy systems are 20 years old and no longer supported by the application stack. They suffer from poor performance, storage scalability limitations, low availability, and a lack of disaster recovery capabilities. In addition, they incur huge maintenance costs across applications and infrastructure levels, and they have no support for future use cases or innovation. Benchmarking Cloud SQL for a new billing systemWe initially started this project with a different planned architecture than the one we ended up building. At the outset, we had a blueprint architecture based on an Oracle database, and we acquired a license of a billing product called Wholesale Business Revenue Management (WBRM) from Zira to configure and customize as a base for our new billing system, compatible with both Oracle and PostgreSQL databases. Ultimately, we were designing a solution to run in our data centers based on VMware and Oracle, and a couple of months into the project we signed the partnership with Google Cloud. This decision opened up the possibility of running solutions on a modern cloud environment. We were excited by many of the capabilities we saw in Google Cloud’s solutions, including Cloud SQL, their fully managed relational database service for running MySQL, PostgreSQL and SQL Server. We tested the performance of Cloud SQL for PostgreSQL to see if it was comparable with the benchmark that Zira gave us for running WBRM on Oracle.The results were excellent; Cloud SQL for PostgreSQL met the Oracle database benchmark that Zira had given us based on previous stress tests. Using a database like Postgres would allow us to save on licensing costs and the contracting process with Oracle. To conduct these tests, we wanted to compare Oracle RAC against Cloud SQL for PostgreSQL, and look at which performed better in terms of application performance, scalability and ease of maintenance. We started with vertical scalability. We incremented the virtual CPUs and RAM by 20% and got a proportional benefit in throughput. We then tested horizontally scaled read workload and found that we had the same performance in user interface response time when linked to a read replica of a Cloud SQL for PostgreSQL database. We tested availability by switching down a node on the database, and found that all services were redirected to the follower node of the database with zero downtime. We were satisfied and encouraged by the results of these tests, and proceeded to build our new billing system with WBRM and Cloud SQL for PostgreSQL.Cutting database maintenance costs by up to 45%The managed services of Cloud SQL for PostgreSQL have given us considerable operational benefits. We were relying on external suppliers to handle most of our database maintenance, including updates, patching, security, and more administrative tasks. We saw 45% savings in eliminating that cost, and an additional 20% savings in infrastructure costs, which is a conservative estimate since we’re still in the process of fully rolling out the new system. We expect even bigger savings by the end of the project, which will hopefully go fully live at the end of 2021. Our project strategy has been to implement the new system in increments, replacing one service at a time. We started with services that weren’t supported by our legacy system, which included manual billing and credit processes that previously required 20-30 team members to maintain. As our year continues, we will continue work to dismiss legacy systems and to feed the new system with traffic usage, where we expect a huge ramp up of volume. Peeking under the hoodOur cloud instances are located primarily in the Netherlands region, with virtual machines in zones a and b for high availability. We have a highly available Cloud SQL instance across those zones. In zone c, we also have a read replica that we use to offload workloads from the primary that require read access only. For example, some departments have revenue assurance systems that connect to this read replica to check on orders billed or any revenue problems. On-premises, adding a new read replica server to the database can take two to three months, as it requires hardware allocation, tickets etc. In the cloud we can set up a read replica in a matter of minutes.For disaster recovery purposes, we make a daily backup with a 14 day retention period, and we have another operations team that is in charge of taking snapshots of our Zira VMs.Below, you can see our high level architecture. The application itself is hosted on Compute Engine and can be accessed through a load balancer. You can also see Cloud SQL and the read replicas in every zone and region mentioned above.Cloud SQL as part of the Zira WBRM architecture at TIM GroupTwo of our requirements were to direct some of the read traffic to the read replica and also to pool connections together. To meet those requirements, we have deployed PgBouncer which takes care of diverting the traffic and pgpool that takes care of connection pooling in front of Cloud SQL, as you can see in the diagram below.With Cloud SQL powering our new billing system, we can now automate previous manual billing and credit processing, dismiss over a dozen legacy systems, and build upon technology that provides high performance, easy storage scalability, high availability, and disaster recovery. And this is all at significant cost savings in database maintenance and infrastructure. In addition, we now have a database solution that integrates easily with other services like WBRM, and will empower TIM Group to innovate for use cases on our roadmap and beyond.Read more about TIM Group, Cloud SQL for PostgreSQL and Wholesale Business Revenue Management (WBRM) from Zira.Related ArticleIntroducing cross-region replica for Cloud SQLCross-region replication from Cloud SQL lets you ensure business continuity across Google Cloud regions in case of an outage or failure.Read Article
Quelle: Google Cloud Platform