Modernizing your serverless applications
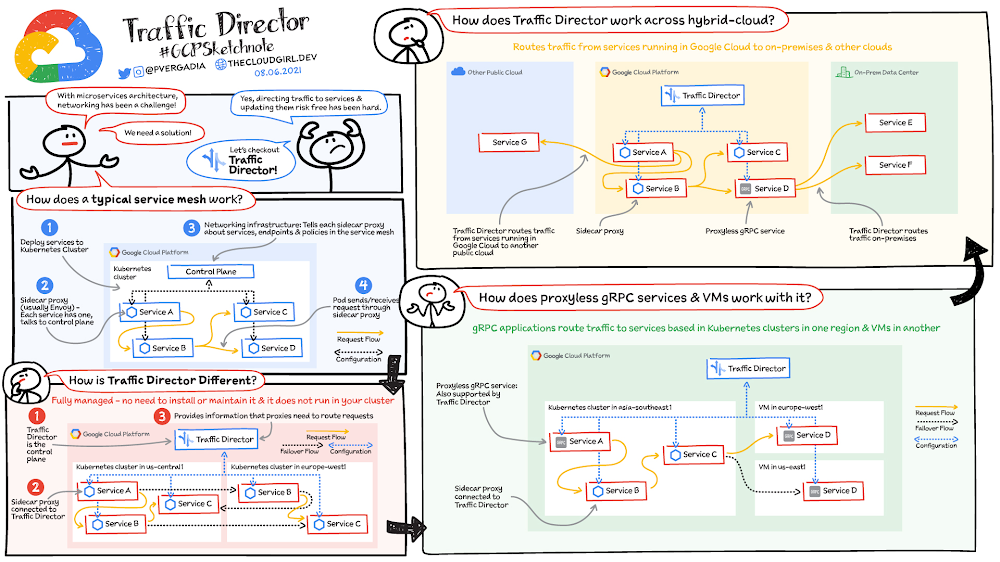
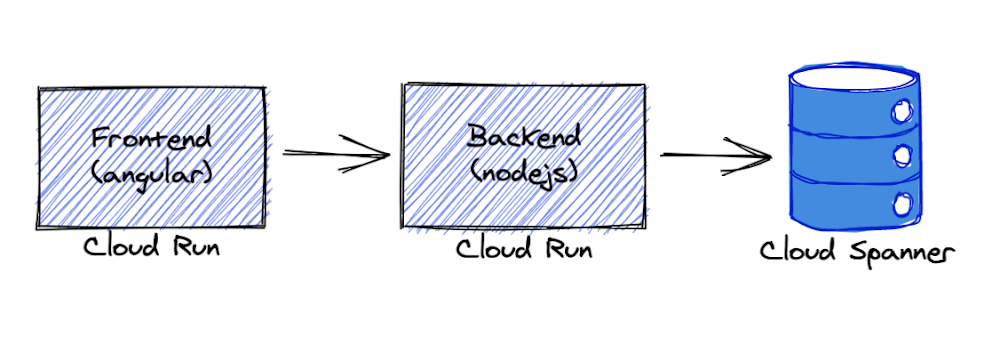
Continuing innovation in serverlessGoogle Cloud recently released a suite of resources designed to help customers modernize their serverless compute platform experience and upgrade to the latest features as well as newer products which may be a better fit for their workloads. The initial content is focused on users of the very first Cloud product, Google App Engine.App Engine launched in 2008 as the first serverless product long before the buzzword was coined. Since then, App Engine has been adopted by many customers worldwide. The Cloud team didn’t stop there and continued to roll out additional features and product launches, including: App Engine’s Flexible environment to support additional runtimes (2016), Cloud Functions, for microservice or FaaS/function-hosting (2017), a more open second generation App Engine platform supporting newer language releases (2018), and Cloud Run, giving users the ability to serve containerized applications in a serverless environment (2019). With a more complete product suite and a more open platform, developers have more choices than ever before.As App Engine became more popular, many of its original services matured to become their own standalone Cloud products. For example, App Engine’s original Task Queues service is now Cloud Tasks, and its original Datastore service is now Cloud Datastore. Furthermore, some users have expressed the desire to also run their App Engine apps on-premise but discovered the App Engine services only work on the platform. These factors led to the launch of App Engine’s second generation platform without those bundled proprietary services. As a result, users have more options, and their apps are more portable. Support for more modern language runtimes such as Python 3, PHP 7, and the introduction of Node.js was also featured as part of this release.Helping users modernize their serverless appsWith the sunset of Python 2, Java 8, PHP 5, and Go 1.11, by their respective communities, Google Cloud has assured users by expressing continued long-term support of these legacy runtimes, including maintaining the Python 2 runtime. So while there is no requirement for users to migrate, developers themselves are expressing interest in updating their applications to the latest language releases.Google Cloud provides a set of migration guides for users modernizing from Python 2 to 3, Java 8 to 11, PHP 5 to 7, and Go 1.11 to 1.12+ as well as a summary of what is available in both first and second generation runtimes. However, moving to unbundled services (standalone Cloud equivalents or third-party alternatives) may not be intuitive to everyone. And while new products and users are great, helping existing users modernize their apps to take advantage of newer features is just as good. To that end, earlier this year, we launched the “Serverless Migration Station” video series and corresponding code samples and codelab tutorials, initially focused on Python and App Engine.Migration modulesEach “migration module” teaches a single modernization technique, usually as it relates to one of our serverless platforms. These scenarios include migrating from a legacy App Engine service, upgrading a serverless data storage solution from Cloud Datastore to Cloud Firestore, or even changing products altogether, like containerizing App Engine apps for Cloud Run.A video plus a codelab (free, self-paced tutorial) provide with hands-on experience implementing specific migrations, giving users the “muscle memory” needed for when they’re ready to make the same upgrades to their own applications. All modules feature a nearly-identical sample app. The starting point is always a working app to which the migration is applied, resulting in another working app, usually functionally-identical unless otherwise specified. Here are some modules available today (with more coming soon):Migrating web frameworks from webapp2 to FlaskMigrating from App Engine ndb to Cloud NDBMigrating from the Cloud NDB to Cloud DatastoreContainerizing and migrating from App Engine to Cloud Run (Docker)Containerizing and migrating from App Engine to Cloud Run (Cloud Buildpacks)Migrating from Cloud Datastore to Cloud FirestoreMigrating from App Engine taskqueue to Cloud TasksAll migration modules, their videos (when available), codelabs, and sample source code, can be found in the migration module repo. In addition to these modules, separate repos for migration samples from the documentation as well as community-sourced migration samples are also available. We hope these resources help you accelerate modernizing your serverless apps and demonstrates Google Cloud’s commitment to both existing customers as well as new ones!Related ArticleNew features to better secure your Google App Engine appsAnnouncing new features to further extend the security already provided by App Engine: Egress Controls and User-managed service accounts.Read Article
Quelle: Google Cloud Platform