Push configuration with zero downtime using Cloud Pub/Sub and Spring Framework
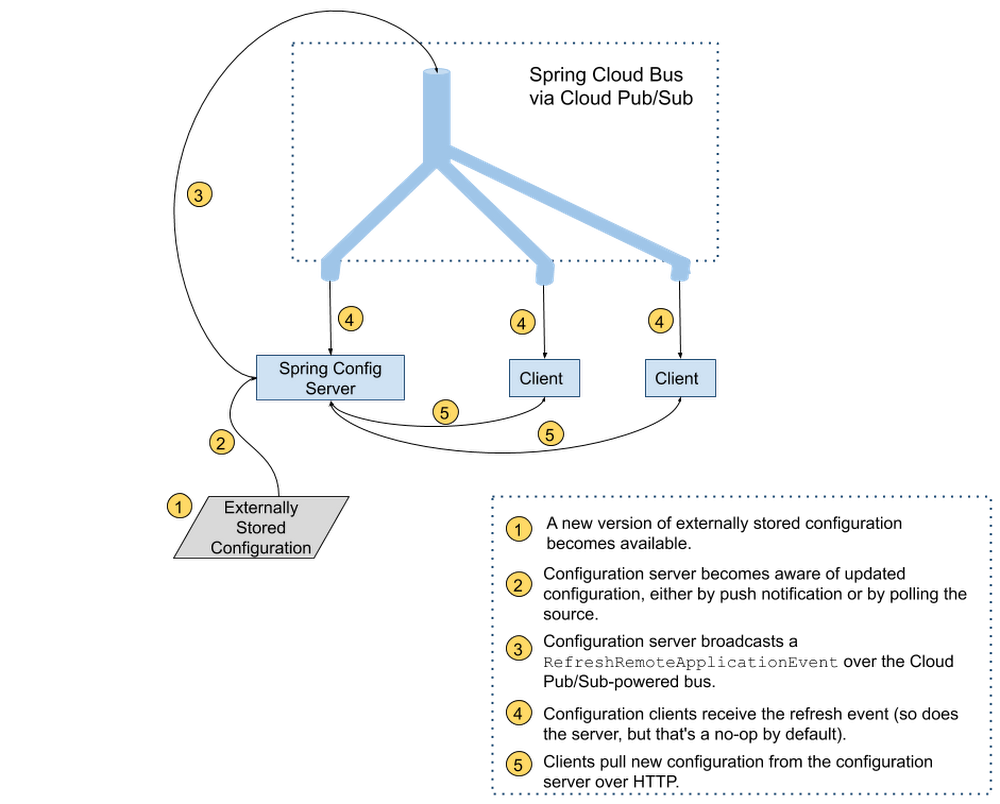
As application configuration grows more complex, treating it with the same care we treat code—applying best practices for code review, and rolling it out gradually—makes for more stable, predictable application behavior. But deploying application configuration together with the application code takes away a lot of the flexibility that having separate configuration offers in the first place. Compared with application code, configuration data has different:Granularity – per server or per region, rather than (unsurprisingly) per application.Lifecycle – more frequent if you don’t deploy your application very often; less frequent, perhaps, if you embrace continuous deployment for code.This leads us to an important best practice for software development teams: separating code from configuration when deploying applications. More recently, DevOps teams have started to practice “configuration as code”—storing configuration in version-tracked repositories. But if you update your configuration data separately, how will your code learn about it and use it? It’s possible, of course, to push new settings and restart all application instances to pick up the updates, but that could result in unnecessary downtime.If you’re a Java developer and use the Spring Framework, there’s good news. Spring Cloud Config lets applications monitor a variety of sources (source control, database etc.) for configuration changes. It then notifies all subscriber applications that changes are available using Spring Cloud Bus and the messaging technology of your choice. If you’re running on Google Cloud, one great messaging option is Cloud Pub/Sub. In the remainder of this blog post, you’ll learn how to configure Spring Cloud Config and Spring Cloud Bus with Cloud Pub/Sub, so you can enjoy the benefits of configuration maintained as code and propagated to environments automatically.Setting up the server and the clientImagine you want to store your application configuration data in a GitHub repository. You’ll need to set up a dedicated configuration server (to monitor and fetch configuration data from its true source), as well as a configuration client embedded in the application that contains your business logic. In a real world scenario, you’d have many business applications or microservices, each of which has an embedded configuration client talking to the server and retrieving the latest configuration from it. You can find the full source code for all the examples in this post in this Spring Cloud GCP sample app.Configuration server setupTo take advantage of the power of distributed configuration, it’s common to set up a dedicated configuration server. You configure a GitHub webhook to notify it whenever there are changes, and the configuration server, in turn, notifies all the interested applications that run the business logic that new configuration is available to be picked up.The configuration server has the following three dependencies (we recommend using the Spring Cloud GCP Bill Of Materials for setting up dependency versions):pom.xmlThe first dependency, spring-cloud-gcp-starter-bus-pubsub, ensures that Cloud Pub/Sub is the Spring Cloud Bus implementation that powers all the messaging functionality.The other two dependencies make this application act as a Spring Cloud Config server capable of being notified of changes by the configuration source (Github) on the /monitor HTTP endpoint it sets up.The config server application also needs to be told where to find the updated configuration; we use a standard Spring application properties file to point it to the GitHub repository containing the configuration:application.propertiesYou’ll need to customize the port if you are running the example locally. Like all Spring Boot applications, the configuration server normally runs on port 8080 by default, but that port is used by the business application we are about to configure, so an override is needed.The last piece you need to run a configuration server is the Java code!PubSubConfigGitHubServerApplication.javaAs is typical for Spring Boot applications, the boilerplate code is minimal—all the functionality is driven by a single annotation, @EnableConfigServer. This annotation, combined with the dependencies and configuration, gives you a fully functional configuration server capable of being notified when a new configuration arrives by way of the /monitor endpoint. Then, in turn, the configuration server notifies all the client applications through a Cloud Pub/Sub topic.Speaking of the Cloud Pub/Sub topic, if you run just the server application, you’ll notice in the Google Cloud Console that a topic named springCloudBus was created for you automatically, along with a single anonymous subscription (a bit of trivia: every configuration server is capable of receiving the configuration it broadcasts, but configuration updates are suppressed on the server by default).Configuration client setupNow that you have a configuration server, you’re ready to create an application that subscribes to that server’s vast (well… not that vast) knowledge of configuration.The client application dependencies are as follows:pom.xmlThe client needs a dependency on spring-cloud-gcp-starter-bus-pubsub, just as the server did. This dependency enables the client application to subscribe to configuration change notifications arriving over Cloud Pub/Sub. The notifications do not contain the configuration changes; the client applications will pull those over HTTP.Notice that the client application only has one Spring Cloud Config dependency: spring-cloud-config-client. This application doesn’t need to know how the server finds out about configuration changes, hence the simple dependency.For this demo, we made a web application, but client applications can be any type of application that you need. They don’t even need to be Java applications, as long as they know how to subscribe to a Cloud Pub/Sub topic and retrieve content from an HTTP endpoint!Nor do you need any special application configuration for a client application. By default, all configuration clients look for a configuration server on local port 8888 and subscribe to a topic named springCloudBus. To customize the configuration server location for a real-world deployment, simply configure the spring.cloud.config.uri property in the bootstrap.properties file, which is read before the regular application initialization. To customize the topic name, add the spring.cloud.bus.destination property to the regular application.properties file, making sure that the config server and all client applications have the same value.And now, it’s time to add the client application’s code:PubSubConfigApplication.javaExampleController.javaAgain, the boilerplate here is minimal—PubSubConfigApplication starts up a Spring Boot application, and ExampleController sets up a single HTTP endpoint /message. If no configuration server is available, the endpoint serves the default message of “none”. If a configuration server is found on the default localhost:8888 URL, the configuration found there at client startup time will be served. The @RefreshScope annotation ensures that the message property gets a new value whenever a configuration refresh event is received.The code is now complete! You can use the mvn spring-boot:run command to start up the config server and client in different terminals and try it out. To test that configuration changes propagate from GitHub to the client application, update configuration in your GitHub repository, and then manually invoke the /monitor endpoint of your config server (you would configure this to be done automatically through a GitHub webhook for a deployed config server):After running the above command, the /message endpoint serves the most recent value retrieved from GitHub.And that’s all that’s required for a basic Spring Cloud Config with Cloud Pub/Sub-enabled bus server/client combination. In the real world, you’ll most likely serve different configurations to different environments (dev, QA etc.). Because Spring Cloud Config supports hierarchical representation of configuration, it can grow to adapt to any environment setup.For more information, visit the Spring Cloud GCP documentation and sample.
Quelle: Google Cloud Platform



