GKE best practices: Day 2 operations for business continuity
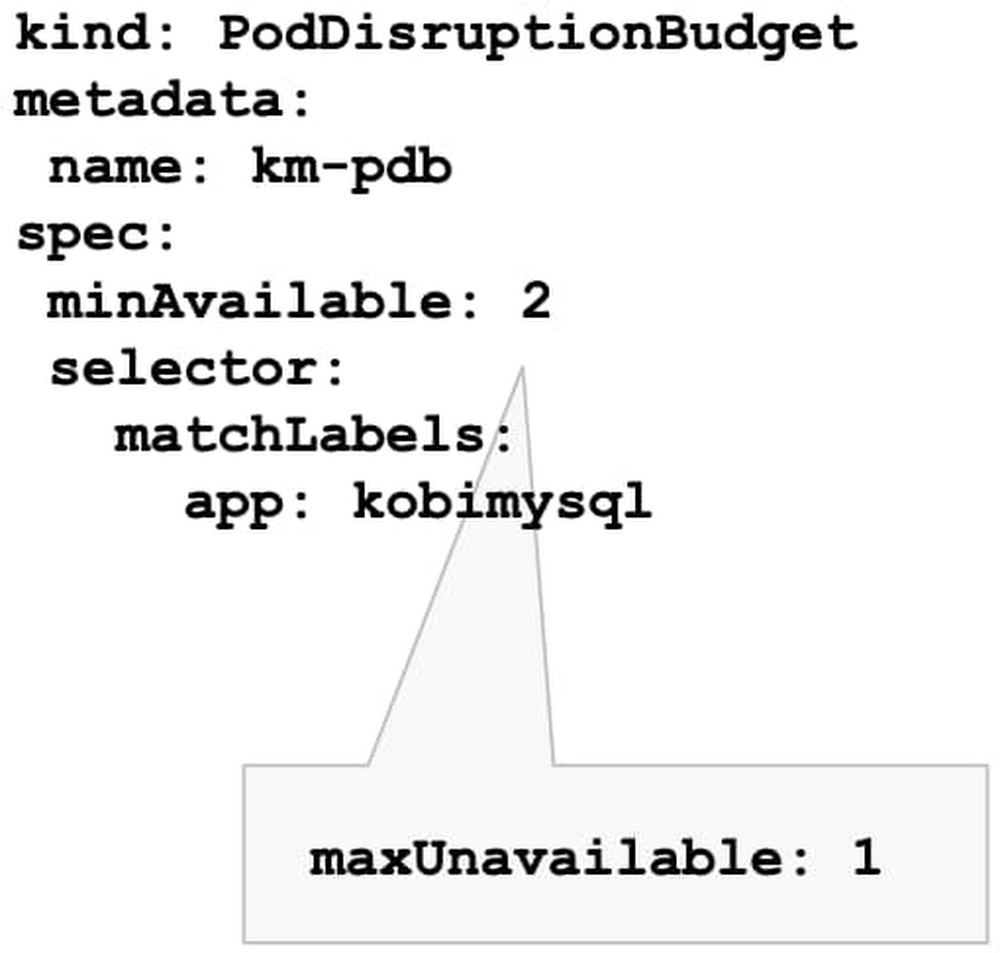
So, you followed our advice and built a highly available Google Kubernetes Engine (GKE) cluster based on our day 0 guidance. But day 2 is where the rubber hits the road: your GKE cluster is up and running, and serving traffic to your app, and can’t really afford to go down. The day 0 steps you took should help prevent that, but in production, ensuring business continuity isn’t just about the high availability of the workloads. It’s also about gracefully handling disruptions, and applying the latest security patches and bug fixes non-disruptively. In this blog post, we’ll discuss recommendations and best practices to help the applications running on your GKE cluster to stay happy and healthy. Manage disruptionAs with any platform’s lifecycle, there will come a time when your GKE cluster experiences an interruption, needs to be updated, or needs to shut down. You can limit the interference by proactively setting up the right number of replicas, setting a Pod Disruption Budget, and specifying your shutdown grace period.Make sure you have replicasYou may be familiar with the concept of Kubernetes replicas. Replicas ensure the redundancy of your workloads for better performance and responsiveness, and to avoid a single point of failure. When configured, replicas govern the number of pod replicas running at any given time.Set your tolerance for disruptionHowever, during maintenance, Kubernetes sometimes removes an underlying node VM, which can impact the number of replicas you have. How much disruption is too much? What’s the minimum number of replicas you need to continuously operate your workloads while your GKE cluster is undergoing maintenance? You can specify this using the Kubernetes Pod Disruption Budget, or PDB.Setting PodDisruptionBudget ensures that your workloads have a sufficient number of replicas, even during maintenance. Using the PDB, you can define a number (or percentage) of pods that can be terminated, even if terminating them brings the current replica count below the desired value. With PDB configured, Kubernetes will drain a node following the configured disruption schedule. New pods will be deployed on other available nodes. This approach ensures Kubernetes schedules workloads in an optimal way while controlling the disruption based on the PDB configuration.Once the PDB is set, GKE won’t shut down pods in your application if the number of pods is equal to or less than a configured limit. GKE respects a PDB for up to 60 minutes. Note that the PDB only protects against voluntary disruptions—upgrades for example. It offers no protection against involuntary disruptions (e.g., a hardware failure).Terminate gracefullySometimes, applications need to terminate unexpectedly. By default, Kubernetes sets the termination grace period to 30 seconds. This should be sufficient for most lightweight, cloud-native applications. However the default setting might be too low for heavyweight applications or applications that have long shutdown processes.The recommended best practice is to evaluate your existing grace periods and tune them based on the specific needs of your architecture and application. You can change the termination grace period by altering terminationGracePeriodSeconds.Schedule updates and patchesKeeping your cluster up to date with security patches and bug fixes is one of the most important things you can do to ensure the vitality of the cluster and business continuity. Regular updates protect your workloads from vulnerabilities and failures. However, timing plays a major role in performing these updates. Especially now when many teams are working from home or at reduced capacity, you want to increase the predictability of these upgrades, and perhaps avoid changes during regular business hours. You can do that by setting up maintenance windows, sequencing roll-outs, and setting up maintenance exclusions. Set your maintenance windowsSetting up a maintenance window lets you control automatic upgrades to both the cluster control plane and its nodes. GKE respects maintenance windows. Namely if the upgrade process runs beyond the defined maintenance window, GKE will attempt to pause the operation and resume it during the next maintenance window.You can also use maintenance windows in a multi-cluster environment to control and sequence disruption in different clusters. For example, you may want to control when to perform maintenance on clusters in different regions by setting different maintenance windows for each cluster.Practice regular updates New GKE releases are rolled out on a regular basis as patches become available in the fleet.The rollout process of these updates is done gradually, and some version upgrades may take several weeks to completely rollout in the entire GKE fleet.Nonetheless, in times of uncertainty, you can specify the day and time maintenance can occur in a week by setting your maintenance windows, to better plan and anticipate maintenance to your clusters.Please do not disturbThere are times when you may want to completely avoid maintenance (e.g. holidays, high season, company events, etc.), to ensure your clusters are available to receive traffic. With maintenance exclusions, you can prevent automatic maintenance from occurring during a specific time period. Maintenance exclusions can be set on new or existing clusters. The exclusion windows can also be used in conjunction with an upgrade strategy. For example, you may want to postpone an upgrade to a production cluster if a testing/staging environment fails because of an upgrade.Upgrade node pool versions without disruptionUpgrading a GKE node pool can be a particularly disruptive process, as it involves recreating every VM in the node pool. The process is to create a new VM with the new version (upgraded image) in a rolling update fashion, which requires shutting down all the pods running on the old node and shifting to the new node.By following the recommendations above, your workloads can run with sufficient redundancy (replicas) to minimize disruption, and Kubernetes will move and restart pods as needed. However, a temporarily reduced number of replicas can be still disruptive to your business, and may slow down workload performance until Kubernetes is able to meet the desired state again (i.e., meet the minimum number of needed replicas). To eliminate this disruption entirely, you can use the GKE node surge upgrade feature. Once configured, surge upgrade secures the resources (machines) needed for the upgrade by first creating a new node, then draining the old node, and finally shutting it down. This way, the expected capacity remains intact throughout the upgrade process.Speed up upgrades for large clustersLarge clusters mean larger nodepools, which can take a long time to upgrade if you’re updating one node at a time—especially if you’ve set a maintenance window. In this case, an upgrade starts at the beginning of the maintenance window, and lasts for the duration of the maintenance window (four hours). If GKE can’t complete upgrading all the nodes within the allotted maintenance window, it pauses the upgrade and resumes it in the next maintenance window.You can accelerate your upgrade completion time by concurrently upgrading multiple nodes with the surge upgrade feature. For example, if you set maxSurge=20 and maxUnavailable=0, GKE will upgrade 20 nodes at a time, without using any existing capacity. Bringing it all togetherContainerized applications are portable and easy to deploy and scale. GKE makes it even easier to run your workloads hassle-free with a wide range of cluster management capabilities. Knowing your application the best, you can drastically improve the availability and vitality of your clusters by following the recommendations above.To learn more, register for the Google Cloud Next ‘20: OnAir session, Ensuring Business Continuity at Times of Uncertainty and Digital-only Business with GKE, which goes live on August 25, 2020.
Quelle: Google Cloud Platform