An application modernization bonanza — What happened at Next OnAir
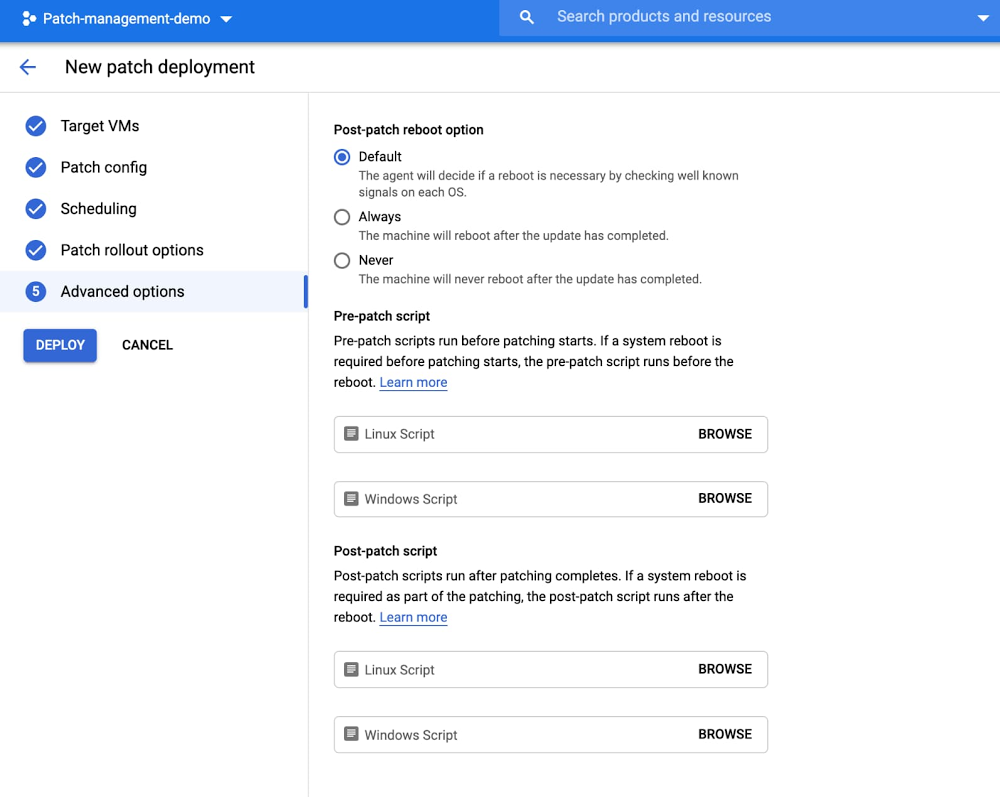
Week seven of Google Cloud Next ‘20: OnAir was all about application modernization—of your existing workloads, and the ones you will build tomorrow. We kicked things off with not one, not two, but three keynotes: the first, by Eyal Manor, GM & VP, Engineering; Pali Bhat, VP, Product & Design and Chen Goldberg, Engineering Director, talks about all things Anthos. Then, a second keynote by Bhat and Aparna Sinha, Director, Product Management shows you how Google Cloud can help bring your application development and delivery processes to the next level. Finally, in a third developer keynote, VP of Developer Relations Amr Awadallah tackled the question of whether you can have both innovation and stability in enterprise IT.And then the party really got started. Key announcements from app modernization weekAnthos just keeps getting better and more full-featured. With Anthos’ new hybrid AI capabilities, you can now run Google Cloud AI services on-premises, near your most sensitive data. We announced Anthos attached clusters, to let you manage AWS EKS and Azure AKS clusters with the Anthos control plane, and the beta availability of Anthos for bare metal, a low-overhead alternative to run Anthos at the edge. In addition, Google Cloud application development tools are now more tightly integrated with Anthos than ever before, and the Anthos Identity Service lets you extend your existing identity solutions with Anthos workloads. Finally, it’s easier than ever to migrate workloads into Anthos, even when they run windows, or run on Cloud Foundry. Read this blog for more details. We showered new features on developers this week too. First, we added support for Cloud Run into our Cloud Code IDE plugins, and made it easier to incorporate changes in your local development environment with the help of a new Cloud Run emulator in Cloud Code. New Google Cloud Buildpacks in Cloud Code help you start writing new applications quickly, while Events for Cloud Run lets you connect Cloud Run services with events from a variety of sources. New Workflows in beta let you integrate custom actions, Google APIs and third-party APIs into your code, and the beta Artifact Registry can help you secure your software supply chain by letting you manage and secure artifacts. Finally, Cloud Run now supports traffic splitting and gradual rollouts, and we’ve made it easier to set up Continuous Deployment directly from the Cloud Run user interface. For all this developer news (and more!), check out this post. Are you ready to modernize your applications, but don’t know where to start? The new Google Cloud Application Modernization Program, or Google CAMP, can help you get to the future faster. With data-driven assessment and benchmarking, a full suite of developer tooling and compute platforms, and proven best practices and recommendations from Google and the DevOps Research and Assessment team (DORA), click here to learn more about how Google CAMP can help you get a leg up on your modernization project.Break out the knowledgeThis is quite the week for breakout sessions—not counting solutions keynotes and highlight reels, we debuted 53 new sessions this week! Take your pick from sessions on application modernization and containers, application development, operations and SRE, cost management, security and serverless. Click here for a full list and to add them to your watchlist. Watch demosA conference isn’t complete without demos, and Next OnAir app modernization week was no different. We debuted three new interactive demos, plus four video demos, to educate you about trends in application development or to get you up to speed about Google Cloud’s latest products and features. To wit: go on an app modernization journey and watch how Anthos balances security with agility, reliability with efficiency, and portability with consistency. Watch cloud-native app development in action or see how Cloud Code makes it easy to manage Kubernetes config and debug a service on a Kubernetes cluster. Check out the complete list of interactive demo content from the week. Don’t just take our word for itPerhaps the most important part of Next OnAir is hearing from your peers at companies that have adopted Google Cloud. Texas retailer H-E-B takes to the OnAir airwaves to talk about how it modernized with containers and Anthos. Lowe’s talks software development, CI/CD and monitoring; and MTX talks about how Google Cloud has helped state agencies through the pandemic. Etsy shares best practices for cost management using billing data. Game maker Niantic talks about custom metrics and SRE, and Shopify opines on observability. And you’ll be on the edge of your seat listening to Major League Baseball talk about Anthos on bare metal. Check out all these customer stories and others from the full app modernization week session guide. Looking ahead: AISeven weeks of Next OnAir down, two to go. Up next: artificial intelligence. Join us on Tuesday, September 1, when Principal Software Engineer Ting Lu and VP of Product Management Rajen Sheth take to the stage to talk about generating value with Cloud AI. Of course, we’ll also bring you live technical talks and learning opportunities, aligned with each week’s content. Click “Learn” on the Explore page to find each week’s schedule. Haven’t yet registered for Google Cloud ’20 Next: OnAir? Get started at g.co/cloudnext.
Quelle: Google Cloud Platform