How AI uncovers important contract data
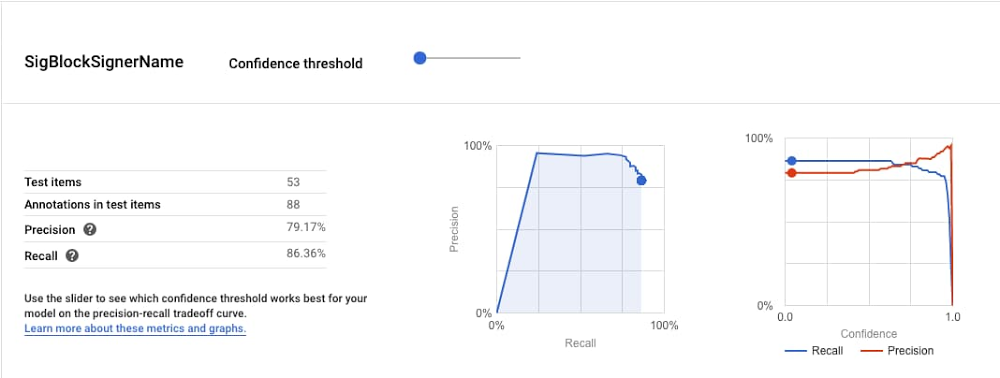
What happens to business contracts in an organization after signature? Usually, the answer is nothing. They sit in Gmail, Drive, or in a dedicated contract repository until, in rare cases, someone needs to recheck the agreement terms. At which point a scramble ensues to find the contract, read through it, and discover what exactly was agreed to.Contracts contain valuable data about your business: whom you’ve engaged with, what you’ve promised, how much you’re owed, when the deal expires, where terms apply, and that’s just the tip of the iceberg. These documents are legally validated by all the parties involved, which means that the data they contain is intrinsically accurate.So why, in an age when data flows freely from every imaginable source, is it still so hard to see what’s in your contracts? At Ironclad, that’s one of the major problems we’re attempting to solve. And thanks in large part to Google Cloud AI, we’re excited to share the news of our advancements.But first, a few things about contracts. Why contracts are hardBusiness contracts have all but resisted the wave of digital transformation. Yes, we now draft in Microsoft Word, share via email, and use eSignature instead of “wet” signatures, but the structure, language, and formatting of contracts are the same as they were in the 1920s, and the valuable information represented in contracts remains decidedly analog. We believe that the world is sure to adopt a form of natively-digital contracting. (We’re working on it!) But it’s going to take a while, and, in the meantime, we need to find a way to unlock the data stored in Word docs and PDFs.That’s not an easy thing to do. Here’s why:Problem #1: Contracts are unstructured, unstandardized, and use nuanced legal language.Problem #2. Contracts exist to guard against rare and potentially catastrophic occurrences, so tolerance for false negatives and false positives is pretty close to zero. Natural Language Processing (NLP) is a great tool for Problem #1. In 2017 we started experimenting with it. Unfortunately, the feature development was too slow. A single experiment could take weeks, and to build a pipeline of promising experiments took months. It would have taken ages just to get half-decent accuracies, let alone figure out how to address Problem #2.So, we put NLP on the back-burner and waited for the technology to catch up. The technology did catch up – and just in time, too.Almost as soon as the pandemic began, our customers started asking for more information about their contracts. They needed to know everything from opt-out clauses and force majeure to employment terms and accounts receivables, and they wanted to know faster (and more cheaply) than a team of humans could reasonably extract it.All of a sudden, we needed a new approach to AI. And as fate would have it, we discovered Google Cloud AutoML Natural Language.We started with AutoML’s Entity Extraction model. First, we uploaded a small, curated set of contracts and labeled three properties: entity name, signature date, and signer name. After a few hours of training, signature date had precision and recall rates surpassing 90%. This was the best result we’d ever achieved over three years of on-and-off experiments — and, incredibly, Google needed a relatively tiny data set to achieve it.But we weren’t fully convinced. The data set was small and the model failed on both entity name and signer name. So as a next step we changed up our labeling and expanded the data set. A few more hours of training, and accuracy rates on entity name and signer name rose to 70% and 90%, respectively.An early experiment with promising results.That was all we needed to see. We’d found the answer to our NLP problem, and it took just two tests to get there. Plus, it came with a bonus: the model was immediately live on Google Cloud AI Platform for predictions, so we could start testing the user experience that very day. Within a week, we had our first feature prototype.Before/after AutoML + AI Platform Prediction.Ironclad Smart Import: Unlocking contract data with Google Cloud AINow, a few months later, we’re in alpha with a handful of customers. The feature is Smart Import, a fast and accurate way to extract data from contracts generated outside of Ironclad. (Contracts generated within Ironclad are already digital and don’t require data extraction.) The feature works on an increasing number of key data properties with some accuracy rates exceeding 90%. Yet even 90%+ isn’t good enough in the world of contracting. (See Problem #2.) That’s why the feature also enables users to deliver the last mile of data accuracy themselves, aided by an intuitive data validation flow with human reviewers. Ironclad’s design and product teams had plenty of flexibility to implement this validation flow thanks to AI Platform and our massively simplified NLP pipeline. And their work has paid off: a few customers have already used Smart Import to analyze thousands of contracts.Problem #2, solved.At this rate, we expect to launch in Q1 2021 to hundreds of excited customers. (We hope you’ll join us at the event!) But we see this as just the beginning — already we’re exploring new ways to apply Google Cloud AI to make contracting faster and smarter for our customers.Related ArticleDiscover insights from text with AutoML Natural Language, now generally availableAutoML Natural Language is generally available and has new featuresRead Article
Quelle: Google Cloud Platform