Comparing containerization methods: Buildpacks, Jib, and Dockerfile
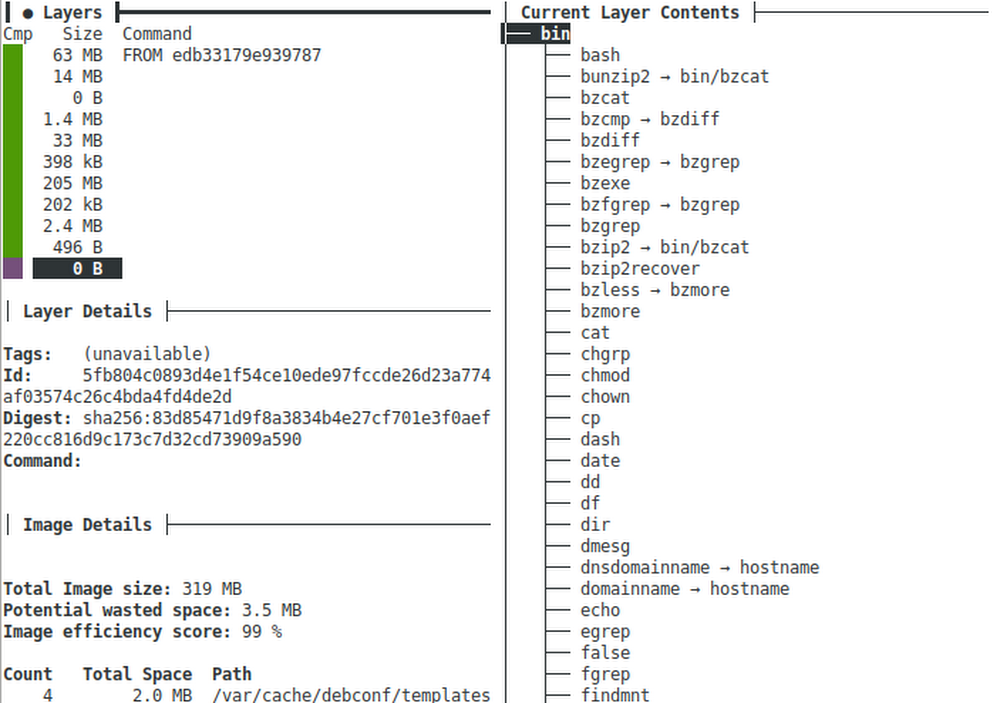
As developers we work on source code, but production systems don’t run source, they need a runnable thing. Starting many years ago, most enterprises were using Java EE (aka J2EE) and the runnable “thing” we would deploy to production was a “.jar”, “.war”, or “.ear” file. Those files consisted of the compiled Java classes and would run inside of a “container” running on the JVM. As long as your class files were compatible with the JVM and container, the app would just work.That all worked great until people started building non-JVM stuff: Ruby, Python, NodeJS, Go, etc. Now we needed another way to package up apps so they could be run on production systems. To do this we needed some kind of virtualization layer that would allow anything to be run. Heroku was one of the first to tackle this and they used a Linux virtualization system called “lxc” – short for Linux Containers. Running a “container” on lxc was half of the puzzle because still a “container” needed to be created from source code, so Heroku invented what they called “Buildpacks” to create a standard way to convert source into a container.A bit later a Heroku competitor named dotCloud was trying to tackle similar problems and went a different route which ultimately led to Docker, a standard way to create and run containers across platforms including Windows, Mac, Linux, Kubernetes, and Google Cloud Run. Ultimately the container specification behind Docker became a standard under the Open Container Initiative (OCI) and the virtualization layer switched from lxc to runc (also an OCI project).The traditional way to build a Docker container is built into the docker tool and uses a sequence of special instructions usually in a file named Dockerfile to compile the source code and assemble the “layers” of a container image.Yeah, this is confusing because we have all sorts of different “containers” and ways to run stuff in those containers. And there are also many ways to create the things that run in containers. The bit of history is important because it helps us categorize all of this into three parts:Container Builders – Turn source code into a Container ImageContainer Images – Archive files containing a “runnable” applicationContainers – Run Container ImagesWith Java EE those three categories map to technologies like:Container Builders == Ant or MavenContainer Images == .jar, .war, or .earContainers == JBoss, WebSphere, WebLogicWith Docker / OCI those three categories map to technologies like:Container Builders == Dockerfile, Buildpacks, or JibContainer Images == .tar files usually not dealt with directly but through a “container registry”Containers == Docker, Kubernetes, Cloud RunJava Sample ApplicationLet’s explore the Container Builder options further on a little Java server application. . If you want to follow along, clone my comparing-docker-methods project:git clone https://github.com/jamesward/comparing-docker-methods.gitcd comparing-docker-methodsIn that project you’ll see a basic Java web server in src/main/java/com/google/WebApp.java that just responds with “hello, world” on a GET request to /. Here is the source:This project uses Maven with a minimal pom.xml build config file for compiling and running the Java server:If you want to run this locally make sure you have Java 8 installed and from the project root directory, run:./mvnw compile exec:javaYou can test the server by visiting: http://localhost:8080Container Builder: BuildpacksWe have an application that we can run locally so let’s get back to those Container Builders. Earlier you learned that Heroku invented Buildpacks to create standard, polyglot ways to go from source to a Container Image. When Docker / OCI Containers started gaining popularity Heroku and Pivotal worked together to make their Buildpacks work with Docker / OCI Containers. That work is now a sandbox Cloud Native Computing Foundation project: https://buildpacks.io/To use Buildpacks you will need to install Docker and the pack tool. Now from the command line tell Buildpacks to take your source and turn it into a Container Image:pack build –builder=gcr.io/buildpacks/builder:v1 comparing-docker-methods:buildpacksMagic! You didn’t have to do anything and the Buildpacks knew how to turn that Java application into a Container Image. It even works on Go, NodeJS, Python, and .Net apps out-of-the-box. So what just happened? Buildpacks inspect your source and try to identify it as something it knows how to build. In the case of our sample application it noticed the pom.xml file and decided it knows how to build Maven-based applications. The –builder flag told it where to get the Buildpacks from. In this case, gcr.io/buildpacks/builder:v1 are the Container Image coordinates to Google Cloud’s Buildpacks. Alternatively you could use the Heroku or Paketo Buildpacks. The parameter comparing-docker-methods:buildpacks is the Container Image coordinates for where to store the output. In this case it stores on the local docker daemon. You can now run that Container Image locally with docker:docker run -it -ePORT=8080 -p8080:8080 comparing-docker-methods:buildpacksOf course you can also run that Container Image anywhere that runs Docker / OCI Containers like Kubernetes and Cloud Run.Buildpacks are nice because in many cases they just work and you don’t have to do anything special to turn your source into something runnable. But the resulting Container Images created from Buildpacks can be a bit bulky. Let’s use a tool called dive to examine what is in the created container image:dive comparing-docker-methods:buildpacksHere you can see the Container Image has 11 layers and a total image size of 319MB. With dive you can explore each layer and see what was changed. In this Container Image the first 6 layers are the base operating system. Layer 7 is the JVM and layer 8 is our compiled application. Layering enables great caching so if only layer 8 changes, then layers 1 through 7 do not need to be re-downloaded. One downside of Buildpacks is how (at least for now) all of the dependencies and compiled application code are stored in a single layer. It would be better to have separate layers for the dependencies and the compiled application.To recap, Buildpacks are the easy option that “just works” right out-of-the-box. But the Container Images are a bit large and not optimally layered.Container Builder: JibThe open source Jib project is a Java library for creating Container Images with Maven and Gradle plugins. To use it on a Maven project (like the one we from above), just add a build plugin to the pom.xml file:Now a Container Image can be created and stored in the local docker daemon by running:./mvnw compile jib:dockerBuild -Dimage=comparing-docker-methods:jibUsing dive we will see that the Container Image for this application is now only 127MB thanks to slimmer operating system and JVM layers. Also, on a Spring Boot application we can see how Jib layers the dependencies, resources, and compiled application for better caching:In this example the 18MB layer contains the runtime dependencies and the final layer contains the compiled application. Unlike with Buildpacks the original source code is not included in the Container Image. Jib also has a great feature where you can use it without docker being installed, as long as you store the Container Image on an external Container Registry (like DockerHub or the Google Cloud Container Registry). Jib is a great option with Maven and Gradle builds for Container Images that use the JVM.Container Builder: DockerfileThe traditional way to create Container Images is built into the docker tool and uses a sequence of instructions defined in a file usually named Dockerfile. Here is a Dockerfile you can use with the sample Java application:In this example, the first four instructions start with the AdoptOpenJDK 8 Container Image and build the source to a Jar file. The final Container Image is created from the AdoptOpenJDK 8 JRE Container Image and includes the created Jar file. You can run docker to create the Container Image using the Dockerfile instructions:docker build -t comparing-docker-methods:dockerfile Using dive we can see a pretty slim Container Image at 209MB:With a Dockerfile we have full control over the layering and base images. For example, we could use the Distroless Java base image to trim down the Container Image even further. This method of creating Container Images provides a lot of flexibility but we do have to write and maintain the instructions.With this flexibility we can do some cool stuff. For example, we can use GraalVM to create a “native image” of our application. This is an ahead-of-time compiled binary which can reduce startup time, reduce memory usage, and alleviate the need for a JVM in the Container Image. And we can go even further and create a statically linked native image which includes everything needed to run so that even an operating system is not needed in the Container Image. Here is the Dockerfile to do that:You will see there is a bit of setup needed to support static native images. After that setup the Jar is compiled like before with Maven. Then the native-image tool creates the binary from the Jar. The FROM scratch instruction means the final container image will start with an empty one. The statically linked binary created by native-image is then copied into the empty container.Like before you can use docker to build the Container Image:docker build -t comparing-docker-methods:graalvm .Using dive we can see the final Container Image is only 11MB!And it starts up super fast because we don’t need the JVM, OS, etc. Of course GraalVM is not always a great option as there are some challenges like dealing with reflection and debugging. You can read more about this in my blog, GraalVM Native Image Tips & Tricks.This example does capture the flexibility of the Dockerfile method and the ability to do anything you need. It is a great escape hatch when you need one.Which Method Should You Choose?The easiest, polyglot method: BuildpacksGreat layering for JVM apps: JibThe escape hatch for when those methods don’t fit: DockerfileCheck out my comparing-docker-methods project to explore these methods as well as the mentioned Spring Boot + Jib example.Related ArticleAnnouncing Google Cloud buildpacks—container images made easyGoogle Cloud buildpacks make it much easier and faster to build applications on top of containers.Read Article
Quelle: Google Cloud Platform