Database Migration Service Connectivity – A technical introspective
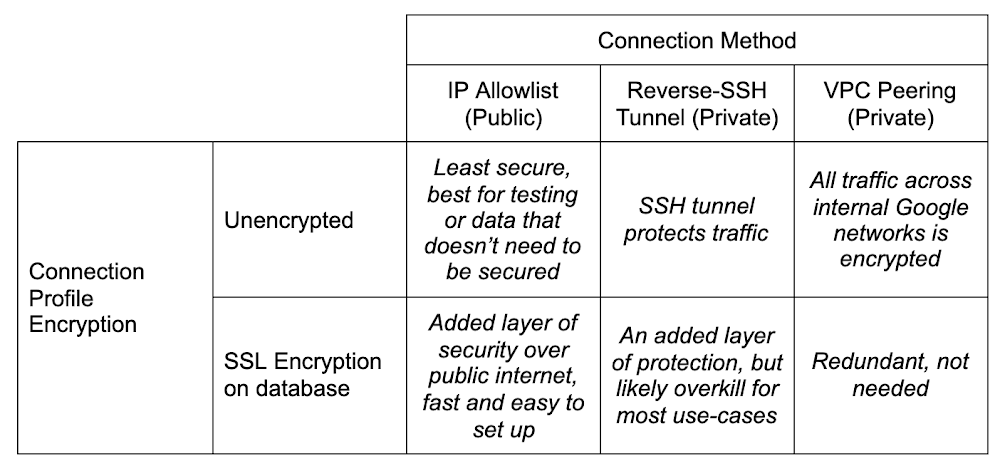
Hopefully you’ve already heard about a new product we’ve released: Database Migration Service (DMS). If you haven’t, you should check out the announcement blog. TL;DR, the idea is to make migrating your databases reliably into a fully managed Cloud SQL instance as easy and secure as possible.I’ll be talking a lot about MySQL (available in preview) and PostgreSQL (available in preview by request, follow this link to sign up) in this post. I’m not leaving SQL Server out in the cold, it’s just that as of the writing of this blog, DMS doesn’t yet support SQL Server, but it will! Look for an announcement for support a bit later on.So, you’ve got a database you want to move into the Cloud. Or perhaps it’s in the Cloud, but it’s not managed by Cloud SQL (yet). Let’s chat a bit, shall we?There’s lots of work that goes into making the decision to migrate, and preparing your application for its data store’s migration. This post assumes you’ve made the decision to migrate, you’re evaluating (or have evaluated and are ready to go with) DMS to do it, and you’re prepared to get your application all set to cut over and point to the shiny new Cloud SQL instance once the database migration is complete.What I want to talk to you about today is connectivity. I know, I know, it’s always DNS. But, on the off chance it’s not DNS? Let’s talk. DMS guides you through the process with several knobs you can turn to fit how you manage the connection between your source and the managed Cloud SQL database in a way that satisfies your org’s security policy.Before I go too far down the connectivity rabbit hole, I want to call out that there are things that you’ll need to do and think about before you get here. You’ll want to think about preparing your database and application for migration, and understand the next steps once the migration with DMS is complete. Be on the lookout for a few other blogs that cover these topics in depth. One in particular which covers homogenous migration best practices segues nicely into my next section…Pre-emptive troubleshootingCouple pieces that are super important for prep that I want to also call out here, because they will cause a failure if you miss them. They are covered in depth in the blog I linked to just above, and are presented in the DMS UI as required configuration for migration, but they are important enough to repeat!Server_id configIf you’re migrating MySQL (I might have hit this a few times, and by a few I mean lots), don’t forget to change your source database’s server_id. The TL;DR is when you set up replicas, each database has to have a different server_id. You can change it a few different ways. You can start the mysqld process with the –server-id=# flag if you’re starting it by hand, or via script. You can connect to the db with a client and run SET GLOBAL server_id=#, but note if you do this, you have to remember to re-do this each time the server resets. And lastly, you can set in a my.cnf file:Bind-address configOne other big thing to watch out for, which I hit a couple times as well, is the bind-address for your database. Again, this is covered in more detail in the other posts, but to fix it (and note you should be careful here as it can be a security risk) you need to change it in your configuration from the default (at least for MySQL) from 127.0.0.1 to 0.0.0.0. This is what opens it wide to allow connections from everywhere, not just local connections. You can also try to be more targeted and just put the IP address of the created Cloud SQL database, but the exact IP address can be a bit hard to pin down. Cloud SQL doesn’t guarantee outgoing IP addresses, so specifying the current one may not work.For both server_id and bind-address, don’t forget if you’re changing the configuration files you need to restart the database service so the changes take effect.Connectivity options and setupDMS has a matrix of how you can connect your source database to the new Cloud SQL instance created in the migration setup. Choose the method that best fits where your source database lives, your organization’s security policy, and your migration requirements. As you can see, most of the decisions come down to how secure you need to be. Consider, for example, that using the IP allowlist method means poking a hole in your network’s firewall for incoming traffic. This might not be possible depending on your company’s security policies. Let’s dive in.DMS Connection ProfilesWhen defining your source, you create a connection profile that defines the information used to connect to the source database you are migrating from. These connection profiles are standalone resources, so once you’ve created one, you can re-use it in future migrations. A use case for re-use might be something like, as a step towards sharding your database, you might want to migrate the same database to multiple target Cloud SQL instances that would live behind a proxy or load balancer of some sort. Then you could pare down each individual instance to only the sharded data you want in each one, rather than trying to be careful to only pull out the sharded data from the main instance.Connection profiles are made up of the following components: The source database engine, a name and ID, connection information for the database itself (host, port, username, password) and whether or not you want to enforce SSL encryption for the connection. Everything’s straight forward here except the SSL connectivity, which can be confusing if you’re not familiar with SSL configurations. DMS supports either no encryption, server-only encryption, or server-client encryption. The documentation on this is good for explaining this bit!Short version: Server-only tells the Cloud to verify your source database, and server-client tells both to verify each other. Best practice is of course to always encrypt and verify. If you’re really just playing, and don’t want to deal with generating SSL keys, then sure, don’t encrypt. But if this is at all production data, or sensitive data in any way, especially if you’re connecting with public connectivity, please please be sure to encrypt and verify.When you do want to, the hardest part here is generating and using the right keys. DMS uses x509 formatted SSL keys. Information on generating and securing instances with SSL, if you haven’t done it before, can be found here for MySQL and here for PostgreSQL. Either way, you’ll need to be sure to get your keys ready as part of your migration prep. On MySQL for example, you can run mysql_ssl_rsa_setup to get your instance’s keys, and it’ll spit out a bunch:If, like me, you’re relatively new to setting up SSL against a server, you can test to be sure you’ve set it up correctly by using a client to connect via SSL. For example, for MySQL you can do: mysql -u root -h localhost –ssl-ca=ca.pem –ssl-cert=client-cert.pem –ssl-key=client-key.pem –ssl-mode=REQUIRED -p to force testing if your keys are correct.I had a bit of difficulty uploading the right formatted key using the upload fields. It complained about improperly formatted x509 keys, despite me confirming that I had (or least I THOUGHT I was sure, I am not an SSL expert by any stretch of the imagination) wrapped them correctly. The solution for me, if you’re getting the same errors, was to simply switch from uploading the key files to manually entering them, and copy/pasting the contents of the key into the fields. That worked like a charm!Okay, so now that we’re covered on the source side, time to talk about the different methods we can use to connect between the source and the soon-to-be-created Cloud SQL instance.Creating the destination is straightforward in that you’re specifying a Cloud SQL instance. DMS handles all the pieces setting up the replication and preparing it to be receiving the data. The one thing to look out for is connectivity method. If you use IP allowlist, you need to have Public IP set for connectivity on the Cloud SQL instance, and for Reverse-SSH and VPC peering, you need to have Private IP set. And if you’re using VPC peering, be sure to put the Cloud SQL instance into the same VPC as the GCE instance where your source database lives. Don’t worry, if you forget to select the right setting or change your mind, DMS will update the Cloud SQL instance settings when you choose your connectivity setting.As I outlined above, there are three different ways you can bridge the gap: IP allowlist, Reverse-SSH tunnel, and VPC peering. Really this decision comes down to one consideration: how secure you’re required to be. Maybe because of some industry regulations, internal policies, or just needing to be secure because of the data involved in the database.Note here before we get into specifics… one of the hardest parts about migrating a database (to me), whether that is on your home machine playing around, or it’s on a server on-prem at your office’s server room, or in some other cloud, is creating a network path between all the various firewalls, routers, machines and the Internet. I was stuck here for longer than I care to admit before I realized that I not only had a router I had to forward ports between so it knew how to find my local database, but I ALSO had a firewall on my modem/router that sits between the internet and my internal switch which I had failed to ALSO forward through. So word to the wise, triple check each hop on your network that it’s correctly forwarding from the outside. If you have a network expert handy to help, they can even help create the connection profile for you to use later!IP allowlistIP allowlisting is, by an order of magnitude, the simplest method of connecting the two points. When creating your Cloud SQL instance as part of migration setup, you’re going to add an authorized network pointing at the IP address of your source database and conversely, you need to open a hole in your own firewall to allow Cloud SQL to talk to your source database. In my case, running a local database meant searching whatsmyip, and copying the IP into the authorized network in the Cloud SQL creation. And the other direction was I created a port forward on my firewall for traffic from the Cloud SQL outgoing IP address, which DMS gave me on the connectivity step (but I could have also copied from the Cloud SQL instance’s details page), to my local database’s machine, and away we went. There aren’t any special gotchas with this method that I’ve encountered beyond what I mentioned above about making sure to check your network topology for anything stopping the route from getting through to your database.IP allowlist is the least secure of the three connectivity methods. I’m not saying that it’s inherently insecure. As long as you’re still using SSL encryption, you’ll probably find it’s still plenty secure for your normal use-cases. Just compared to the reverse-SSH tunnel, or using a VPC peering, it’s going to be less secure. It’s all relative!Reverse-SSH tunnel via cloud-hosted VMNext in the secure spectrum is going to be reverse-SSH tunneling. If you haven’t used this before, or don’t know what it is, I really liked this person’s answer on stack exchange. It’s a good, thorough explanation that makes it easy to understand what’s going on. Short version, think of it as a literal tunnel that gets built between your source database network, a virtual machine instance in Google Compute Engine, and the Cloud SQL instance that you’re migrating to. This tunnel shields your traffic from the internet it travels through.Alright, so with this method, we have an added component: The virtual machine that we use as the connector piece of our SSH tunnel. This brings with it an added layer of fun complexity! For the most part, the creation of this is handled for you by DMS. When you choose Reverse-SSH as your connectivity method in the UI, you have the option of using an existing VM, or creating one. Either way, a script will be generated for you that when run from a machine that has access to your source database, will set up the VM in such a way that it can successfully be used as the SSH tunnel target.As with all things automated, there’s a few gotchas here that can happen and cause some rather hard to diagnose blocks. Things I hit to watch out for:VM_ZONE The UI is pretty good about this now, but beware that if somehow you manage to get to viewing the VM setup script before the Cloud SQL instance completes setup first (and creating a Cloud SQL instance can take up to about five minutes sometimes), then a variable in the script will not get set properly: VM_ZONE.It won’t have the right zone there, and you’ll have to fill it in, and/or re-hit the “View Script” button once the Cloud SQL instance creation finishes to have it filled in.Machine typeAs of the writing of this blog, this hasn’t been fixed yet, but the VM_MACHINE_TYPE is also the wrong variable if you left the machine type dropdown as the default. The variable will be set to db-n1-standard-1 in the script, when it should be n1-standard-1. That will fail to create the VM.Server IDTriple check that if you’re migrating MySQL that your server_id is set to non-zero. I know, I said it before. I may or may not have forgotten at this step and lost some time because of it. Just sayin’.The script also immediately establishes the reverse tunnel in the background with this line:gcloud compute ssh “${VM_NAME}” –zone=”${VM_ZONE}” –project=”${PROJECT_ID}” — -f -N -R “${VM_PORT}:${SOURCE_DB_LOCAL_IP}:${SOURCE_DB_LOCAL_PORT}”Heads up, this script will run something in the background on the machine you run it on. That -f in the above command is what causes it to be in the background. I’m not a fan of things running in the background, mostly because then I have to remember to stop it if it’s not something I want running all the time. In this case, if I’m doing multiple migrations it could get confused about which tunnel should be used, or some other edge case. So for me, I stripped this command out of the script, ran it to generate the VM, then ran this command without the -f in a terminal, substituting the values from the script variables.So, run the script (even though I didn’t leave the background command in there, it’s fine if you’re comfortable with it, just don’t forget that you did). Once you do, in the output from the script, you’ll see a line like: echo “VM instance ‘${VM_NAME} created with private ip ${private_ip}”. That IP address you need to put in the field VM server IP in the DMS migration step 4.So, remember when I said network connectivity can be a challenge? I wasn’t kidding. Now we have another layer of complexity with the virtual machine. By default, Google Compute Engine virtual machines are very locked down by a firewall (Security!!! It’s good that they are even if it makes our life more complicated). In order for reverse-SSH to work, we need to open a pinhole to our VM to communicate with the Cloud SQL instance we’ve created, even across the internal network. To do this, we need to create a new firewall rule.First things first, we want to keep things as locked down as we can. Towards that end, head over to the details page for the virtual machine you just created. The list of VMs are here. Edit your VM, and scroll down to find the network tags section:This allows you to pinpoint JUST this instance with your firewall rules. The tag can be anything, but remember what you use for the next step.Head on over to the firewall area of the console. It’s under Networking -> VPC network -> Firewall. Or just click here. Create a new firewall rule. Give it a name, and if you’re using a different VPC for your migration than the default one, be sure you pick the right one in the Network dropdown menu. Then in the Targets field, leave it on Specified target tags and in the field below, put the same tag that you added to your VM. Now, for the source filter, we have a bit of an oddity.Let me explain. Traffic comes from Cloud SQL through the tunnel back to your source to ensure connectivity. You can look back up at the diagram at the beginning of this section to see what it looks like.This means that Cloud SQL is going to try to get through the firewall to the VM, which is why we need to do this. There’s a catch here. The IP address you see for Cloud SQL, which you might think is what you need to put into the IP range filter for our firewall, is NOT in fact, the IP address that Cloud SQL uses for outgoing traffic. What this causes is a situation where we don’t know the IP address we need to filter on here. Cloud SQL doesn’t guarantee a static address for outgoing Cloud SQL traffic.So to solve for this, we need to allow the whole block of IP addresses that Cloud SQL uses. Do this by putting 10.121.1.0/24 in the Source IP ranges field. This is unfortunately a necessary evil. To lock it down further though, if you’re feeling nervous about doing this (they’re internal IPs so it’s really not that bad), you can, in the Protocols and ports section of your firewall, only allow tcp for the default port for your db engine (3306 for MySQL or 5432 for PostgreSQL). So the firewall will only allow traffic from that internal range of IPs, and only on the port of your db engine, and only for that one VM that we created.That’s it for the firewall, go ahead and hit Create. We should now, in theory, be all set to go! If you didn’t run the actual command to setup the tunnel in the script, then run it now; this is the command were talking about: gcloud compute ssh “${VM_NAME}” –zone=”${VM_ZONE}” –project=”${PROJECT_ID}” — -N -R “${VM_PORT}:${SOURCE_DB_LOCAL_IP}:${SOURCE_DB_LOCAL_PORT}”Once that’s going, you’re good to hit Configure & Continue and on to testing the job! Presuming all the stars align and the network gods favor you, hitting “Test Job” should result in a successful test, and you’re good to migrate!VPC PeeringPHEW, okay. Two methods down, one to go.VPC peering is, similarly to IP allowlist, very straightforward as long as you don’t forget the fundamentals I mentioned up above. Server_id, being sure your source database has its bind-address set to allow connections from the target, etc.There’s two scenarios (probably more, but two main ones) where you’d want to use VPC peering:Your source database is running in Google Cloud already, like on a Compute Engine instance.You’ve set up some networking to peer your source database’s network to the Google Cloud network using something like Cloud VPN or Cloud Interconnect.There is yet another deep rabbit hole to be had with peering external networks into GCP. In some cases it involves routing hardware in regions, considerations around cost versus throughput, etc. It’s a bit beyond the scope of this blog post because of the combinations possible, which often bring with them very specific requirements, and this blog post would end up being a novella. So for now, I’m going to gloss over it and just say it’s definitely possible to join your external network to Google Cloud’s internal one and use VPC peering to do a migration that way. In our documentation there’s a page that talks about it with an example if you want to dig in a bit more here.A more traditional usage of the VPC peering, however, is when you’ve got a database running on Compute Engine and want to switch to the more managed solution of Cloud SQL. There are several reasons why you might have originally wanted to be running your database on Compute Engine. A particular flag you were relying on that wasn’t mutable on Cloud SQL, or a version of MySQL or PostgreSQL you needed that wasn’t available yet, and many more.Whatever the reason you have it on GCE, now you’d like it managed on Cloud SQL, and VPC peering is the way to go. Here you’ll need to double-check the config settings on your database to be sure it’s ready as I’ve mentioned before. When creating your source connection profile, the IP address will be the GCE VM’s internal IP, not external IP (keep things inside the private network). You’ll need the firewall setup same as I described with the reverse-SSH tunnel. Note, that when you’re using VPC, the IP address of the Cloud SQL instance that you need to allow into your GCE instance won’t be the standard Cloud SQL range (10.121.1.0/24) because it will have been allocated an IP range in the VPC instead. So you’ll want to head over to the Cloud SQL instances page and grab the internal IP address of the read replica that’s there. If you don’t see the instance you created in the DMS destination step, or if the internal IP address isn’t specified, it might just not have been created yet. It does take a few minutes. Last piece is just make sure that whatever VPC you want this to happen in, all the pieces need to be in the same network. Your Cloud SQL destination you created, and the GCE instance holding your source database. Which means you might need to move them both into a new VPC first if that’s what you want. There’s definitely nothing wrong with doing it in the default VPC, BUT note if this is a very old project, then you may have a legacy default VPC. If you do, this won’t work and you will need to create a new VPC to do the migration.1) Logging. There’s two places which can help here. In the details of your GCE instance that’s hosting your database, or the hosting machine for the reverse-SSH tunnel, there’s a link for Cloud Logging.Clicking on that takes you straight to Logging filtered on that GCE’s entries. Then the second place is on the VPC network’s subnet you’re using. You can go here and then click on the zone that your GCE instance lives on, edit it, and turn on Flow Logs. Once you’ve done that, you can re-try the migration test and then check the logs to see if anything looks suspicious.2) Connectivity Tests. I hadn’t known about this until I was working with DMS, and it’s very handy. It lets you specify two different IP addresses (source and destination), a port you want to look at (MySQL 3306, PostgreSQL 5432), and it will give you a topology that shows you what hops it took to get from point a to point b, which firewall rules were applied to allow or deny the traffic. It’s super fun. You can go straight to it in the console here to play with it. It does require the Network Management API to be enabled to work with it.ConclusionThat’s it! Hopefully I’ve covered the basics here for you on how to get your source database connected to DMS in order to get your database migrated over to Cloud SQL. There’s some pieces to handle once you’ve finished the migration and we have an upcoming blog post to cover those loose ends as well.If you have any questions, suggestions or complaints, please reach out to me on Twitter, my DMs are open! Thanks for reading.Related ArticleAccelerating cloud migrations with the new Database Migration ServiceThe new Database Migration Service lets you perform a homogeneous migration to managed cloud databases like Cloud SQL for MySQL.Read Article
Quelle: Google Cloud Platform
