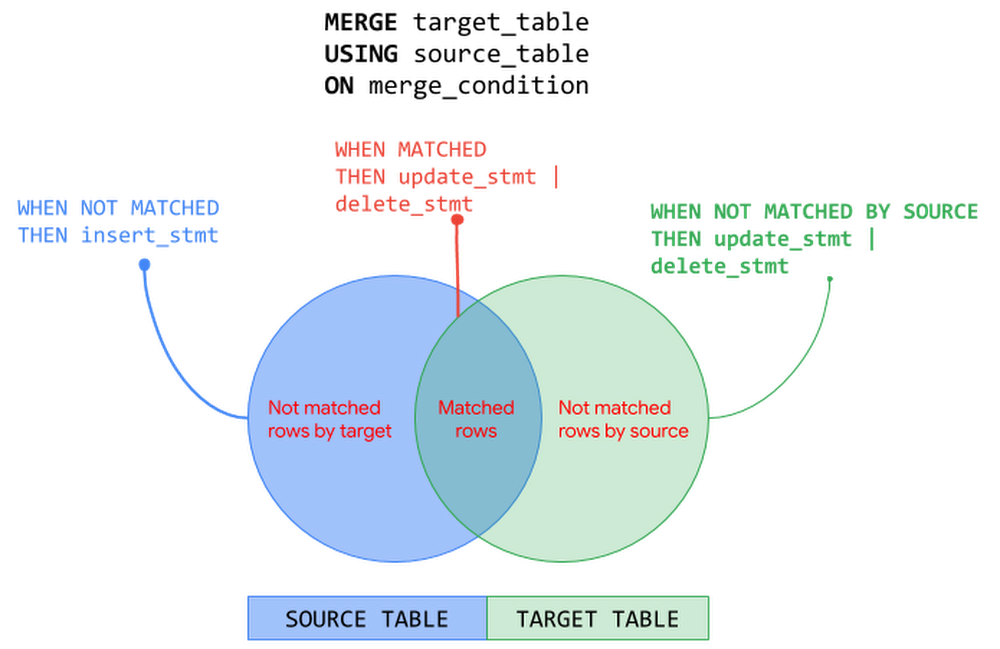
In the previous posts of BigQuery Explained, we reviewed how to ingest data into BigQuery and query the datasets. In this blog post, we will show you how to run data manipulation statements in BigQuery to add, modify and delete data stored in BigQuery. Let’s get started!Data Manipulation in BigQueryBigQuery has supported Data Manipulation Language (DML) functionality since 2016 for standard SQL, which enables you to insert, update, and delete rows and columns in your BigQuery datasets. DML in BigQuery supports data manipulation at an arbitrarily large number of rows in a table in a single job and supports an unlimited number of DML statements on a table. This means you can apply changes to data in a table more frequently and keep your data warehouse up to date with the changes in data sources. In this blog post we will cover:Use cases and syntax of common DML statementsConsiderations when using DML, including topics like quotas and pricingBest practices for using DML in BigQueryFollowing tables will be used in the examples in this post:TransactionsCustomerProductLet’s start with DML statements supported by BigQuery and their usage – INSERT, UPDATE, DELETE and MERGE.INSERT statementINSERT statement allows you to append new rows to a table. You can insert new rows using explicit values or by querying tables or views or using subqueries. Values added must be compatible with the target column’s data type. Following are few patterns to add rows into a BigQuery table:INSERT using explicit values:This approach can be used to bulk insert explicit values.INSERT using SELECTstatement: This approach is commonly used to copy a table’s content into another table or a partition. Let’s say you have created an empty table and plan to add data from an existing table, for example from a public data set. You can use the INSERT INTO … SELECT statement to append new data to the target table.INSERT using subqueries or common table expressions (CTE):As seen in the previous post, WITH statement allows you to name a subquery and use it in subsequent queries such as the SELECT or INSERT statement here (also called Common Table Expressions). In the example below, values to be inserted are computed using a subquery that performs JOIN operation with multiple tables.DELETE statementDELETE statement allows you to delete rows from a table. When using a DELETE statement, you must use WHERE clause followed by a condition. DELETE all rows from a tableDELETE FROM `project.dataset.table` WHERE true;DELETE with WHEREclause: This approach uses WHERE clause to identify the specific rows to be deleted.DELETE FROM `project.dataset.table` WHERE price = 0;DELETE with subqueries:This approach uses a subquery to identify the rows to be deleted. The subquery can query other tables or perform JOINs with other tables.DELETE `project.dataset.table`tWHERE t.id NOT IN (SELECT id from `project.dataset.unprocessed`)UPDATE statementUPDATE statement allows you to modify existing rows in a table. Similar to DELETE statement, each UPDATE statement must include the WHERE clause followed by a condition. To update all rows in the table, use WHERE true.Following are few patterns to update rows in a BigQuery table:UPDATE with WHERE clause: Use WHERE clause in the UPDATE statement to identify specific rows that need to be modified and use SET clause to update specific columns.UPDATE using JOINs: In a data warehouse, it’s a common pattern to update a table based on conditions from another table. In the previous example, we updated quantity and price columns in the product table. Now we will update the transactions table based on the latest values in the product table. (NOTE: A row in the target table to be updated must match with at most one row when joining with the source table in the FROM clause. Otherwise runtime error is generated)UPDATE nested and repeated fields: As seen in the previous post, BigQuery supports nested and repeated fields using STRUCT and ARRAY to provide a natural way of denormalized data representation. With BigQuery DML, you can UPDATE nested structures as well. In the product table, specs is a nested structure with color and dimension attributes and the dimension attribute is a nested structure. The below example UPDATEs the nested field for specific rows identified by WHERE clause.MERGE statementMERGE statement is a powerful construct and an optimization pattern that combines INSERT, UPDATE and DELETE operations on a table into an “upsert” operation based on values matched from another table. In an enterprise data warehouse with a star or snowflake schema, a common use case is to maintain Slowly Changing Dimension (SCD) tables that preserves the history of data with reference to the source data i.e. insert new records for new dimensions added, remove or flag dimensions that are not in the source and update the values that are changed in the source. The MERGE statement can be used to manage these operations on a dimension table with a single DML statement.Here is the generalized structure of the MERGE statement:A MERGE operation performs JOIN between the target and the source based on merge_condition. Then depending on the match status – MATCHED, NOT MATCHED BY TARGET and NOT MATCHED BY SOURCE – corresponding action is taken. The MERGE operation must match at most one source row for each target row. When there is more than one row matched, the operation errors out. The following picture illustrates MERGE operation on the source and target tables with the corresponding actions – INSERT, UPDATE and DELETE:MERGE operation can be used with source as subqueries, joins, nested and repeated structures. Let’s look at MERGE operation with INSERT else UPDATE pattern using subqueries. In the below example, MERGE operation INSERTs the row when there are new rows in source that are not found in target and UPDATEs the row when there are matching rows from both source and target tables.You can also include an optional search condition in WHEN clause to perform operations differently. In the below example, we derive the price of ‘Furniture’ products differently compared to other products. Note that when there are multiple qualified WHEN clauses, only the first WHEN clause is executed for a row.The patterns seen so far in this post is not an exhaustive list. Refer to BigQuery documentation for DML syntax and more examples.Things to know about DML in BigQueryUnder the HoodBigQuery performs the following steps when executing a DML job. This is only a representative flow of what happens behind the scenes when you execute a DML job in BigQuery.Note that when you execute a DML statement in BigQuery, an implicit transaction is initiated that commits the transaction automatically when successful. Refer this article to understand how BigQuery executes a DML statement.Quotas and LimitsBigQuery enforces quotas for a variety of reasons such as to prevent unforeseen spikes in usage to protect the community of Google Cloud users. There are no quota limits on BigQuery DML statements i.e. BigQuery supports an unlimited number of DML statements on a table. However, you must be aware of following quotas enforced by BigQuery when designing the data mutation operations:DML statements are not subjected to a quota limit but they do count towards the quota – tables operations per day and partition modifications per day. DML statements will not fail due to these limits but other jobs can.Concurrent DML JobsBigQuery manages the concurrency of DML statements that mutate rows in a table. BigQuery is a multi-version and ACID-compliant database that uses snapshot isolation to handle multiple concurrent operations on a table. Concurrently running mutating DML statements on a table might fail due to conflicts in the changes they make and BigQuery retries these failed jobs. Thus, the first job to commit wins which could mean that when you run a lot of short DML operations, you could starve longer-running ones. Refer this article to understand how BigQuery manages concurrent DML jobs.How many concurrent DML jobs can be run?INSERT DML job concurrency: During any 24 hour period, you can run the first 1000 INSERT statements into a table concurrently. After this limit is reached, the concurrency of INSERT statements that write to a table is limited to 10. Any INSERT DML jobs beyond 10 are queued in PENDING state. After a previously running job finishes, the next PENDING job is dequeued and run. Currently, up to 100 INSERT DML statements can be queued against a table at any given time.UPDATE, DELETE and MERGE DML job concurrency: BigQuery runs a fixed number of concurrent mutating DML statements (UPDATE, DELETE or MERGE) on a table. When the concurrency limit is reached, BigQuery automatically queues the additional mutating DML jobs in a PENDING state. After a previously running job finishes, the next PENDING job is dequeued and run. Currently, BigQuery allows up to 20 mutating DML jobs to be queued in PENDING state for each table and any concurrent mutating DMLs beyond this limit will fail. This limit is not affected by concurrently running load jobs or INSERT DML statements against the table since they do not affect the execution of mutation operations. What happens when concurrent DML jobs get into conflicts?DML conflicts arise when the concurrently running mutating DML statements (UPDATE, DELETE, MERGE) try to mutate the same partition in a table and may experience concurrent update failures. Concurrently running mutating DML statements will succeed as long as they don’t modify data in the same partition. In case of concurrent update failures, BigQuery handles such failures automatically by retrying the job by first determining a new snapshot timestamp to use for reading the tables used in the query and then applying the mutations on the new snapshot. BigQuery retries concurrent update failures on a table up to three times. Note that inserting data to a table does not conflict with any other concurrently running DML statement. You can mitigate conflicts by grouping DML operations and performing batch UPDATEs or DELETEs.Pricing DML StatementsWhen designing DML operations in your system, it is key to understand how BigQuery prices DML statements to optimize costs as well as performance. BigQuery pricing for DML queries is based on the number of bytes processed by the query job with DML statement. Following table summarizes the calculation of bytes processed based on table being partitioned or non-partitioned:Since the DML pricing is based on the number of bytes processed by the query job, the best practices of querying the data with SELECT queries applies to DML query jobs as well. For example, limiting the bytes read by querying only data that is needed, partition pruning with partitioned tables, block pruning with clustered tables and more. Following are best practices guides for controlling bytes read by a query job and optimizing costs:Managing input data and data sources | BigQueryEstimating storage and query costs | BigQueryCost optimization best practices for BigQueryDMLs on Partitioned and Non-Partitioned TablesIn the previous BigQuery Explained post, we perceived how BigQuery partitioned tables make it easier to manage and query your data, improve the query performance and control costs by reducing bytes read by a query. In the context of DML statements, partitioned tables can accelerate the update process when the changes are limited to the specific partitions. For example, a DML statement can update data in multiple partitions for both ingestion-time partitioned and partitioned tables (date, timestamp, datetime and integer range partitioned).Let’s refer to the example from the partitioning section of BigQuery Explained: Storage Overview post where we created non-partitioned and partitioned tables from a public data set based on StackOverflow posts. Non-Partitioned TablePartitioned TableLet’s run an UPDATE statement on non-partitioned and partitioned tables to modify a column for all the StackOverflow posts created on a specific date.Non-Partitioned TablePartitioned TableIn this example, with the partitioned table the query with DML job scans and updates only the required partition processing ~11 MB data compared to the DML job on the non-partitioned table that processes ~3.3 GB data doing a full table scan. Here the DML operation on the partitioned table is faster and cheaper than the non-partitioned table.Using DML statements (INSERT, UPDATE, DELETE, MERGE) with partitioned and non-partitioned tables follow the same DML syntax as seen in the post earlier. Except when working with an ingestion-time partitioned table, you specify the partition refering the _PARTITIONTIME pseudo column. For example, see the INSERT statement below for ingestion-time partitioned table and a partitioned table.INSERT with ingestion-time partitioned tableINSERT with partitioned TableWhen using a MERGE statement against a partitioned table, you can limit the partitions involved in the DML statements by using partition pruning conditions in a subquery filter, a search_condition filter, or a merge_condition filter.Refer BigQuery documentation for using DML with partitioned tables and non-partitioned tables.DML and BigQuery Streaming insertsIn the BigQuery Explained: Data Ingestion post, we touched upon the streaming ingestion pattern that allows continuous styles of ingestion by streaming data into BigQuery in real-time, using the tabledata.insertAll method. BigQuery allows DML modifications on tables with active streaming buffer based on recency of writes in the table.Rows written to the table recently using streaming cannot be modified. Recent writes are typically those that occur within the last 30 minutes. All other rows in the table are modifiable with mutating DML statements (UPDATE, DELETE or MERGE).Best Practices Using DML in BigQueryAvoid point-specific DML statements. Instead group DML operations.Even though you can now run unlimited DML statements in BigQuery, consider performing bulk or large-scale mutations for the following reasons: BigQuery DML statements are intended for bulk updates. Using point-specific DML statements is an attempt to treat BigQuery like an Online Transaction Processing (OLTP) system. BigQuery focuses on Online Analytical Processing (OLAP) by using table scans and not point lookups.Each DML statement that modifies data initiates an implicit transaction. By grouping DML statements you can avoid unnecessary transaction overhead.DML operations are charged based on the number of bytes processed by the query which can be a full table or partition or cluster scan. By grouping DML statements you can limit the number of bytes processed.DML operations on a table are subjected to rate limiting when multiple DML statements are submitted too quickly. By grouping operations, you can mitigate the failures due to rate limiting.The following are a few ways to perform bulk mutations:Batch mutations by using the MERGE statement based on contents of another table. MERGE statement is an optimization construct that can combine INSERT, UPDATE, and DELETE operations into one statement and perform them atomically.Using subqueries or correlated subqueries with DML statements where the subquery identifies the rows to be modified and the DML operation mutates data in bulk.Replace single row INSERTs with bulk inserts using explicit values or subqueries or common table expressions (CTE) as discussed earlier in the post. For example, if you have the following point specific INSERT statements, running them as is in BigQuery is an anti-pattern:You can translate into a single INSERT statement that performs a bulk operation instead:If your use case involves frequent single row inserts, consider streaming your data instead. Please note there is a charge for streamed data unlike load jobs which are free.Refer BigQuery documentation on examples of performing batch mutations.Batch your updates and inserts.Performing large-scale mutations in BigQueryUse CREATE TABLE AS SELECT (CTAS) for large-scale mutations.DML statements can get significantly expensive when you have large scale modifications. For such cases, prefer CTAS (CREATE TABLE AS SELECT) instead. So instead of performing a large number of UPDATE or DELETE statements, you run a SELECT statement and save the query results into a new target table with modified data using CREATE TABLE AS SELECT operation. After creating the new target table with modified data, you would discard the original target table. SELECT statements can be cheaper than processing DML statements in this case. Another typical scenario where a large number of INSERT statements is used is when you create a new table from an existing table. Instead of using multiple INSERT statements, create a new table and insert all the rows in one operation using the CREATE TABLE AS SELECT statement.Use TRUNCATE when deleting all rows.When performing a DELETE operation to remove all the rows from a table, use TRUNCATE TABLE statement instead. The TRUNCATE TABLE statement is a DDL (Data Definition Language) operation that removes all rows from a table but leaves the table metadata intact, including the table schema, description, and labels. Since TRUNCATE is a metadata operation it does not incur a charge.TRUNCATE TABLE `project.dataset.mytable`Partition your data.As we have seen earlier in the post, partitioned tables can significantly improve performance of DML operation on the table and optimize cost as well. Partitioning ensures that the changes are limited to specific partitions within the table. For example, when using MERGE statement you can lower cost by precomputing the partitions affected prior to the MERGE and include a filter for the target table that prunes partition in a subquery filter, a search_condition filter, or a merge_condition filter of MERGE statement. If you don’t filter the target table the mutating DML statement will do a full table scan. In the following example, you are limiting the MERGE statement to scan only the rows in the ‘2018-01-01′ partition in both the source and the target table by specifying a filter in the merge condition.When UPDATE or DELETE frequently modify older data, or within a particular range of dates, consider partitioning your tables. Avoid partitioning tables if the amount of data in each partition is small and each update modifies a large fraction of the partitions.Cluster tablesIn the previous post of BigQuery Explained, we have seen clustering data can improve performance of certain queries by sorting and collocating related data in blocks. If you often update rows where one or more columns fall within a narrow range of values, consider using clustered tables. Clustering performs block level pruning and scans only data relevant to the query reducing the number of bytes processed by the query. This improves DML query performance as well as optimizes costs. You can use clustering with or without partitioning the table and clustering the tables is free. Refer example of DML query with clustered tableshere. Be mindful of your data editsIn the previous post of BigQuery Explained, we mentioned long term storage can offer significant price savings when your table or partition of a table has not been modified for 90 days. There is no degradation of performance, durability, availability or any other functionality when a table or partition is considered for long-term storage. To get the most out of long-term storage, be mindful of any actions that edit your table data, such as streaming, copying, or loading data, including any DML or DDL actions. Any modification can bring your data back to active storage and reset the 90-day timer. To avoid this, you can consider loading the new batch of data to a new table or a partition of a table. Consider Cloud SQL for OLTP use casesIf your use case warrants OLTP functionality, consider using Cloud SQL federated queries, which enable BigQuery to query data that resides in Cloud SQL. Check out this video for querying Cloud SQL from BigQuery.Querying Cloud SQL from BigQueryWhat’s Next?In this article, we learned how you can add, modify and delete data stored in BigQuery using DML statements, how BigQuery executes DML statements, best practices and things to know when working with DML statements in BigQuery.Check out BigQuery documentation on DML statementsUnderstand quotas, limitations and pricing of BigQuery DML statements Refer to this blog post on BigQuery DML without limitsIn the next post, we will look at how to use scripting, stored procedures and user defined functions in BigQuery.Stay tuned. Thank you for reading! Have a question or want to chat? Find me on Twitter or LinkedIn.Thanks to Pavan Edara and Alicia Williams for helping with the post.Related Article[New blog series] BigQuery explained: An overviewOur new blog series provides an overview of what’s possible with BigQuery.Read Article
Quelle: Google Cloud Platform