A new Terraform module for serverless load balancing
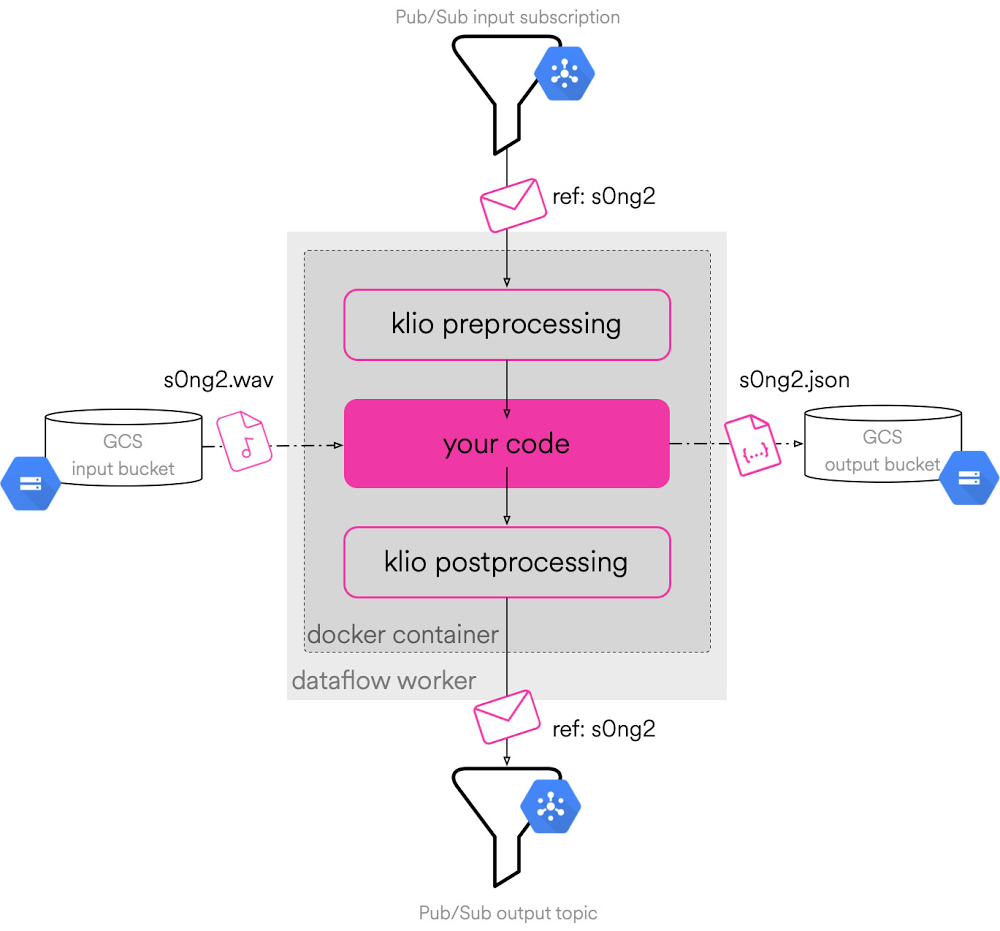
Today we are announcing a new Terraform module for provisioning load balancers optimized for serverless applications. With this Terraform module, you can complete your load balancing task with a single module, instead of configuring many underlying network resources yourself in Terraform.In an earlier article, we showed you how to build a Cloud HTTPS Load Balancer for your serverless applications from the ground up using Terraform. It was cumbersome, requiring you to know many networking APIs and wire them up. This new Terraform module solves this problem by abstracting away the details of building a load balancer and gives you a single Terraform resource to interact with.You can now easily place your serverless applications (Cloud Run, App Engine, or Cloud Functions) behind a Cloud Load Balancer that has an automatic TLS certificate, and lets you set up features like Cloud CDN, Cloud IAP, or custom certificates with only a few lines of configuration.A quick exampleFor illustration purposes, let’s say you have a serverless network endpoint group (NEG) for your Cloud Run application. Provisioning a global HTTPS load balancer for this application on your custom domain with this new Terraform module looks like this:As you can see from the code snippet above, it takes just a few lines of configuration to set up a managed TLS certificate, deploy your own TLS certificate(s), enable CDN, and define Identity-Aware Proxy or Cloud Armor security policies.Harnessing the power of TerraformWith this new Terraform module, you can take deployment automation to the next level by taking advantage of HCL syntax and Terraform features.For example, a common use case for using global load balancers is to serve traffic from multiple regions. However, automating deployment of your app to 20+ regions and keeping your load balancer configuration up-to-date may require a nontrivial amount of bash scripting. This is where Terraform shines!In this next example, we deploy a Cloud Run app to all available regions and add them behind a global load balancer. To do that, we simply create a variable named regions that holds the list of deployment locations.Then, we create a Cloud Run service (and its network endpoint group), using the for_each syntax:Then, we add all the network endpoint groups with a simple for loop syntax:By implementing this technique, we create 60+ API resources for 20+ regions with a couple lines of simple modifications to our Terraform configuration, a task that would otherwise require a lot of bash scripting.If you’re interested in the full implementation of this example, check out my Cloud Run multi-region deployment with Terraform repository.ConclusionWith the serverless network endpoint groups launch, we allow you to create an HTTP or HTTPS load balancer in front of your serverless applications on Google Cloud. And with this new Terraform module, we’re making this interaction even easier.To get started, make sure to check out the module GitHub repository or module registry for the detailed and up-to-date documentation and take a look at the Cloud Run example of the module to get started. We welcome your feedback; please report issues in our GitHub repository.Related ArticleServerless load balancing with Terraform: The hard wayWhat Cloud Load Balancer integration means for Cloud Run, and how to build a load balancer from scratch using Terraform resources.Read Article
Quelle: Google Cloud Platform