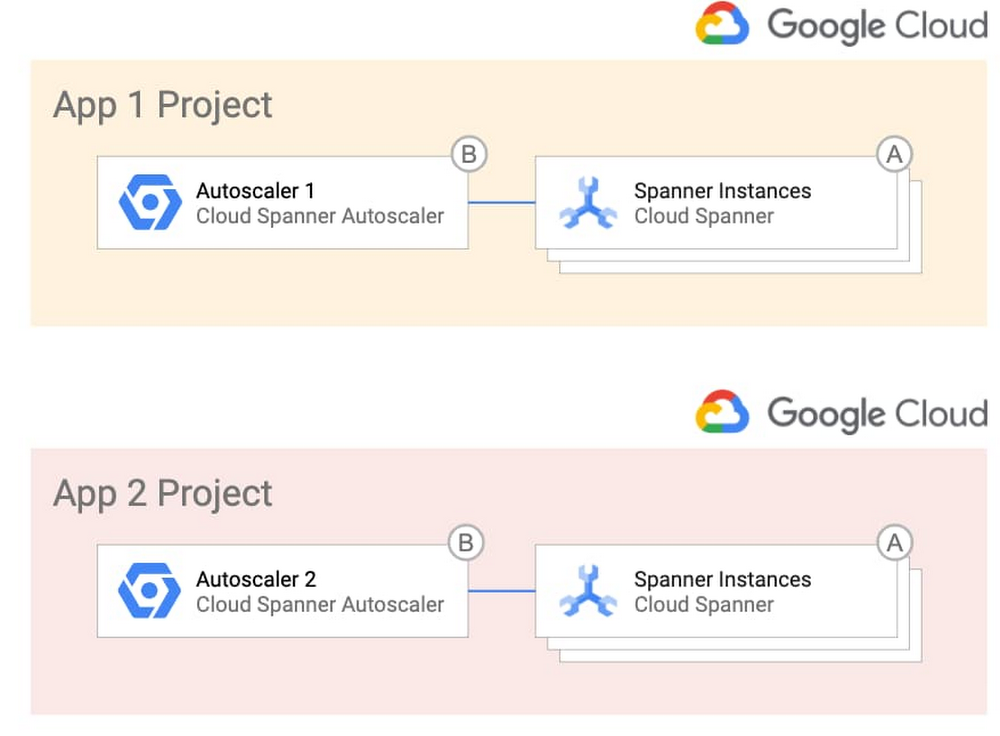
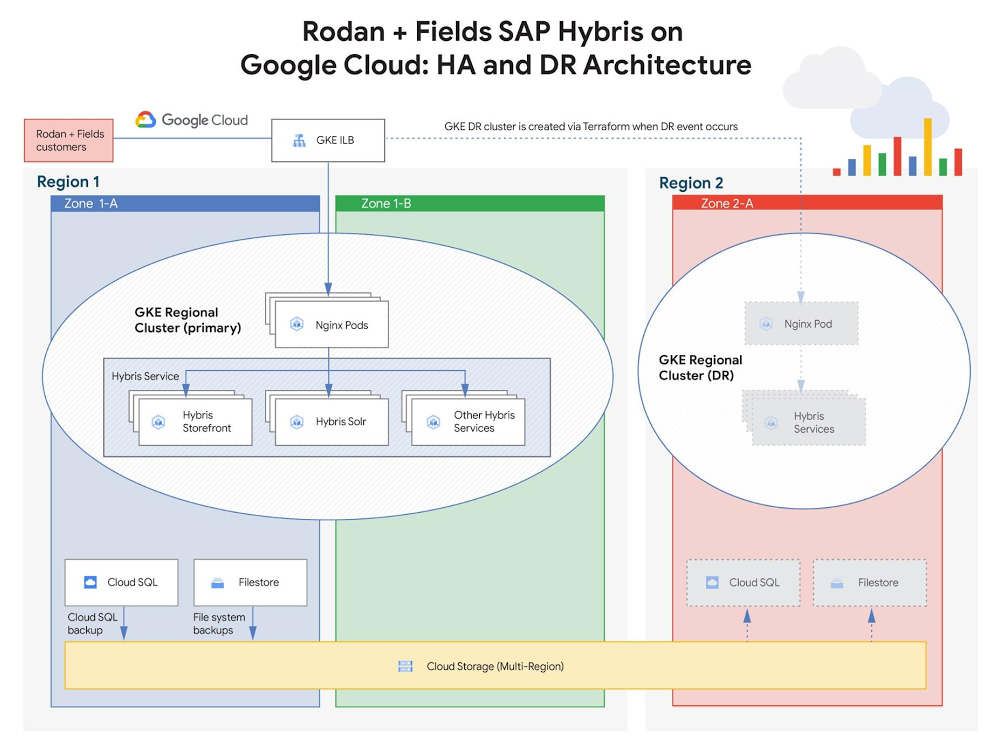
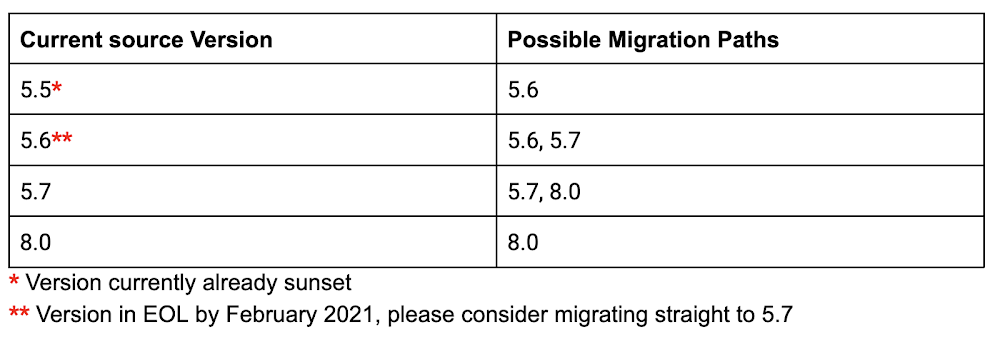
The Wellcome Sanger Institute: Creating the right conditions for groundbreaking research with Anthos
Editor’s note: Today we speak with Dr. Vladimir Kiselev, head of the Cellular Genetics Programme’s Informatics team at the Wellcome Sanger Institute, to hear how Google Cloud’s multi-cloud solution, Anthos, will help researchers collaborate and share their analyses more effectively.The Wellcome Sanger Institute has been at the very forefront of scientific discovery since 1992. Originally created to sequence DNA for the Human Genome Project, it’s now one of the world’s biggest centers for genomic science, employing almost 1,000 scientists, engineers, and research professionals across five separate programs. One of these is the Cellular Genetics Programme, which combines cutting-edge “cell-atlasing” methodologies with computational techniques to map cells in the human body and further our understanding of how they work.The programme calls for cutting-edge technology, and that’s where Dr. Vladimir Kiselev, who heads the informatics team for the Cellular Genetics Programme, comes in. “We provide the technological infrastructure that lets researchers do their work,” he says. “Our tasks are varied, from setting up imaging data pipelines to helping researchers to analyze sequencing data, and running websites for them. It’s a mixed environment with plenty of scope and freedom to support the research team with whatever it needs.”One of the most popular initiatives spearheaded by the informatics team has been to enable secondary data analysis through JupyterHub, an open-source virtual notebook that allows researchers to fully document and share their analyses online. With a user-friendly interface, JupyterHub makes it easy for researchers with minimal bioinformatics experience to access a Sanger cloud service with sufficient power to handle large datasets. This has not only assisted the work of faculty members within the Cellular Genetics Programme, it has also made working with external collaborators much easier. Today, 90 registered users rely on JupyterHub, and 15% of them are from other institutes based anywhere from Newcastle to Oxford, working on collaborative projects with the Wellcome Sanger Institute. But any solution has to fit within the confines of the institute’s uniquely complex IT infrastructure. After the original deployment of JupyterHub, users began to see a drop in stability due to increased demand, with 50 user pods running in parallel at any given time. The informatics team tested various configurations within the existing infrastructure and with commercial solutions but saw little improvement. Looking to gain a powerful yet flexible infrastructure, earlier this year the team turned to Anthos, Google Cloud’s hybrid and multi-cloud platform. Finding the balance between functionality and stabilityAs a major scientific establishment, the Wellcome Sanger Institute has access to powerful High Performance Compute clusters and a private data center that runs the open-source operating system OpenStack. This enabled it to adopt the ideal solutions for its needs, from a range of different providers. To run the Cellular Genetics JupyterHub, for example, the informatics team selected Kubernetes, the open-source container orchestration platform developed by Google. But as powerful as the Institute’s existing stack is, integrating JupyterHub was a complex task that required significant resources to set up and maintain. As the demand for JupyterHub grew, maintenance became harder and instability common. Additionally, the legacy Openstack on-premise solution with Kubespray did not allow for upgrades in place. As a result , users were increasingly affected, which slowed down research.The Institute needed a solution that would allow it to run JupyterHub clusters reliably and at scale on its own hardware, without disrupting the existing infrastructure. The informatics team worked with Google Cloud Premier Partner Appsbroker to come up with the best approach. Together, they realized that Anthos could be the ideal answer for introducing an enterprise-grade conformant Kubernetes solution in their data center, allowing for in-place upgrades and removing reliance on OpenStack.Following a series of training sessions, the informatics team worked with Appsbroker to run a Proof of Concept (POC) with a handful of JupyterHub accounts. Back when they first set up JupyterHub, it had taken four months to configure it for the complex IT infrastructure. But using Anthos, the Institute could run GKE on-prem natively on VMware (the de facto infrastructure platform at the Institute), and the team had JupyterHub up and running in just five days, including all notebooks and secure researcher access. Harnessing the power of Google Cloud in a hybrid architectureEven in the POC, the benefits of JupyterHub on Anthos were immediate. “Stability has significantly improved with Anthos,” says Vladimir, explaining that Kubernetes maintenance is now an Anthos service supported by the institute’s central IT team via Google Cloud Console. “It’s great not having to worry about our cluster anymore. Better yet, users don’t have to worry about not being able to log on and get their important work done.”Anthos also offers an ease of use and reliability that the informatics team had not experienced with previous solutions. This enables them to spend more time developing new solutions for the research faculty instead of standing by for maintenance. Finally, being able to run Anthos on the Institute’s own hardware rather than on the cloud means that it pays a fixed license fee, which helps with long-term planning and strategizing. “When project funding is discussed at the informatics committee, it’s much easier for everyone to make decisions when they can see a predictable, monthly cost,” explains Vladimir. A proof of concept with Anthos, a way forward for the programAfter its successful POC with Google Cloud and Appsbroker, the Cellular Genetics Programme is currently working toward full deployment of JupyterHub on Anthos. And now that the team has some experience with Google Cloud, it’s easier to experiment with new projects, such as hosting internal and external websites for researchers or introducing more automation into the stages of application development by deploying GitLab on Anthos to run CI/CD pipelines.“I really like the integration with the Google Cloud Console,” says Kiselev. “We can control everything we need to from one place, whether that’s JupyterHub, a pipeline, or anything else. Having a single platform to manage everything is definitely a vision we want to aim for.”
Quelle: Google Cloud Platform