Beyond Corp Enterprise: True zero trust architecture for the multicloud
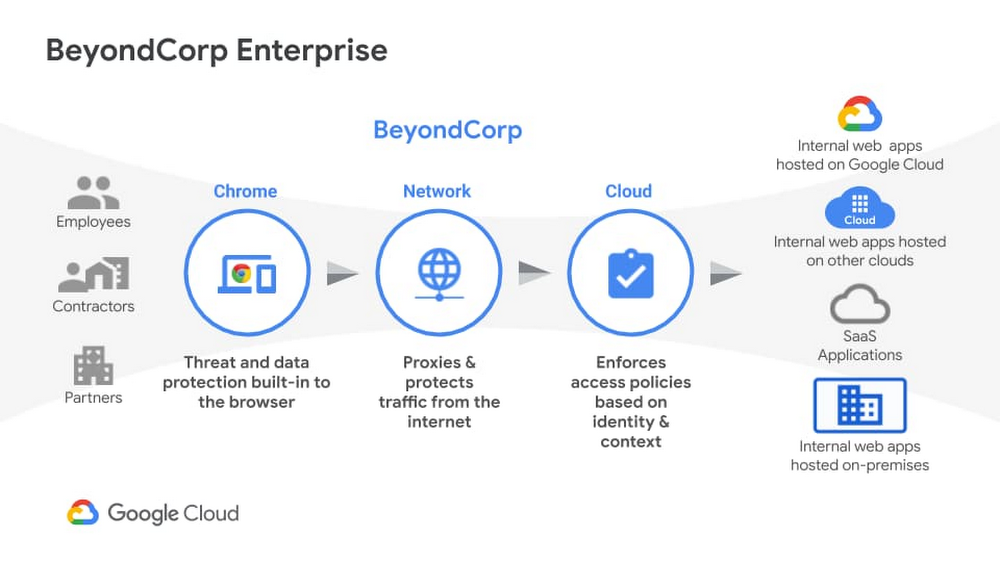
We recently announced the general availability of BeyondCorp Enterprise, Google’s comprehensive zero trust product offering. As we work to democratize zero trust, building a solution to support customers across different environments was top of mind for our team. Google has over a decade of experience managing and securing cloud applications at a global scale and this new offering was developed based on learnings from our experience managing our own enterprise, feedback from customers and partners, as well as informed by leading engineering and security research. We recognize the complexities that come with a zero trust journey and understand that most customers host resources across different cloud providers. With this in mind, BeyondCorp Enterprise was purpose-built as a multicloud solution, enabling customers to securely access resources hosted not only on Google Cloud or on-premises, but also across other clouds such as Azure and Amazon Web Services (AWS). Beyond Corp Enterprise provides context-aware access controls for internal and SaaS applications and cloud resources, and offers integrated threat and data protection without the for a Virtual Private Network (VPN). This solution is hosted on Google’s global network infrastructure and enables elastic-scaling based on use, helping customers manage secure access for different user groups, including employees, contractors or temporary workers, and partners. The diagram below shows the high-level architecture of BeyondCorp Enterprise. As you can see, BeyondCorp Enterprise supports applications and resources hosted on Google Cloud, on other clouds, or on-premises.Click to enlargeSo what does this mean for you and how can BeyondCorp Enterprise help? Google continues to emphasize its commitment for multi-cloud environments with BeyondCorp Enterprise. Customers “live” in a diverse world of different clouds and different vendors and we know it’s unrealistic that customers would have 100 percent of their resources hosted in one provider. That’s why we have been mindful to not only support access to apps on other clouds, but also build integrations with other leading technology vendors so customers can leverage their existing investments. The potential for the zero trust architecture is limitless as our ecosystem is built such that it is easily extensible by security partners, and the rulesets can be enriched to include additional signals like threat and data loss. Using a combination of user and device attributes, BeyondCorp Enterprise uses criteria such as the user’s location when trying to access a resource, the time of day the user is trying to access the resource, or the type of device a user is using to access a resource. BeyondCorp Enterprise also leverages Endpoint Verification in the Chrome Browser to identify the posture of the device accessing an application. These various parameters are used to configure “grant” or “deny” rules and policies, which are then enforced by the cloud Identity Aware Proxy and a combination of other controls.Click to enlargeEnterprise customers who adopt a “best of breed” approach to security will find Google’s approach to zero trust and the BeyondCorp Enterprise architecture complementary to their strategy. As an example, if you use one of our BeyondCorp Alliance partners as your endpoint detection and response solution or Unified Endpoint Management (UEM) solution, you can also integrate signals from these solutions to incorporate into your policies and protect your resources across your on-premises, Google Cloud, or other clouds. This architecture ensures that you have the autonomy to choose your preferred security vendors.Once secure access is granted, BeyondCorp Enterprise provides threat and data protection capabilities, including the ability to protect SaaS applications and other websites from data loss, data exfiltration, credential theft, malware, and phishing attacks. Because these capabilities are delivered through the Chrome Browser, we can support users on Windows, Mac, Linux, and ChromeOS, again making it easy to meet customers where they are and enable simple deployment and adoption.Many people think zero trust requires a complete overhaul of their environment and would entail installing multiple agents on a computer; but instead, all you need is a web browser. We are excited to bring disruptive innovation to our customers in a way that does not disrupt security operations. rotectionGoogle is a true engineering-driven company. Innovating and solving global-scale problems is at the core of the company’s DNA. Ideas and projects that led to the creation of products that have redefined how people across the world work, such as Gmail, Google Maps, and of course, the Chrome Browser, which also birthed BeyondCorp Enterprise. If you would like to learn more about BeyondCorp Enterprise, visit the product page, register for our upcoming webinar on Feb 23, or contact your Google account team.Related ArticleBeyondCorp Enterprise: Introducing a safer era of computingThe GA of Google’s comprehensive zero trust product offering, BeyondCorp Enterprise, brings this modern, proven technology to organizatio…Read Article
Quelle: Google Cloud Platform