Bigtable vs. BigQuery: What’s the difference?
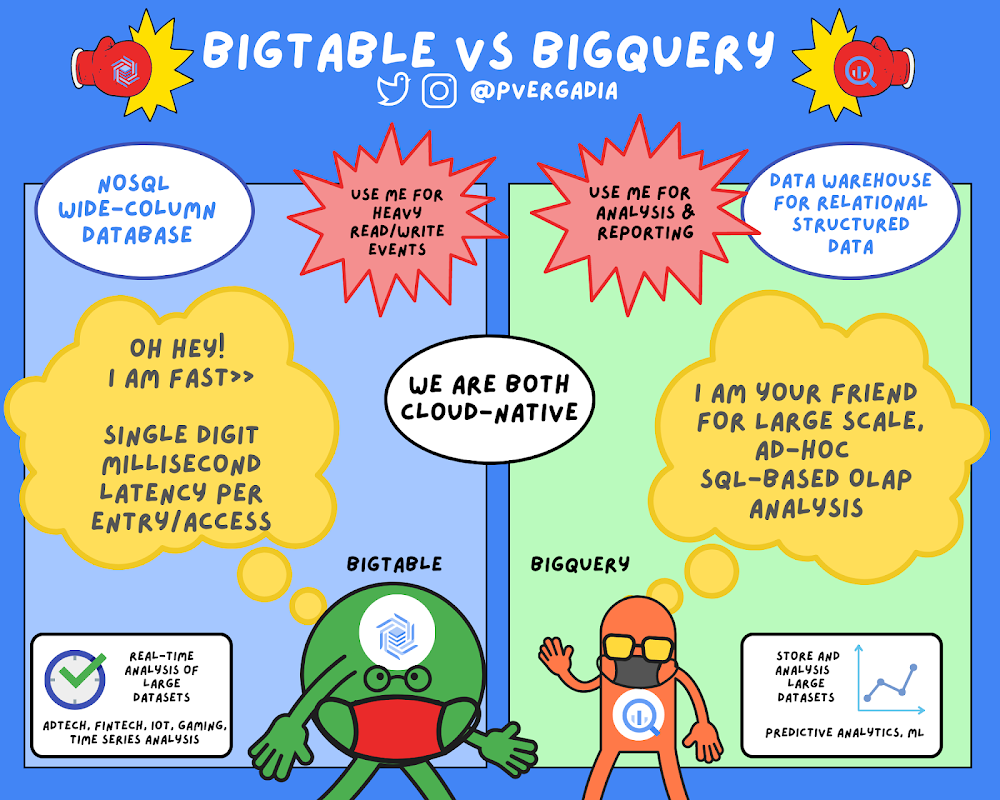
Many people wonder if they should use BigQuery or Bigtable. While these two services have a number of similarities, including “Big” in their names, they support very different use cases in your big data ecosystem.At a high level,Bigtable is a NoSQL wide-column database. It’s optimized for low latency, large numbers of reads and writes, and maintaining performance at scale. Bigtable use cases are of a certain scale or throughput with strict latency requirements, such as IoT, AdTech, FinTech, and so on. If high throughput and low latency at scale are not priorities for you, then another NoSQL database like Firestore might be a better fit.Bigtable is a NoSQL wide-column database optimized for heavy reads and writes.On the other hand, BigQuery is an enterprise data warehouse for large amounts of relational structured data. It is optimized for large-scale, ad-hoc SQL-based analysis and reporting, which makes it best suited for gaining organizational insights. You can even use BigQuery to analyze data from Cloud Bigtable.BigQuery is an enterprise data warehouse for large amounts of relational structured data.(Click to enlarge)Characteristics of Cloud BigtableBigtable is a NoSQL database that is designed to support large, scalable applications. Use Bigtable when you are making any application that needs to scale in a big way in terms of reads and writes per second. Bigtable throughput can be adjusted by adding/removing nodes — each node provides up to 10,000 queries per second (read and write). You can use Bigtable as the storage engine for large-scale, low-latency applications as well as throughput-intensive data processing and analytics. It offers high availability with an SLA of 99.5% for zonal instances. It’s strongly consistent in a single cluster; replication adds eventual consistency across two clusters, and increases SLA to 99.99%.Cloud Bigtable is a key-value store that is designed as a sparsely populated table. It can scale to billions of rows and thousands of columns, enabling you to store terabytes or even petabytes of data. This design also helps store large amounts of data per row or per item, making it great for machine learning predictions. It is an ideal data source for MapReduce-style operations and integrates easily with existing big data tools such as Hadoop, Dataflow, and Dataproc. It also supports the open-source HBase API standard to easily integrate with the Apache ecosystem.For a real world example, see how Ricardo, the largest online marketplace in Switzerland benchmarked and came to a conclusion that Bigtable is much more easier to manage and more cost-effective than self-managed Cassandra. Characteristics of BigQueryBigQuery is a petabyte-scale data warehouse designed to ingest, store, analyze, and visualize data with ease. Typically, you’ll collect large amounts of data from across your databases and other third-party systems to answer specific questions. You can ingest this data into BigQuery by uploading it in a batch or by streaming data directly to enable real-time insights. BigQuery supports a standard SQL dialect that is ANSI-compliant, so if you already know SQL, you are all set. It is safe to say that you would serve an application that uses Bigtable as the database but most of the times you wouldn’t have applications performing BigQuery queries. Cloud Bigtable shines in the serving path and BigQuery shines in analytics.Once your data is in BigQuery, you can start performing queries on it. BigQuery is a great choice when your queries require you to scan a large table or you need to look across the entire dataset. This can include queries such as sums, averages, counts, groupings or even queries for creating machine learning models. Typical BigQuery use cases include large-scale storage and analysis or online analytical processing (OLAP)For a real-world example, see how Verizon Media used BigQuery for a Media Analytics Pipeline migrating massive Hadoop and enterprise data warehouse (EDW) workloads to Google Cloud’s BigQuery and Looker.Common characteristicsBigQuery and Bigtable are both cloud-native and they both feature unique, industry-leading SLAs. Because updates and upgrades happen transparently behind the scenes, you don’t have to worry about maintenance windows or planning downtime for either service. In addition, they offer unlimited scale, automatic sharding, and automatic failure recovery (with replication). For fast transactions and faster querying, both BigQuery and Bigtable separate processing and storage, which helps maximize throughput.ConclusionIf this has piqued your interest and you are excited to learn about the upcoming innovations to support your data strategy join us in the Data Cloud Summit on May 26th. For more information on BigQuery and Bigtable, check out the individual GCP sketchnotes on thecloudgirl.dev. For similar cloud content, follow me on Twitter @pvergadiaRelated ArticleSpring forward with BigQuery user-friendly SQLThe newest set of user-friendly SQL features in BigQuery are designed to enable you to load and query more data with greater precision, a…Read Article
Quelle: Google Cloud Platform