Choosing the right orchestrator in Google Cloud
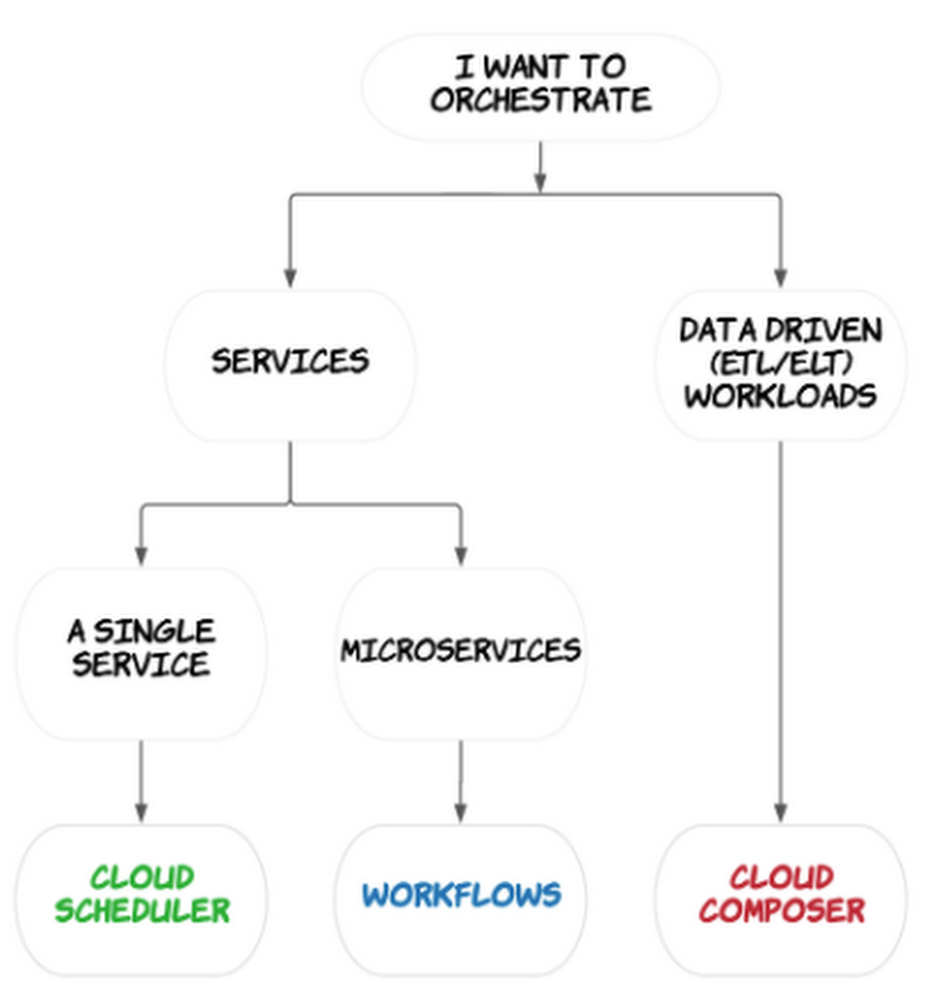
What is orchestration? Orchestration often refers to the automated configuration, coordination, and management of computer systems and services. In the context of service-oriented architectures, orchestration can range from simply executing a single service at a specific time and day, to a more sophisticated approach of automating and monitoring multiple services over longer periods of time, with the ability to react and handle failures as they crop up. In the data engineering context, orchestration is central to coordinating the services and workflows that prepare, ingest, and transform data. It can go beyond data processing and also involve a workflow to train a machine learning (ML) model from the data.There is no shortage of orchestration tools in Google Cloud. In this blog post, we will explore service and data orchestration tools and help you choose what’s best for your use case.Orchestration in Google CloudGoogle Cloud Platform offers a number of tools and services for orchestration:Cloud Scheduler for schedule driven single-service orchestrationWorkflows for complex multi-service orchestration Cloud Composer for orchestration of your data workloadsLet’s take a closer look at each of these tools.Cloud SchedulerCloud Scheduler is a service for scheduling the execution of a single service on a recurring schedule — this is about as simple as it gets for orchestration in Google Cloud.Cloud Scheduler uses cron scheduling to trigger the execution of HTTP-based services at a schedule you define.We often see customers using Scheduler alongside Pub/Sub and Cloud Functions to execute their code serverlessly on Google Cloud.Cloud Scheduler is a good fit if you just need to call a single service at regular intervals. But what if you have multiple services that you want to chain together, feeding the output of one service to the next? Or what if you need to apply complex logic to determine how and when services are invoked? Then, you should start considering Workflows.WorkflowsWorkflows is a service for orchestrating multiple HTTP-based services into a durable and stateful workflow.Like Cloud Scheduler, Worklows enables you to automate the execution of HTTP-based services running on Cloud Functions and Cloud Run, as well as external services and APIs. Unlike Scheduler, Workflows has sophisticated logic that lets you manage the execution of multiple services as part of a wider workflow. You can use either YAML or JSON to express your workflow. You can specify the order of services as steps and define how to handle step failures. The result of one step can be used as an input to other steps throughout the workflow, or as a condition to determine which step to execute next.Workflows is great for chaining microservices together, automating infrastructure tasks such as starting or stopping a VM, and integrating reliably with external systems. It acts as a central source of truth for service integrations, improving observability and error handling in services. It is also completely serverless, so you don’t have to worry about maintaining resources. To execute a workflow you can manually trigger the workflow (via API or UI) or you can set up a recurring schedule with Cloud Scheduler.Workflows is very useful in service-oriented architectures but if your focus is more on engineering data pipelines or big data processing then you should consider using Composer.Cloud Composer Composer is a service designed to orchestrate data driven (particularly ETL/ELT) workflows and is built on the popular open source Apache Airflow project.Composer is fully managed so you don’t have to worry about installing or maintaining Airflow deployments and it supports your pipelines wherever they are, be that on on-premises or across multiple cloud platforms.Like Workflows, you can create a task for each step in your workflow, configure the order of tasks, and specify which task to execute next based on some conditions.Your tasks are expressed in a Python Directed Acyclic Graph (DAG) that can be scheduled to run at a time of your choice:You would use Composer to orchestrate the services that make up your data pipelines, for example, triggering a job in BigQuery or starting a Dataflow pipeline. Operators can be used to communicate with services across multiple cloud environments and on-prem; there are over 150 operators for Google Cloud alone. For example, by passing a few parameters to operators in your DAG file you can easily execute BigQuery jobs or schedule and start pipelines in Dataflow or Dataproc:Composer or Workflows?Both Composer and Workflows support orchestrating multiple services and can handle long running workflows. Despite there being some overlap in the capabilities of these products, each has differentiators that make them well suited to particular use cases. Composer is most commonly used for orchestrating the transformation of data as part of ELT or data engineering or workflows. Workflows, in contrast, is focused on the orchestration of HTTP-based services built with Cloud Functions, Cloud Run, or external APIs. Composer is designed for orchestrating batch workloads that can handle a delay of a few seconds between task executions. It wouldn’t be suitable if low latency was required in between tasks, whereas Workflows is designed for latency sensitive use cases. While you don’t have to worry about maintaining Airflow deployments in Composer, you do need to specify how many workers you need for a given Composer environment. Workflows is completely serverless; there is no infrastructure to manage or scale.Have a look at these example use cases to help you understand which product to use:SummarySo there you have it, a quick overview of the different orchestration tools in Google Cloud and a decision tree on how to choose the right one for your use case. In the end, the systems and services you’re trying to orchestrate will determine the right tool to use. Coming up in the next blog post, we will deep dive into data orchestration in more detail, so stay tuned! In the meantime, check out our Quickstart guides on Cloud Scheduler, Cloud Composer and Workflows to get started!Related ArticleBetter service orchestration with WorkflowsWorkflows is a service to orchestrate not only Google Cloud services such as Cloud Functions and Cloud Run, but also external services.Read Article
Quelle: Google Cloud Platform