Cloud Firestore explained: for users who never used Firestore before
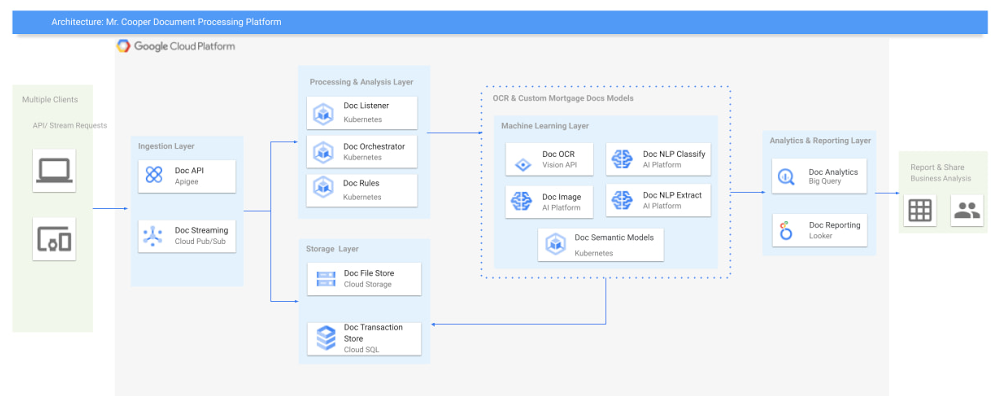
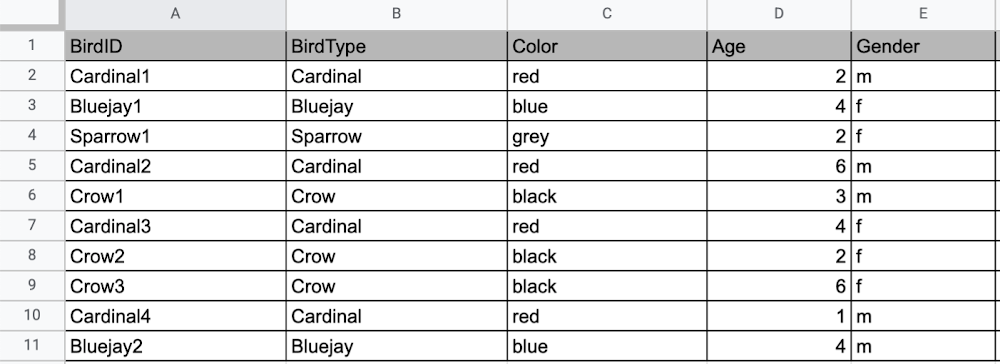
Learning to use a new database can be daunting, even more so if you don’t already have technical knowledge about databases. In this article, I will break down some database basics, terms you should know, what Firestore is, how it works, how it stores data, and how to get started using it with the assumption that you don’t have any existing database knowledge.Before we dive into what Cloud Firestore is, let’s discuss some key database terms you should know. Feel free to skip this section if you are already familiar with the basics of Relational and non-relational databases. What is a database? A database is software that allows you to easily access, manage, modify, update, control and organize data. The way you want to store information can impact what type of database you choose. There are two major categories of databases, Relational and non-relational. Relational DatabaseA relational database can be thought of like a spreadsheet. You can store information in your spreadsheet like this: Now, what happens if I want to store information about where Sparrow1 lives, in my spreadsheet, but I don’t care about where the other birds live? I would have to add another column to my spreadsheet, called home, that would only contain data for the sparrow. That would look like this:Even though I only want to know information about where the sparrow lives, I am required to have blank spaces in the column for all of the other animals. This is because in a relational database, you have a specific structure of your data called a schema. Just like in a spreadsheet, every item you are storing information on must have a place to put information about the bird’s home, even if you only want that information for one bird. This is enforced by the schema, which is essentially the column headers you put in the sheet and dictates a strict structure for the data, which has pros and cons.The strict structure of a relational database allows your application to know what kind of data exists, to know what the data type is, and to enforce rules such as requiring data to be unique, or enforcing type of data stored etc. A schema, by design, forces the data in each row to have the same characteristics, which means it is not very flexible, unless you change the schema for the database. That means if you want to add different data that doesn’t fit your existing schema, you have to change the schema. As we discussed above, if you want to change the schema we are using to store information, such as Home, there is some information that will be stored for all rows, even if you don’t want to store anything. The amount of wasted storage is different between database engines, data types etc. Another thing to consider about Relational databases is that at scale, some traditional Relational databases will require more advanced deployments to handle the scale.Changing the schema of a relational database can be highly disruptive, especially for busy workloads because it requires running scripts to change the schema and coordinating it carefully with the code changes in the app. Due to locking, you might even experience downtime in some cases. Now contrast that with a non-relational document database like Firestore, where you don’t have to worry about schema changes in the databases or downtime as a result of it.Also, when you have a lot of data that you want to collect and it only applies to a few things in your database, having extra space with no information in it can become wasteful because it uses up storage space in many cases. A non-relational database can help get around this problem. Non-relational databasesGenerally speaking, a non-relational database stores information in a different format than a Relational database. There are 4 major categories of non-relational databases that you will hear most frequently.Column-Family Document (Firestore) Key-Value Graph Since this post is focusing on Firestore, in this section we will dive into what a document database is, how it is used, and when to use it.Document database (Firestore) A document database can be thought of as a multi layered collection of entities, such as this: As you can see, when the list is all collapsed, you can only see the information at the top; in this case, that is the BirdID (Cardinal1, Bluejay1, Sparrow1, Cardinal2, Crow1 etc. When I open the list I see “word: word”. For example, the document ID Sparrow1, points to a document with “Type: Sparrow”. I also see “Color: grey”, “Age: 2”, “Gender: f” and “Home: Birdhouse #3”This is known as a key value pair. For “Type: Sparrow”, Type is the key and Sparrow is the value. All of the keys in the Sparrow1 document are: Type, Color, Age, Gender, House. All of the values in the Sparrow1 document are: Sparrow, grey, 2, f, Birdhouse #3.Similarly to how the key gives you context, it allows you to ask the computer for a specific piece of information, such as the age of the bird. It is important to decide on a specific key term you will use for each piece of data you collect so your data can be easily read programmatically. This is called an implicit schema, an implied understanding of how data is stored that is not enforced by the database. Let’s go over what happens when we use an implicit schema.Under Cardinal1, you see Type, Color, Age, and Gender; however, under Sparrow1 you also see House. This is possible because in a non-relational database you don’t have a schema that requires you to store the same information about every bird in your database; instead, you can store the specific information that you need for each bird, regardless of what is stored for other birds. This is a great benefit in terms of flexibility, but because of this flexibility, maintaining standard naming conventions is very important.Now, let’s discuss why using standard naming conventions is so important. In the example above, if I ask a human: “What is the age of Cardinal1?”, they would probably tell me 2. If I asked them: “What is the Age of Bluejay1?”, they would probably tell me 4. These are both correct answers, but they are only correct because a human is able to assume what Age means. A computer, on the other hand, can’t make assumptions. If I ask a computer: “What is the Age of Cardinal1?” it would say 2, but if I ask it: “What is the Age of Bluejay1?” it would not know. This is because the computer is looking for the keyword Age and it isn’t able to use any context clues to determine what other words might mean Age. However, if I asked the computer: “What is the BirdAge of Bluejay1?”, the computer would tell me 4. Why do I care that I need to tell the computer to look for BirdAge to get the age of blujay one, but to look for Age to get the age of Cardinal one? I care because it means I would have to write two entirely different sets of instructions (i.e software code) to get the age of Cardinal1 and the age of Bluejay1 if I am not careful in how I structure my data. But when I structure my data well, this is not an issue and is infact a benefit by adding added flexibility. What we see from this example, is that even without a strict schema, we can (and should) define conventions for document formats. If conventions aren’t defined, things can get unwieldy quickly. How information is accessedNow, let’s discuss how the information is accessed. If I wanted to know information about which birds are blue in our drop down list example, I would need to expand every section of the list to check if the bird is blue or not. As you can imagine, once you start to get a lot of birds in your database, it becomes cumbersome to open every drop down and see if the bird is blue. Luckily, Firestore lets you run these types of queries against the data (See more here) and receive all the documents that satisfy your conditions. On the other hand, if I wanted to know all of the information about Cardinal1, I could just open the drop down for Cardinal1 and I would have all of the information about that bird. Now let’s start using some Firestore specific terminology. For the example we just discussed:CollectionsIn Firestore, your data lives in collections. You can think of collections as tabs in a spreadsheet.Collections can be used to organize data. For example, if I decide that I want to collect data about birds and fish, the data about birds could be put in a birds collection, and the data about fish could be put in a Fish collection. ex:DocumentsThis is the unit of storage that Firestore uses. In our example, each bird is its own document. Documents reside in collections. This is what one document would contain:Each Document corresponds to a row in the sheet. The following diagram demonstrates that each column header maps to a property name in the document and that each value in a row maps to a value in the document.Each document must be identified by a unique identifier. In our example, that is BirdID. Notice that the value for BirdID is stored at the top level of the list, so when the document is closed, you can only see Cardinal1 and Cardinal1 is not also stored within the document. ReferencesAll documents can be uniquely identified by their location. Let’s think through this in words first before we move to code. If I want to tell someone to get data about the sparrow from the drop down lists, I would need to tell them:In the bird drop down list, can you please get all the information under Sparrow1 and put it on a piece of paper called sparrow1Info?Now let’s try that again using Firestore terms. From the birds collection, can you please get the document for sparrow1 from the Firestore database (db) and save it as sparrow1Info?Now let’s try it in code.var sparrow1Info = db.collection(‘birds’).doc(‘sparrow1′);SubcollectionsA subcollection is a collection associated with a document. Using our example of the drop down list, we can add a collection called sightings that stores documents about each sighting of the specific bird. This is what that would look like: It is important to note that you don’t need to have the same subcollections on all documents. For example, Cardinal1 can be the only document that has a subcollection of Sightings. How to search on Google about FirestoreThe hardest part of learning a new technology can often be knowing the right terms to put into Google search to get the answers you are looking for. Here are some key terms that can help you get startedYour question: How should I arrange my data to store it in Firestore?Search: Document database implicit schema designYour Question:What other databases are similar to firestore?Search:What are some document databases Your Question:How do I get all documents in the Birds collection?Search:How to use wildcards in Firestore What next?Try this guide to get started building your first application that uses Firestore: https://firebase.google.com/docs/firestore/quickstart
Quelle: Google Cloud Platform