Cloud CISO Perspectives: June 2021
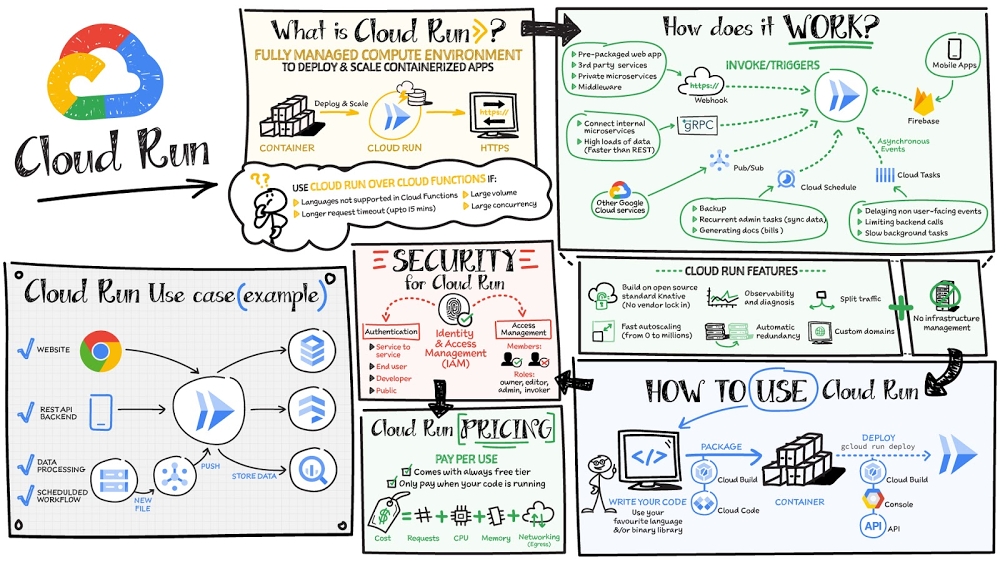
It’s been another busy month for security teams around the globe with no signs of slowing down. Many of us virtually attended RSA, and ransomware attacks continue to dominate headlines. The Biden Administration’s Executive Order on Cybersecurity is officially underway, with important milestones like the NIST workshops where many of us discussed the Standards and Guidelines to Enhance Software Supply Chain Security.In this month’s post I’ll recap these topics, the latest security updates from our Google Cloud product teams, and more. Don’t forget we have a new newsletter sign up for this series, so you can get the latest updates delivered to your inbox. Thoughts from around the industry Post-RSA takeaways: Resilience was the theme of this year’s event, and it’s something we need to think about throughout the rest of this year and beyond. Last year Iwrote about general resilience, and how one of the common mistakes many organizations make is to think that resilience can be obtained by simply writing down plans and procedures on what to do and how to respond to specific events. Overall, as recent cyber events have shown us, there are potential problems with this approach. For example, most crises or significant events are unique, and if the organization can only respond to what is in a plan or procedure then the muscle-memory for the needed agility in response may not be there. In many ways, what we need are a set of foundational capabilities across prevention, detection, response and recovery that are continuously exercised and improved. As everyone is learning, scenario specific plans are necessary but real resilience comes from organization muscle-memory joined with continuously tested people, process and technology capabilities that can be adapted to meet any challenge.Zero trust was also a hot topic during this year’s event. Between the COVID-19 pandemic and recent cyber attacks, it’s promising to see that organizations everywhere are now realizing they need a comprehensive and modern zero trust access approach that removes overreliance on the network perimeter to protect themselves against a variety of threats. For Google, zero trust is more than a marketing buzzword or trend to attach to—it’s how we have operated and helped to protect our internal operations over the last decade with our BeyondCorp framework. We will continue to improve upon the industry standard with our lessons learned, so that other organizations can benefit from zero trust access platforms with BeyondCorp Enterprise and move toward a safer security posture. Ransomware: From Colonial Pipeline to JBS, rarely a day goes by without a new attack in the news. The reality is that many of these problems stem from a lack of rigor implementing a range of basic technology controls. We’re at an inflection point where both the private and public sector need to work together to prioritize the right defenses against these rising threats. We think it’s a mistake to assume one control or one product can be the solution to ransomware. Many organizations have started to realize you need an array of controls working together to create and sustain a defensible security posture. We recently highlighted our recommendations to protect against ransomware based on the National Institute of Standards and Technology (NIST) primary pillars for a successful and comprehensive cybersecurity program. Securing open source software: The Open Source team at Google recently announced an incredibly useful exploratory visualization site called Open Source Insights, which provides an interactive view of the dependencies, including first layer and transitive dependencies, of open source projects. This is an extremely important effort for the industry, especially as more and more organizations rely on open source software for critical aspects of their environments. While the benefits of open source software are clear, challenges persist. Take for example the complexity of the supply chain; open source software projects often have many hundreds of dependencies. Open Source Insights gives developers a comprehensive visualization of a project’s dependencies and their properties and vulnerabilities. This includes interactive visualizations for developers to analyze transitive dependency graphs, and a comparison tool to highlight how different versions of a package might affect their dependencies by introducing or removing licenses, fixing security problems, or changing the packages’ own dependencies. While much more work and research is needed in this space, Open Source Insights is a critical step in helping secure the open source software supply chain.Click to enlargeThe EU Cloud Code of Conduct: While it went into force in 2018, the EU’s General Data Protection Regulation (GDPR) remains firmly top of mind as organizations use the cloud for processing of sensitive data. Providers like Google Cloud are often asked derivatives of the question “how can we be sure you’re taking appropriate measures to safeguard data under the GDPR.” We now have a definitive answer. The EU GDPR Cloud Code of Conduct(CoC) is a mechanism for cloud providers to demonstrate how they offer sufficient guarantees to implement appropriate technical and organizational measures as data processors under the GDPR. The Belgian Data Protection Authority, based on a positive opinion by the European Data Protection Board (EDPB), last month approved the CoC, a product of years of constructive collaboration between the cloud computing community, the European Commission, and European data protection authorities. This is the first European code approved under the GDPR; it is excellent news for the industry to have a new transparency and accountability tool that helps promote trust in the cloud. We are proud to say that Google Cloud Platform and Google Workspace already adhere to these provisions.Spotlight on the Administration’s Executive Order on Cybersecurity The Presidential Administration’s recent moves in the Executive Order to shore up our nation’s cyber defenses is an important milestone for both public and private sector organizations. At Google, we are deeply committed to advancing cybersecurity issues and believe that government officials shouldn’t have to tackle these issues on their own. Importantly, the EO makes critical strides to help modernize government technology and advance security innovation as well as improve standards for secure software development. We’ve already shared our perspective with the government and will continue to advocate on these issues in the coming months. Modernization and security innovation: One of the most promising aspects of the government’s approach is to set agencies and departments on a path to modernize security practices and strengthen cyber defenses across the federal government. For too long, the public sector has tried to solve security challenges by spending more on security products, but as recent events have proved, spending billions of dollars on cybersecurity on an unmodernized IT platform is like building on sand. We strongly support this push towards modernization and agree with the government’s focus on making security simple and scalable, by default. Modernizing can not only build cybersecurity at a foundational level but also gives the federal government the opportunity to diversify their vendors, which can lead to improved resilience.Secure software development: Earlier this month Google participated in the NIST workshops and submitted position papers for how the industry can enhance software supply chain security. We believe that the government’s call to action on secure software development practices could bring about the most significant progress on cybersecurity in a decade and will likely have the biggest impact on the government’s risk posture in the long term. To further the adoption of supply chain integrity best practices, Google in collaboration with the OpenSSF has proposed Supply-chain Levels for Software Artifacts (SLSA) to formalize criteria around software supply chain integrity. We look forward to continuing to collaborate and engage with the Administration on this important work.Google Cloud Security highlights Google Cloud Named a Leader in Forrester Wave™: Unstructured Data Security Platforms: Providing effective controls to protect sensitive data in the cloud is a core part of our Google Cloud product strategy and unstructured data in particular can be challenging to secure. Given the importance of these capabilities to our customers, we were happy to see that Forrester Research named Google Cloud a Leader in The Forrester Wave™: Unstructured Data Security Platforms, Q2 2021 report. The report evaluated the 11 most significant providers with platform solutions to secure and protect unstructured data, spanning cloud providers to data security-focused vendors. Google Cloud rated highest in the current offering category among all the providers evaluated and received the highest possible score in sixteen criteria. A copy of the full report can be viewed here.Security benefits of a Data Cloud: Last month, we held our first Data Cloud Summit where we announced three new services as part of our database and data analytics portfolio to provide organizations with a unified data platform: Dataplex, Analytics HubandDatastream. Security professionals often default to using only security branded tools, but some of the best tools for security teams might be to use data and analytics products that are key to other business functions within the organization. Digital technologies like AI, ML and data can be used to power innovation, especially for security efforts. At Google, security is the cornerstone of our product strategy and our customers can take advantage of the same secure-by-design infrastructure, built-in data protection, and global network that we use to ensure compliance, redundancy and reliability.New features to secure your Cloud Run environments: Cloud Run makes developing and deploying containerized applications easier for developers. We announced several new ways to help make Cloud Run environments more secure based on enhanced integrations with Secret Manager, Binary Authorization, Cloud KMS, and Recommendation Hub.Advanced counter-abuse and threat analysis features in Google Workspace:We continue to add controls and capabilities for Workspace admins to protect their users and organizations against threats and abuse. We recently added features that enrich security alerts with VirusTotal threat context and reputation data, enable blocking of abusive users and bulk removal content they’ve shared in Drive, and programmatic blocking third-party API access.That wraps up another month of thoughts and highlights. If you’d like to have this Cloud CISO Perspectives post delivered every month to your inbox, click here to sign-up.Next month, we’ll be busy hosting our first digital Security Summit where you can hear from industry leaders and engage in interactive sessions that can help you solve your most critical security challenges. Be sure to register and tune in to the great event we have planned!Related ArticleCloud CISO Perspectives: May 2021Google Cloud CISO Phil Venables shares his perspective on industry news as RSA 2021 approaches.Read Article
Quelle: Google Cloud Platform