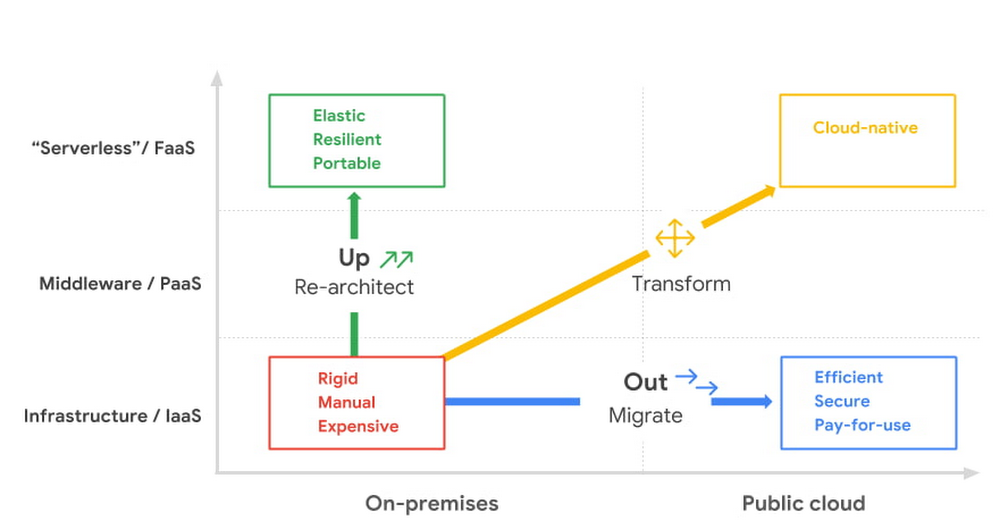
As your organization evolves, the cloud can be a powerful tool to drive growth, improve efficiency, and reduce costs. In fact, the cloud is so powerful that most organizations find themselves running on multiple clouds—a full 92% of enterprises surveyed by Flexera1 reported adopting a deliberate multicloud strategy in some way, shape, or form: on one or more public clouds, on-premises data centers (or private clouds)—and let’s not forget the edge locations. Multicloud, in short, is very much the reality for today’s enterprises. The problem is that cloud platforms each come with their own proprietary approach to management. This creates inconsistency in operations, making it hard and more expensive to maintain security and compliance across environments. It also hampers developer productivity, places a strain on precious talent, and adds to overall costs. Can you get the advantages of using distinct cloud providers while minimizing the complexity and cost?Have no fear–there’s good news. Running on multiple clouds doesn’t have to be hard. It doesn’t have to be expensive. It doesn’t have to be a burden on your operations teams. Done right, you can go from running on multiple clouds out of necessity, to turning those multicloud assets into a net positive for your developers, your platform administrators, and your organization’s bottom line. To show you how, first, let’s recap why organizations tend to find themselves running on multiple clouds. Then, we’ll walk through a few ways Google is bringing cloud services like Anthos, Looker, BigQuery Omni, Apigee API management, and others to multicloud environments in way that positions your organization to take advantage of everything the cloud has to offer. Why do organizations run on multiple clouds?For many organizations, working with multiple cloud providers is about selecting best-of-breed capabilities. For example, one provider may have broader compute options, another may specialize in data analytics and AI services, and another may support legacy environments. The decision to run on multiple clouds is often made in the boardroom. Sometimes it’s a business decision to avoid cloud provider lock-in, to comply with regulations that aim to avoid over-reliance on a single cloud infrastructure, or to satisfy geography-specific consumer protection laws e.g., GDPR, the California Consumer Privacy Act and GAIA-X. Companies also find themselves running on multiple clouds over time, say, as the result of an acquisition. Faced with workloads that are already running effectively on the non-preferred cloud, organizations sometimes come to the conclusion that they are not worth re-platforming.Regardless of the road you took to running on multiple clouds, you need to make it work well, minimizing complexity, keeping costs low, and enabling staff, rather than creating extra work for them. You want a platform to simplify and enhance your multicloud assets, and you need tools that are multicloud-ready. Here are just a few of the ways Google can help you succeed in your multicloud journey.From containers to a modern open cloudWhen operating in multiple cloud environments, organizations often start by looking for consistency and portability, turning to containers to re-package their workloads into a portable format that can run on multiple clouds, while standardizing skills and processes for platform teams. Google created Kubernetes to manage large fleets of our own containers, and open sourced it to help others achieve the same. Then, to make it easier for organizations to run Kubernetes, we created Google Kubernetes Engine (GKE), a reliable, secure and fully managed service. A few years later we introduced Anthos, a secure managed platform designed to simplify the management of Kubernetes clusters on any public or private cloud by extending a GKE-like experience along with our best open-source frameworks, with a Google Cloud-backed control plane for consistent management of services in distributed environments.Today, multicloud organizations can leverage our full open cloud approach, which uses open-source technologies to let them deploy—and, if desired, migrate—critical workloads running on both VMs and containers and reimagine them in a modern microservices-based architecture. Anthos can also help you to leverage consistent Google Cloud services in other clouds. For example, we introduced Apigee hybrid to give you the flexibility to deploy API runtimes in a hybrid environment while using cloud-based Apigee capabilities such as developer portals, API monitoring and analytics. Apigee hybrid exposes trusted data residing across clouds through APIs to support faster app builds. We also brought hybrid AI capabilities to Anthos, designed to let you use our differentiated AI technologies wherever your workloads reside. By bringing AI on-prem, you can now run your AI workloads near your data, all while keeping them safe. In addition, hybrid AI simplifies the development process by providing easy access to best-in-class AI technology on-prem. The first of our hybrid AI offerings, Speech-to-Text On-Prem, is now generally available on Anthos through the Google Cloud Marketplace, and going forward, we are committed to bringing additional Google Cloud services, development tooling, and engineering practices to other environments for a truly consistent multicloud experience.Uncover new insights with a multicloud data analytics platformIf you want to make the best decisions for your business, you need access to your data and the ability to quickly derive insights from it, often in real time. That doesn’t change when your data is in multiple clouds. Unfortunately, the cost of moving data between cloud providers isn’t sustainable for many businesses, and it’s still difficult to analyze and act on data across clouds. We want you to be able to take advantage of our analytics, artificial intelligence, and machine learning capabilities regardless of where your data resides. A data cloud allows you to securely unify data across your entire organization, so you can break down silos, increase agility, innovate faster, get more value from your data, and support business transformation.To better serve customers across multiple environments, last year we launched BigQuery Omni, a new way of analyzing data stored in multiple public clouds that’s made possible by BigQuery’s separation of compute and storage. While competitors require you to move or copy your data from one public cloud to another—and charge high egress fees in the process—BigQuery Omni does not. And because BigQuery Omni is powered by Anthos, you can query data without having to manage the underlying infrastructure. With BigQuery Omni for Azure, now in public preview, we’re enabling more organizations to analyze data across public clouds from a single pane of glass. This, along with BigQuery Omni for AWS, helps customers access and securely analyze data across Google Cloud, AWS, and Azure.Then there’s Looker, a unified business intelligence and embedded analytics platform across your multicloud ecosystem. Looker’s in-database architecture supports a wide range of databases and SQL dialects. Using Looker, you can directly query data stored across multiple clouds to deliver governed real-time data at web scale where and when it’s needed, whether that’s through BI reports and dashboards, embedded analytics, automated data-driven workflows or completely custom data app experiences. This is why we’re excited to announce the continued expansion of Looker’s multicloud support, now including Looker hosted on Azure and support for more than 60 distinct database dialects. Now, you can host your Looker instance on the leading cloud provider of your choice: Google Cloud, AWS or Azure. Build cloud-native apps across clouds, at scaleIn an ideal world, development teams would not need to worry about the details of their specific platforms. They could modernize their existing apps, build cloud-native microservices, and deploy to any cloud platform for consistent service delivery anywhere. Additionally, they’d be able to manage all their clusters with a single pane of glass from the infrastructure layer through to service performance and topology—all in a uniform way. For many organizations, multicloud is only worth it if it can effectively address these needs. Anthos gives you the ability to run Kubernetes anywhere: private clouds and Google Cloud, but also Azure, and AWS. And no matter where you are running, Google Cloud’s suite of development tools are able to seamlessly integrate into your environment, making it easier for developers and operators to build, deploy and manage applications. For example, developers can write Kubernetes applications within their preferred IDE with Cloud Code.Secure your apps and data wherever they are When you’re running in several environments, you really can’t overlook security. Google Cloud solutions aim to secure everything in your multicloud environment, from the user to the network to the app to your data. We also provide threat detection and investigation across these surfaces, even for organizations that do not run their systems in our cloud. Our trusted cloud enables your digital transformation while also supporting your risk, security, compliance and privacy transformation. Our platform also delivers transparency and ensures digital sovereignty across data, operations, and software. We provide a secure foundation that you can verify and independently control, enabling you to move from your own data centers to the cloud while maintaining control over data location and operations—all while ensuring compliance with local regulations. Get started on your multicloud journeySome cloud providers dismiss customers who see multicloud as their path forward and don’t offer their cloud services where the customer needs them to be. That’s not our approach. Our goal is to support you regardless of where your data resides or where your applications run. If you’re ready to take your cloud deployment to the next level, check out our whitepaper, 5 ways Google can help you succeed in a hybrid and multicloud world. Or reach out to us and see if Google Cloud multicloud technologies can be what takes you there.1. Gartner Research
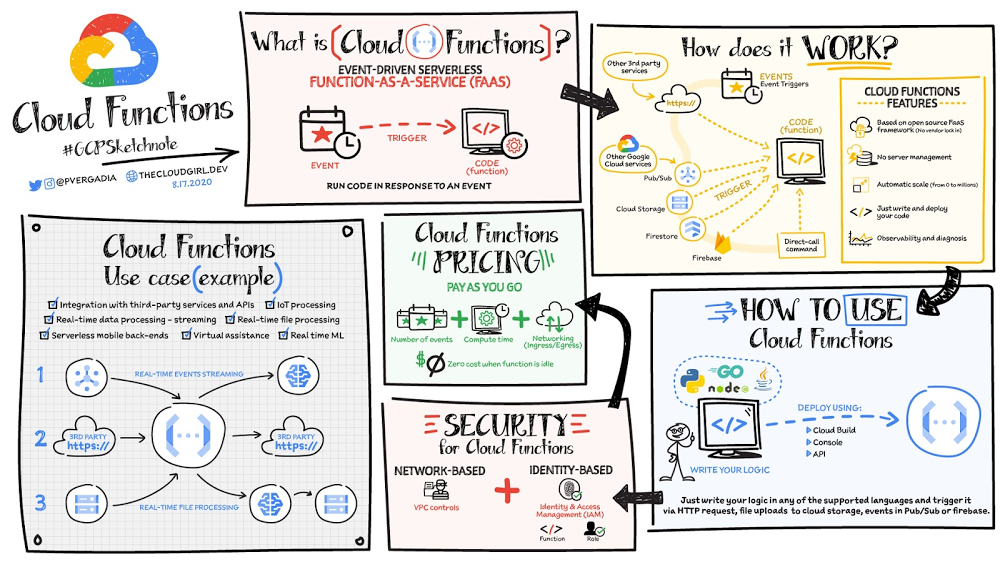
Quelle: Google Cloud Platform