Build a platform with KRM: Part 3 – Simplifying Kubernetes app development
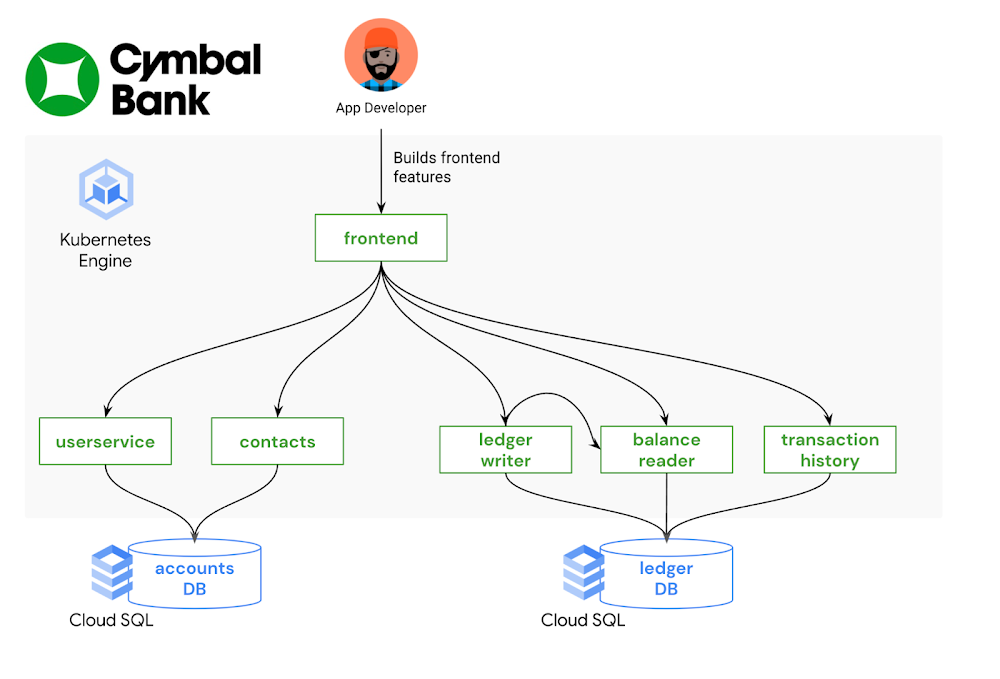
This is part 3 in a multi-part series about the Kubernetes Resource Model. See parts 1 and 2 to learn more. In the last post, we explored how Kubernetes and its declarative resource model can provide a solid platform foundation. But while the Kubernetes Resource Model is powerful, it can also be overwhelming to learn: there are dozens of core Kubernetes API resources, from Deployments and StatefulSets, to ConfigMaps and Services. And each one has its own functionality, fields, and syntax. It’s possible that some teams in your organization do need to learn about the whole Kubernetes developer surface, such as the teams building platform integrations. But other teams, such as application developers, most likely do not need to learn everything about Kubernetes in order to become productive. With the right abstractions, developers can interact with a Kubernetes platform more easily, resulting in less toil and speedier feature development. What is a platform abstraction? It’s a way of hiding details, leaving behind only the necessary functionality. By taking certain details away, abstractions open up new possibilities, allowing you to create concepts and objects that make sense for your organization. For instance, you may want to combine all the Kubernetes resources for one service into one “application” concept, or combine multiple Kubernetes clusters into one “environment.” There are lots of ways to abstract a Kubernetes platform, from custom UIs, to command-line tools, to IDE integrations. Your organization’s abstraction needs will depend on how much of Kubernetes you want to expose developers to – it’s often a tradeoff between ease of use and flexibility. It will also depend on the engineering resources you have available to devote to setting up (and maintaining) these abstractions; not every organization has an in-house platform team. So where to start? If you’re already shipping code to a Kubernetes environment, one way to brainstorm abstractions is by examining your existing software development lifecycle. Talk to the app developers in your org: how do they interact with the platform? How do they test and stage their code? How do they work with Kubernetes configuration? What are their pain points? From here, you can explore the vast cloud-native landscape with a set of concrete problems in mind. This post demonstrates one end-to-end development workflow using a set of friendly Kubernetes tools.Bootstrapping developers with kustomizeImagine you’re a new frontend developer at Cymbal Bank. Your job is to build and maintain the public web application where customers can create bank accounts and perform transactions. Most of your day-to-day work involves changing or adding features to the Python and HTML frontend, testing those features, and creating pull requests in the source code repository. You’re not very familiar with Kubernetes, having used a different platform in your previous role, but you’re told that you have a development GKE cluster to work with. Now what?An application developer’s focus, ideally, is on source code – not on the underlying infrastructure. Let’s introduce an abstraction that allows the app developer to test their code in development, without having to write or edit any Kubenetes resource files. An open-source tool called kustomize can help with this. kustomize allows you to “customize” groups of Kubernetes resources, making it easier to maintain different flavors of your configuration, without duplicating resource manifests. The two core kustomize concepts are bases and overlays. A base is a directory containing one or more Kubernetes resources, like Deployments and Services. Base resources are complete, valid KRM, and can be deployed to a cluster as-is. An overlay is a directory that patches over one or more bases with some customization. Overlays can include modifications to resources in the base, or additional resources defined in the overlay directory. Multiple overlays can use the same base. This allows you to have separate environments for development, staging, and production, which all use the same set of underlying Kubernetes resources. Let’s see this in action. The cymbalbank-app-config repository contains the kustomize resources for the Cymbal Bank app. This repo has one set of base KRM resources. These are complete YAML files for the Deployments, Services, and ConfigMaps corresponding to each Cymbal Bank service. The repo also has two overlay directories, “dev” and “prod.” The development overlay customizes certain fields in the base resources, like enabling debug-level logs. The production overlay adds different customization, keeping the default “info” level logging, but increasing the number of frontend replicas in order to better serve production traffic.Every kustomize directory contains a special file, kustomization.yaml. This file is an inventory of what should be deployed, and how. For instance, the kustomization.yaml file for the development overlay (shown below) defines which base to use, and lists all the “patch” files to apply over the base. The patch files are incomplete Kubernetes resources, changing a specific piece of config in the corresponding base resource.By providing a pre-built set of Kubernetes resources, along with a development-specific overlay, platform teams can help bootstrap new Kubernetes users without requiring them to create or edit YAML files. And because kustomize has native integration with the kubectl command-line tool, developers can directly apply these resources to a test cluster with “kubectl apply -k.” We can also take this kustomize environment one step further, by allowing the app developer to deploy directly to their development GKE cluster from an IDE. Let’s see how. Testing application features with Cloud CodeCloud Code is a tool that helps developers build on top of Google Cloud infrastructure without having to leave their IDE (VSCode or IntelliJ). It allows developers to directly deploy to a GKE cluster, and provides useful features like YAML linting for Kubernetes resources.Let’s say the frontend app developer just added some new HTML to the login page. How can they use the “development” kustomize overlay to deploy to their GKE cluster? Cloud Code makes this easy through a tool called skaffold. skaffold is an open-source tool that can automatically build and deploy source code to Kubernetes, for multiple containers at once. Like kustomize, you can use skaffold by defining a YAML configuration file, skaffold.yaml, that lists where all your source code lives, and how to build it. The Cymbal Bank skaffold file (shown below) is configured with three profiles – dev, staging, and prod – each set up to use a different kustomize overlay. Cloud Code is closely integrated with skaffold, so that if you click “Run on Kubernetes” inside your IDE, and specify the “dev” profile, Cloud Code will read the skaffold.yaml configuration, build your local source code into containers, push those containers to your image registry, then deploy those images to your Kubernetes cluster using the YAML resources in the kustomize dev overlay. In this way, the frontend developer can test their local code changes with a single click – no kubectl or command-line tools required.From staging to production with Cloud Build Now, let’s say the frontend developer has finished implementing and testing their feature, and they’re ready to put out a pull request in git. This is where Continuous Integration comes in— all the tests and checks that help verify the feature’s behavior before it lands in production. As with local development, we want to enable code reviewers to verify this feature in a production-like environment – without forcing them to manually build containers or deal with YAML files. One powerful feature of skaffold is that it can run inside your CI/CD pipelines, automatically building container images from a pull request, and deploying to a staging cluster. Let’s see how this works.We define a Cloud Build trigger that listens to the Cymbal Bank source repository. When a new pull request is created, Cloud Build runs a pipeline containing a “skaffold run” command. This command builds the pull request code, and uses the production kustomize overlay to deploy the containers onto the staging GKE cluster. This allows both the pull request author and the reviewers to see the code in action in a live Kubernetes environment, with the same configuration used in production.We then define a second Cloud Build trigger, which runs when the pull request is approved, and merges into the main branch of the source code repo. This pipeline builds release images, pushes them to Container Registry, then updates the production Deployment resources to use the new release image tags. Note that we’re using two repos here- “App Source Repo” contains the source code, Dockerfiles, and skaffold.yaml file, whereas “App Config Repo” contains the Kubernetes resource files and kustomize overlays. So when a new commit happens in App Source Repo, the Continuous Integration pipeline automatically updates the App Config Repo with new image tags: Once the release build completes, that triggers a Continuous Deployment pipeline, also running in Cloud Build, which deploys the production release overlay, configured with the new release images, to the production GKE cluster. Here, skaffold and Cloud Build allow us to fully automate the stage-and-deploy process for Cymbal Bank source code, such that the only human action to get code into production was a change approval. App developers didn’t have to worry about the details of every cluster in the environment. Instead, they were able to interact with the system as a whole, focusing on source code and writing features. In this way, app developers worked successfully with KRM by not working with KRM at all. This was made possible by adding abstractions like kustomize and Cloud Code on top. This post only scratches the surface on the kinds of abstractions you can build on top of Kubernetes, but hopefully provides some inspiration to get started. To try this out yourself, check out the part 3 demo.In the next post, we’ll discuss Kubernetes platform administration, and how to use the Kubernetes Resource Model to define and enforce org-wide policies.
Quelle: Google Cloud Platform