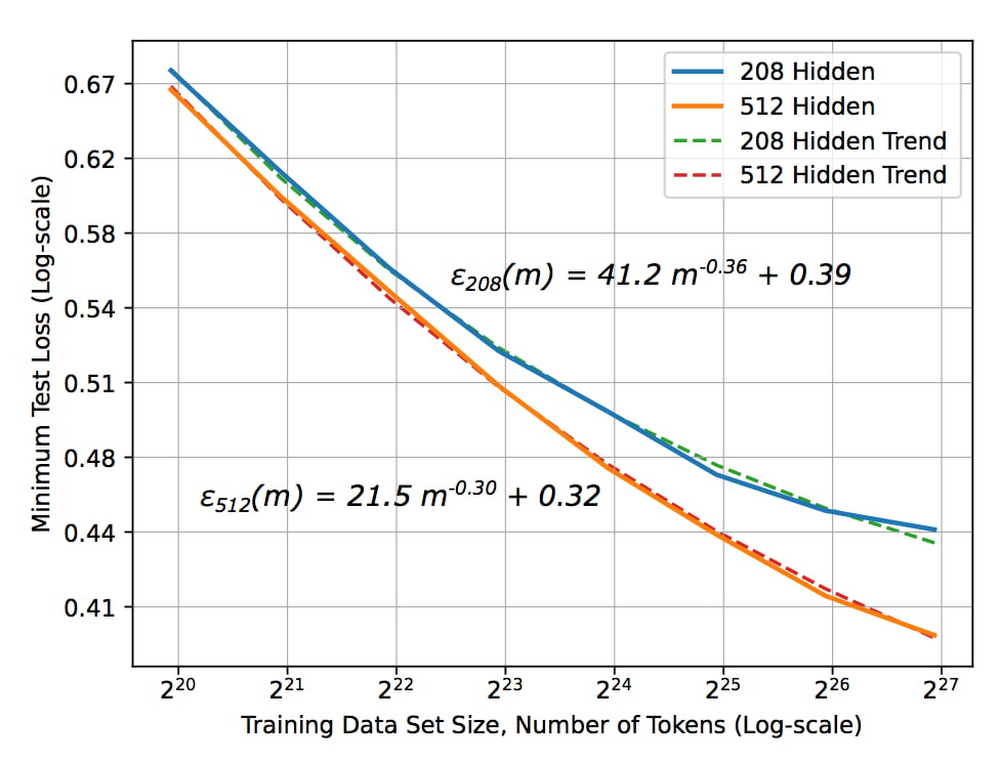
Many of our customers want to know how to choose a technology stack for solving problems with machine learning (ML). There are many choices for these solutions available, some that you can build and some that you can buy. We’ll be focusing on the build side here, exploring the various options and the problems they solve, along with our recommendations. The best ML applications are trained with the largest amount of dataBut first, keep in mind an important concept: the quality of your ML model improves with the size of your data. Dramatic ML performance and accuracy are driven by improvements in data size, as shown in the graph below. This is a text model, but the same principles hold for all kinds of ML models.The unreasonable effectiveness of data Deep Learning scaling is predictable, empiricallyThe X axis represents the size of the data set and the Y axis is the error rate. As the size of the data set increases, the error rate drops. But notice something critical about the size of the data set — the x-axis is2^20, 2^21, 2^ 22, etc. In other words, each new tic here is a doubling of the data set size. To get a linear decrease in your error rate you need to exponentially increase the size of your data set. The blue curve in the graph represents a slightly more sophisticated ML model than the orange curve. Suppose you are deciding between two choices: create a better model or double the data set size. Assuming that these two choices cost the same, it’s better to keep gathering more data. It’s only when improvements due to data size increases start to plateau that it becomes necessary to build a better model. Secondly, ML systems need to be retrained for new situations. For example, if you have a recommendation system in YouTube and you want to provide recommendations in Google Now, you can’t use the same recommendations model. You have to train it in the second instance on the recommendations you want to make in Google Now. So even though the model, the code, and the principles are the same, you have to retrain the model with new data for new situations. Now, let’s combine these two concepts: you get a better ML model when you have more data, and an ML model typically needs to be retrained for a new situation. You have a choice of either spending your time building an ML model or buying a vendor’s off-the-shelf model. To answer the question of whether to buy or whether to build, first determine if the buyable model is solving the same problem that you want to solve. Has it been trained on the same input and on similar labels? Let’s say you’re trying to do a product search, and the model has been trained on catalog images as inputs. But you want to do a product search based on users’ mobile phone photographs of the products. The model that was trained on catalog images won’t work on your mobile phone photographs, and you’d have to build a new model. But let’s say you’re considering a vendor’s translation model that’s been trained on speeches in the European Parliament. If you want to translate similar speeches, the model works well as it uses the same kind of data. The next question to ask: does the vendor have more data than you do? If the vendor has trained their model on speeches in the European Parliament but you have access to more speech data than they have, you should build. If they have more data, then we recommend buying their model. Bottom line: buy the vendor’s solution if it’s trained on the same problem and has access to more data than you do. Technology stack for common ML use casesIf you need to build, what is the technology stack you need? What are the skills your people need to develop? This depends on the type of problem you are solving. There are four broad categories of ML applications: predictive analytics, unstructured data, automation, and personalization. The recommended technology stack for each is slightly different. Predictive analyticsPredictive analytics includes detecting fraud, predicting click-through rates, and forecasting demand. Step one: build an enterprise data warehouseHere, your data set is primarily structured data, so our recommended first step is to store your data in an enterprise data warehouse (EDW). Your EDW is a source of training examples and product histories tracked over time, and can break down silos and gather data from throughout your organization.Step two: get good at data analyticsNext, you’d build a data culture, get skilled at data analytics, start to build dashboards, and enable data-driven decisions. At this point, you have all of the data and you know which pieces are trustworthy. Step three: build MLFrom your EDW, you can build your models using SQL pipelines. We recommend using BigQuery ML when doing ML with the data in your EDW. If you want to build a more sophisticated model, you can train TensorFlow/Keras models on BigQuery data. A third option is AutoML tables for state-of-the-art accuracy and for building online microservices.Unstructured dataExamples of how our customers use ML to gain insights from unstructured data include annotating videos, identifying eye diseases, and triaging emails. Unstructured data can include videos, images, natural language, and text. Deep learning has revolutionized the way we do ML on unstructured data, whether you’re looking at language understanding, image classification, or speech-to-text. For unstructured data, the models you use will employ deep learning. Here, the ROI heavily favors using AutoML. The amount of time that you’d spend trying to create a new ML model from scratch is almost never worth it. You can spend your money more effectively collecting more data than trying to get a slightly better model. Regardless of the type of unstructured data, our recommendation is to use AutoML for small and medium size data sizes.But AutoML has a limit to scale. At some point, the size of your data set is going to be so large that architecture search is going to get really expensive. At that point, you may want to go to a best-of-breed model with custom retraining from TensorFlow Hub, for example. If you have data sets that are in the millions of examples, you can build your own custom neural network (NN) architectures. But determine if your data set size has started to plateau, by plotting a graph similar to the one at the top of this post. Build a custom NN architecture only after you’ve plateaued, where increasing amounts of data won’t give you a better model. AutomationSome examples of how customers are using ML for automation include scheduling maintenance, counting retail footfall, and scanning medical forms. The key thing to keep in mind as you pick a technology stack for these problems is that you’re not building just one ML model. If you want to schedule maintenance orwant to reject transactions, for example, you’ll need to train multiple linked models. Instead of individual models, think in terms of ML pipelines, which you can orchestrate using all of the technologies already mentioned. Then you have three choices for operationalizing, with three levels of sophistication.Vertex AI has turnkey serverless training and batch/online predictions. This is what is recommended for a team of data scientists. .Deep Learning VM Image, Cloud Run, Cloud Functions or Dataflow feature customized training and batch/online predictions. This is what is recommended if the team consists of data engineers and scientists.Vertex AI Pipelines are fully customizable and recommended for organizations with separate ML engineering and data science teams.When doing automation, the individual models that you chain together into a pipeline will be a mix – some will be prebuilt, some will be customized, and others will be built from scratch. Vertex AI, by providing a unified interface for all these model types, simplifies the operationalization of these models.PersonalizationML application examples of personalization include customer segmentation, customer targeting, and product recommendations. For personalization, we again recommend using an EDW, because customer segmentation uses structured marketing data. For product recommendations, you will similarly have prior purchases and web logs in your EDW., You can power clustering applications, or recommendation systems like matrix factorization, and create embeddings directly from your EDW for sophisticated recommendation systems.For specific use cases, choose the technology stack based on your data size and scope. Start with BigQuery ML for its quick, easy matrix factorization approach. Once your application proves viable and you want a slightly better accuracy, then try AutoML recommendations. But once your data set grows beyond the capabilities of AutoML recommendations, consider training your own custom TensorFlow and Keras models. To summarize, successful ML starts with the question, “Do I build or do I buy?” If an off-the-shelf solution exists that was trained with similar data and with access to more data than you have, then buy it. Otherwise build it, using the technology stack recommended above for the four categories of ML applications.Learn more about our artificial intelligence (AI) and ML solutions and check out sessions from our Applied ML Summit on-demand.Related ArticleWhy you need to explain machine learning modelsWhy explainable AI (XAI) is essential to widespread AI adoption, common XAI methods, and how Google Cloud can help.Read Article
Quelle: Google Cloud Platform