Uber Rallies Drivers Against Teamster Unionization Efforts With Podcasts And Pizza Parties
As Uber scrambles to address an internal scandal over employee allegations of systemic sexism, it’s facing another, increasingly heated labor battle in Seattle — a union drive led by the Teamsters.
The ride-hail giant has opposed the unionization movement in Seattle since it began in late 2015. While the Teamsters worked to win the city approvals necessary to represent drivers, Uber ramped up a sprawling phalanx of anti-union efforts, including everything from in-app notifications and text messages to in-person seminars, collective bargaining pizza parties, and Teamster-critical podcasts.
Just this week, an alert sent via Uber’s driver app warned drivers that Teamsters had been granted “approval to begin pressuring drivers for support” and directed them to information on how they might “protect [their] freedom.”
An in-app message sent to drivers from Uber warning them about the risk of joining the Teamsters union.
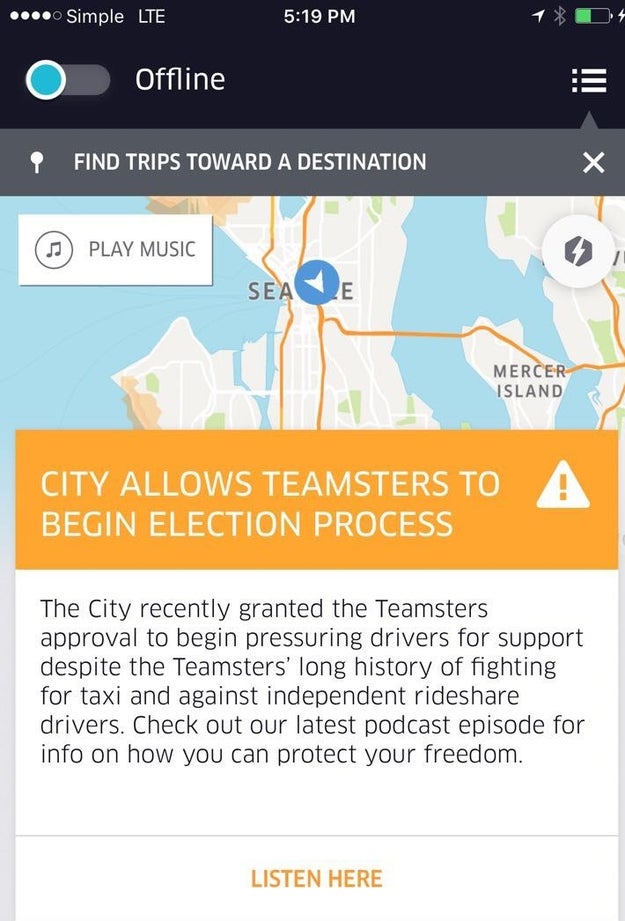
The gist of Uber's argument against the Teamsters: The organization isn’t qualified to represent Uber driver interests because of past efforts to cap the number of ride-hail drivers on the streets in Seattle and otherwise hamstring drivers.
Caleb Weaver, who runs public affairs for Uber in Washington, says the company has good reason to believe this. “Right now as an independent driver, drivers have the ability to decide when, where, and how much they want to drive,” he said. “If there are a series of new requirements imposed on the conditions of work, including things like minimum hours of driving, there will be a loss of control for drivers.”
Unions are typically reserved for employees, and Uber drivers are not employees of the company, but independent contractors; the Seattle collective bargaining ordinance is therefore unique, and the yearlong process of hammering out how a union of independent contractors would actually work has been understandably fraught.
Uber, which sued Seattle to block the ordinance, has been aggressively broadcasting its view in recent weeks. The company deployed a form-letter tool that allows drivers to email half a dozen elected officials in Seattle asking them to “deny the Teamsters’ application” to represent Uber drivers. It has also been holding in-person seminars on unionization efforts that frame the Teamsters as “the opponent of the independent driver” and an organization that “fights against” driver interests.
Lisa, a Seattle driver who attended one of Uber&039;s recent anti-Teamster meetings, said it played host to a mix of sentiments, with some drivers speaking out against unionization efforts, some interested in hearing directly from the Teamsters, and others airing grievances against Uber. “If I felt Uber had mistreated me, or violated civil rights or had workplace rights issues, then I would be fully supportive of a union,” Lisa told BuzzFeed News. “But I don&039;t feel that way about Uber.”
Another driver, who asked to remain anonymous out of concern for his future employment opportunities, has never been in a union before but supports the idea wholeheartedly.
“Uber’s treatment of the drivers is one-sided and abusive,” he told BuzzFeed News. “Uber holds all the power, and the drivers are voiceless.”
In New York, frustrated Uber drivers have found a voice in the Independent Drivers Guild (IDG), an Uber-endorsed labor organization run by the Machinists Union. “It&039;s unfortunate that Uber has taken an anti-union approach in Seattle,” said IDG founder Jim Conigliaro Jr. “They should afford workers a voice as they have here in New York. The dismissive attitude toward drivers who are simply trying to make a living is nothing new.”
An Uber spokesperson was unable to say whether the Drive Forward group in Seattle — co-founded by Uber and a group called Eastside for Hire — might one day resemble the IDG.
The Teamsters, meanwhile, reject claims that they’re wresting control away from drivers. “Uber drivers, like all Teamster members, will have the opportunity to negotiate, review, and vote on their contract before it goes into effect,” said Seattle Teamsters representative Dawn Gearhart. “Drivers have the final say on whether or not it makes sense to have a union, and they won’t approve an agreement that goes against their self-interest.”
For some Uber drivers drawn to the platform by its promise of a boss-free job with flexible hours, union membership — which comes with dues and a hierarchical power structure — can be off-putting. Said Fredrick Rice, an Uber driver who has appeared on the company&039;s podcast, “There is nothing to be gained by Uber drivers being incarcerated into a union, other than money into the union coffers.”
Uber isn’t the only startup that has a problem with how the driver-for-hire union effort has unfolded in Seattle; Lyft drivers are also impacted, and the company likewise opposes it. In a statement to BuzzFeed News, Lyft described the collective bargaining ordinance as “an unfair, undemocratic process,” arguing that a “significant percentage of drivers will be disenfranchised” because the collective bargaining ordinance currently only allows drivers who work a certain amount to vote for representation.
Members of Seattle’s city council have not yet responded to a request for comment. The city will be holding its next hearing on the ride-hail collective bargaining issue on March 21; Uber’s current lawsuit against the city is scheduled to be heard in court on March 17.
Quelle: <a href="Uber Rallies Drivers Against Teamster Unionization Efforts With Podcasts And Pizza Parties“>BuzzFeed






