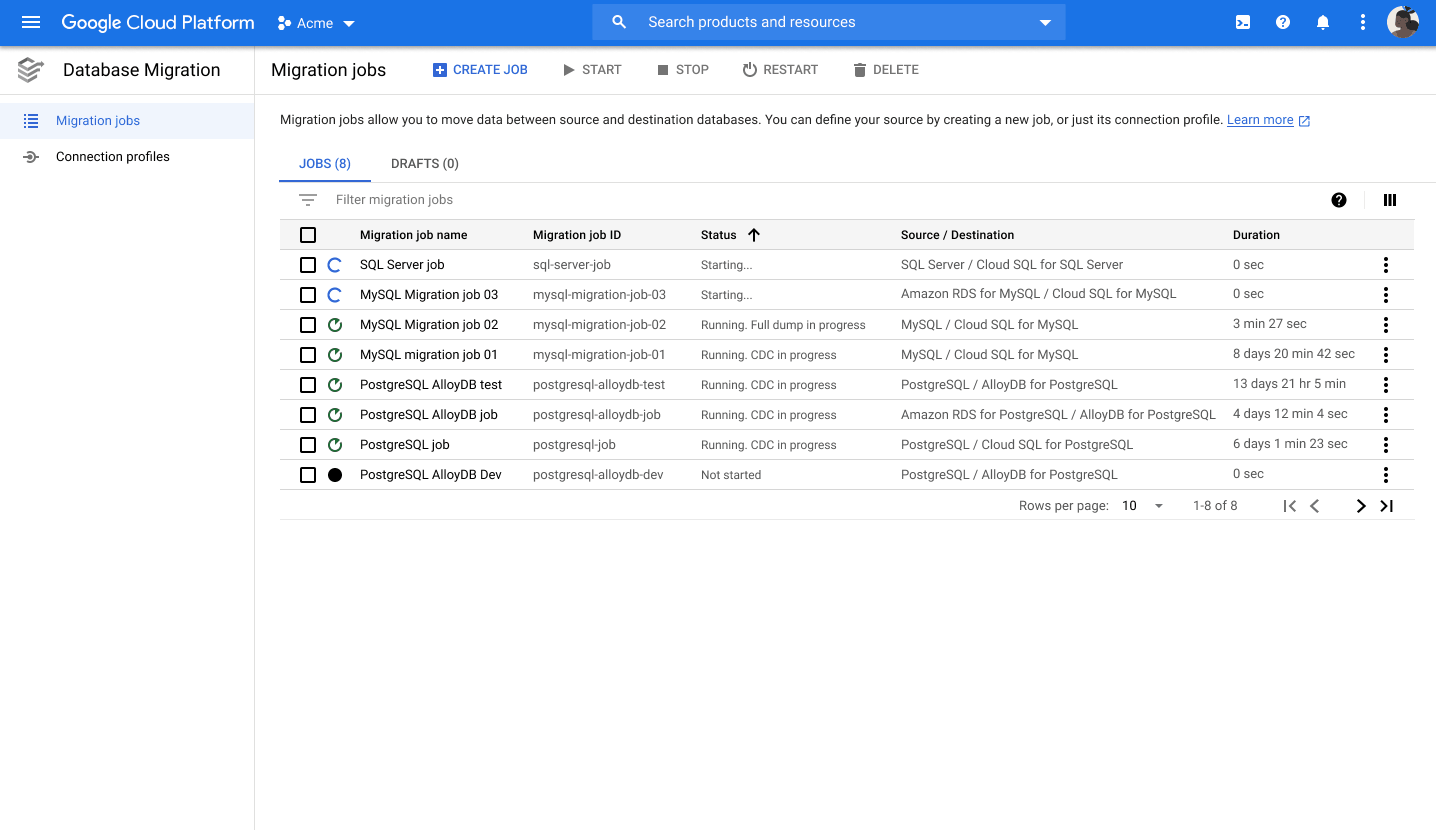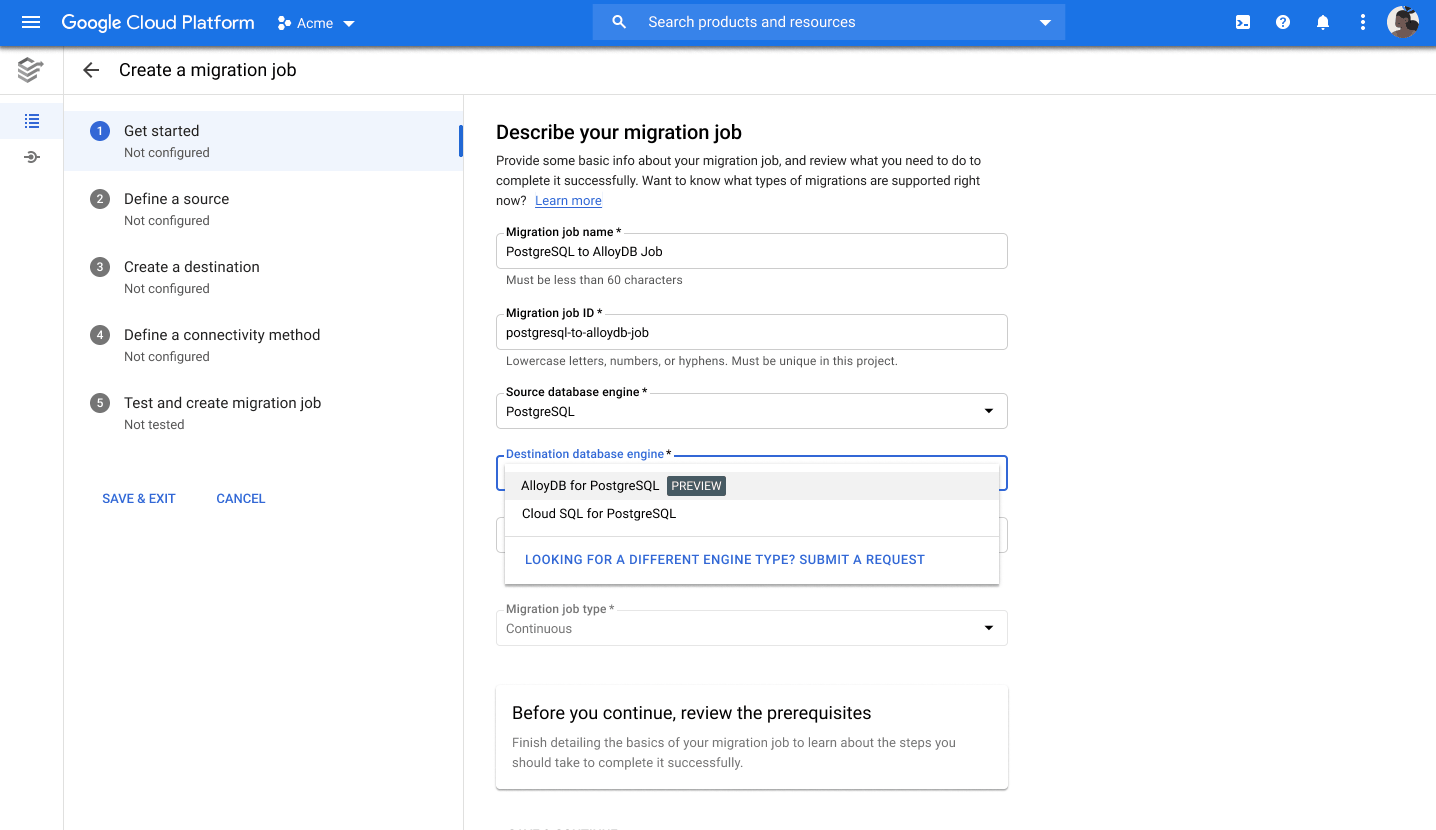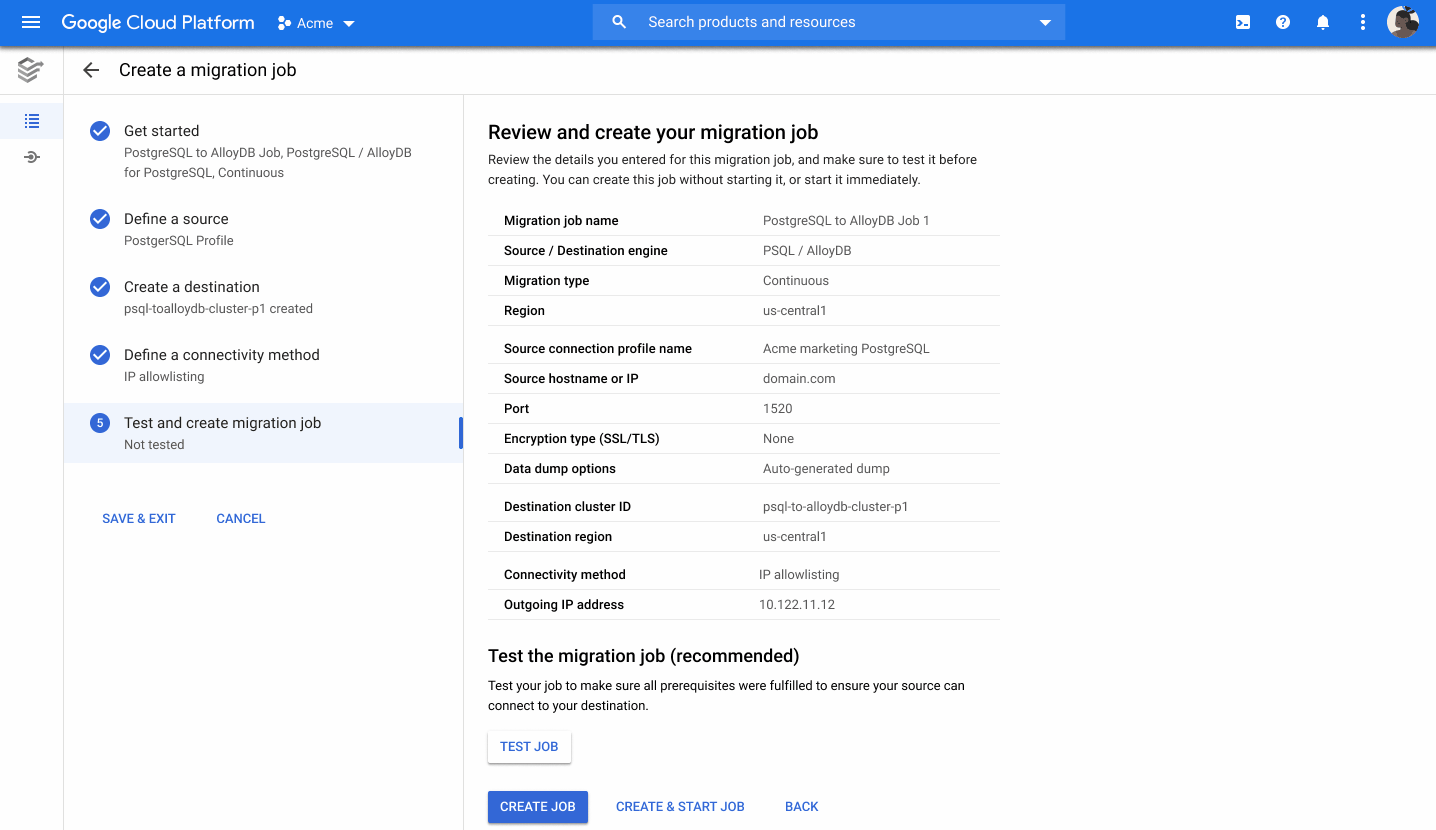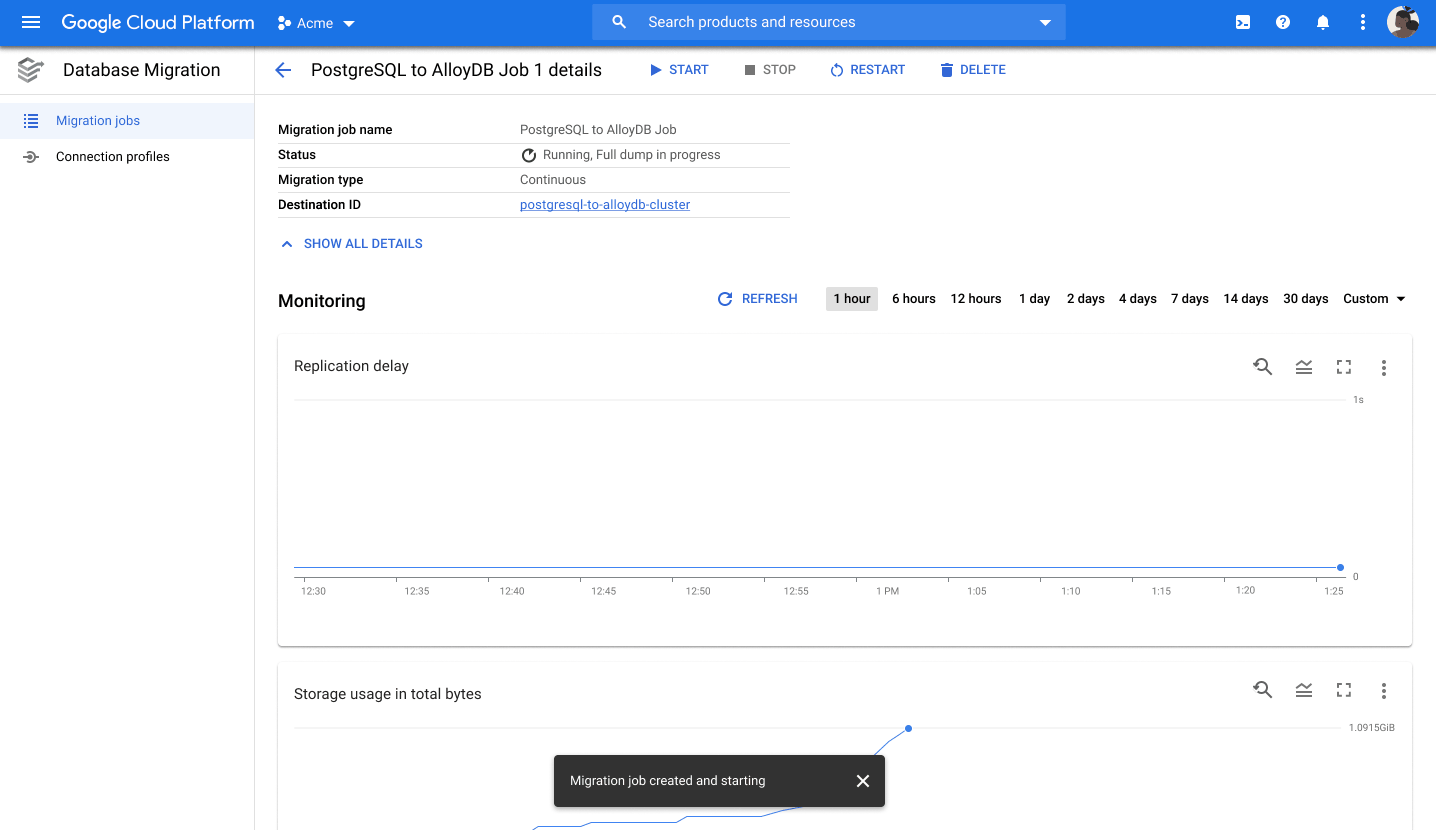
This blog is the first in a two-part series. We’ll talk about the challenges of defining Web3 plus some interesting connections between Web3 and Docker.
Part two will highlight technical solutions and demonstrate how to use Docker and Web3 together.
We’ll build upon the presentation, “Docker and Web 3.0 — Using Docker to Utilize Decentralized Infrastructure & Build Decentralized Apps,” by JT Olio, Krista Spriggs, and Marton Elek from DockerCon 2022. However, you don’t have to view that session before reading this post.
What’s Web3, after all?
If you ask a group what Web3 is, you’ll likely receive a different answer from each person. The definition of Web3 causes a lot of confusion, but this lack of clarity also offers an opportunity. Since there’s no consensus, we can offer our own vision.
One problem is that many definitions are based on specific technologies, as opposed to goals:
“Web3 is an idea […] which incorporates concepts such as decentralization, blockchain technologies, and token-based economics” (Wikipedia)“Web3 refers to a decentralized online ecosystem based on the blockchain.” (Gevin Wood)
There are three problems with defining Web3 based on technologies and not high-level goals or visions (or in addition to them). In general, these definitions unfortunately confuse the “what” with the “how.” We’ll focus our Web3 definition on the “what” — and leave the “how” for a discussion on implementation with technologies. Let’s discuss each issue in more detail.
Problem #1: it should be about “what” problems to solve instead of “how”
To start, most people aren’t really interested in “token-based economics.” But, they can passionately critique the current internet (”Web2”) through many common questions:
Why’s it so hard to move between platforms and export or import our data? Why’s it so hard to own our data?Why’s it so tricky to communicate with friends who use other social or messaging services?Why can a service provider shut down my user without proper explanation or possibility of appeal? Most terms of service agreements can’t help in practicality. They’re long and hard to understand. Nobody reads them (just envision lengthy new terms for websites and user-data treatment, stemming from GDPR regulations.) In a debate against service providers, we’re disadvantaged and less likely to win. Why can’t we have better privacy? Full encryption for our data? Or the freedom to choose who can read or use our personal data, posts, and activities?Why couldn’t we sell our content in a more flexible way? Are we really forced to accept high margins from central marketplaces to be successful?How can we avoid being dependent on any one person or organization?How can we ensure that our data and sensitive information are secured?
These are well-known problems. They’re also key usability questions — and ultimately the “what” that we need to solve. We’re not necessarily looking to require new technologies like blockchain or NFT. Instead, we want better services with improved security, privacy, control, sovereignty, economics, and so on. Blockchain technology, NFT, federation, and more, are only useful if they can help us address these issues and enjoy better services. Those are potential tools for “how” to solve the “what.”
What if we had an easier, fairer system for connecting artists with patrons and donors, to help fund their work? That’s just one example of how Web3 could help.
As a result, I believe Web3 should be defined as “the movement to improve the internet’s UX, including for — but not limited to — security, privacy, control, sovereignty, and economics.”
Problem #2: Blockchain, but not Web3?
We can use technologies in so many different ways. Blockchains can create a currency system with more sovereignty, control, and economics, but they can also support fraudulent projects. Since we’ve seen so much of that, it’s not surprising that many people are highly skeptical.
However, those comments are usually critical towards unfair or fraudulent projects that use Web3’s core technologies (e.g. blockchain) to siphon money from people. They’re not usually directed at big problems related to usability.
Healthy skepticism can save us, but we at least need some cautious optimism. Always keep inventing and looking for better solutions. Maybe better technologies are required. Or, maybe using current technologies differently could best help us achieve the “how” of Web3.
Problem #3: Web3, but not blockchain?
We can also view the previous problem from the opposite perspective It’s not just blockchain or NFTs that can help us to solve the internet’s current challenges related to Problem #1. Some projects don’t use blockchain at all, yet qualify as Web3 due to the internet challenges they solve.
One good example is federation — one of the oldest ways of achieving decentralization. Our email system is still fairly decentralized, even if big players handle a significant proportion of email accounts. And this decentralization helped new players provide better privacy, security, or control.
Thankfully, there are newer, promising projects like Matrix, which is one of very few chat apps designed for federation from the ground up. How easy would communication be if all chat apps allowed federated message exchanges between providers?
Docker and Web3
Since we’re here to talk about Docker, how can we connect everything to containers?
While there are multiple ways to build and deploy software, containers are usually involved on some level. Wherever we use technology, containers can probably help.
But, I believe there’s a fundamental, hidden connection between Docker and Web3. These three similarities are small, but together form a very interesting, common link.
Usability as a motivation
We first defined the Web3 movement based on the need to improve user experiences (privacy, control, security, etc.). Docker containers can provide the same benefits.
Containers quickly became popular because they solved real user problems. They gave developers reproducible environments, easy distribution, and just enough isolation.
Since day one, Docker’s been based on existing, proven technologies like namespace isolation or Linux kernel cgroups. By building upon leading technologies, Docker relieved many existing pain points.
Web3 is similar. We should pick the right technologies to achieve our goals. And luckily innovations like blockchains have become mature enough to support the projects where they’re needed.
Content-addressable world
One barrier to creating a fully decentralized system is creating globally unique, decentralized identifiers for all services items. When somebody creates a new identifier, we must ensure it’s truly one of a kind.
There’s no easy fix, but blockchains can help. After all, chains are the central source of truth (agreed on by thousands of participants in a decentralized way).
There’s another way to solve this problem. It’s very easy to choose a unique identifier if there’s only one option and the choice is obvious. For example, if any content is identified with its hash, then that’s the unique identifier. If the content is the same, the unique identifier (the hash itself) will always be.
One example is Git, which is made for distribution. Every commit is identified by its hash (metadata, pointers to parents, pointers to the file trees). This made Git decentralization-friendly. While most repositories are hosted by big companies, it’s pretty easy to shift content between providers. This was an earlier problem we were trying to solve.
IPFS — as a decentralized content routing protocol — also pairs hashes with pieces to avoid any confusion between decentralized nodes. It also created a full ecosystem to define notation for different hashing types (multihash), or different data structures (IPLD).
We see exactly the same thing when we look at Docker containers! The digest acts as a content-based hash and can identify layers and manifests. This makes it easy to verify them and get them from different sources without confusion. Docker was designed to be decentralized from the get go.
Federation
Content-based digests of container layers and manifests help us, since Docker is usable with any kind of registry.
This is a type of federation. Even if Docker Hub is available, it’s very easy to start new registries. There’s no vendor lock-in, and there’s no grueling process behind being listed on one single possible marketplace. Publishing and sharing new images is as painless as possible.
As we discussed above, I believe the federation is one form of decentralization, and decentralization is one approach to get what we need: better control and ownership. There are stances against federation, but I believe federation offers more benefits despite its complexity. Many hard-forks, soft-forks, and blockchain restarts prove that control (especially democratic control) is possible with federation.
But we can call it in any other way. I believe that the freedom of using different container registries and the process of deploying containers are important factors in the success of Docker containers.
Summary
We’ve successfully defined Web3 based on end goals and user feedback — or “what” needs to be achieved. And this definition seems to be working very well. It’s mindful of “how” we achieve those goals. It also includes the use of existing “Web2” technologies and many future projects, even without using NFTs or blockchains. It even excludes the fraudulent projects which have drawn much skepticism.
We’ve also found some interesting intersections between Web3 and Docker!
Our job is to keep working and keep innovating. We should focus on the goals ahead and find the right technologies based on those goals.
Next up, we’ll discuss fields that are more technical. Join us as we explore using Docker with fully distributed storage options.
Quelle: https://blog.docker.com/feed/