Introducing Docker MCP Catalog and Toolkit: The Simple and Secure Way to Power AI Agents with MCP
Model Context Protocols (MCPs) are quickly becoming the standard for connecting AI agents to external tools, but the developer experience hasn’t caught up. Discovery is fragmented, setup is clunky, and security is too often bolted on last. Fixing this experience isn’t a solo mission—it will take an industry-wide effort. A secure, scalable, and trusted MCP ecosystem demands collaboration across platforms and vendors.
That’s why we’re excited to announce Docker MCP Catalog and Toolkit are now available in Beta. The Docker MCP Catalog, now a part of Docker Hub, is your starting point for discovery, surfacing a curated set of popular, containerized MCP servers to jumpstart agentic AI development. But discovery alone isn’t enough. That’s where the MCP Toolkit comes in. It simplifies installation, manages credentials, enforces access control, and secures the runtime environment. Together, Docker MCP Catalog and MCP Toolkit give developers and teams a complete foundation for working with MCP tools, making them easier to find, safer to use, and ready to scale across projects and teams.
We’re partnering with some of the most trusted names in cloud, developer tooling, and AI, including Stripe, Elastic, Heroku, Pulumi, Grafana Labs, Kong Inc., Neo4j, New Relic, Continue.dev, and many more, to shape a secure ecosystem for MCP tools. With a one-click connection right from Docker Desktop to leading MCP clients like Gordon (Docker AI Agent), Claude, Cursor, VSCode, Windsurf, continue.dev, and Goose, building powerful, intelligent AI agents has never been easier.
This aligns perfectly with our mission. Docker pioneered the container revolution, transforming how developers build and deploy software. Today, over 20 million registered developers rely on Docker to build, share, and run modern applications. Now, we’re bringing that same trusted experience to the next frontier: Agentic AI with MCP tools.
Model Context Protocol is gaining momentum — what improvements are still needed?
As MCPs become the backbone of agentic AI systems, the developer experience still faces key challenges. Here are some of the major hurdles:
Discovering the right, official, and/or trustworthy tools is hard
Finding MCP servers is fragmented. Developers search across registries, community-curated lists, and blog posts—yet it’s still hard to know which ones are official and trustworthy.
Complex installations and distribution
Getting started with MCP tools remains complex. Developers often have to clone repositories, wrangle conflicting dependencies in environments like Node.js or Python, and self-host local services—many of which aren’t containerized, making setup and portability even harder. On top of that, connecting MCP clients adds more friction, with each one requiring custom configuration that slows down onboarding and adoption.
Auth and permissions fall short
Many MCP tools run with full access to the host, launched via npx or uvx, with no isolation or sandboxing. Credentials are commonly passed as plaintext environment variables, exposing sensitive data and increasing the risk of leaks. Moreover, these tools often aren’t designed for scale and security. They’re missing enterprise-ready features like policy enforcement, audit logs, and standardized security.
How Docker can help solve these challenges
The Docker MCP Catalog and Toolkit are designed to address the above pain points by securely streamlining the discovery, installation, and authentication of MCP servers — making it easy to connect with your favorite MCP clients.
Discover and run MCP servers easily in secure, isolated containers
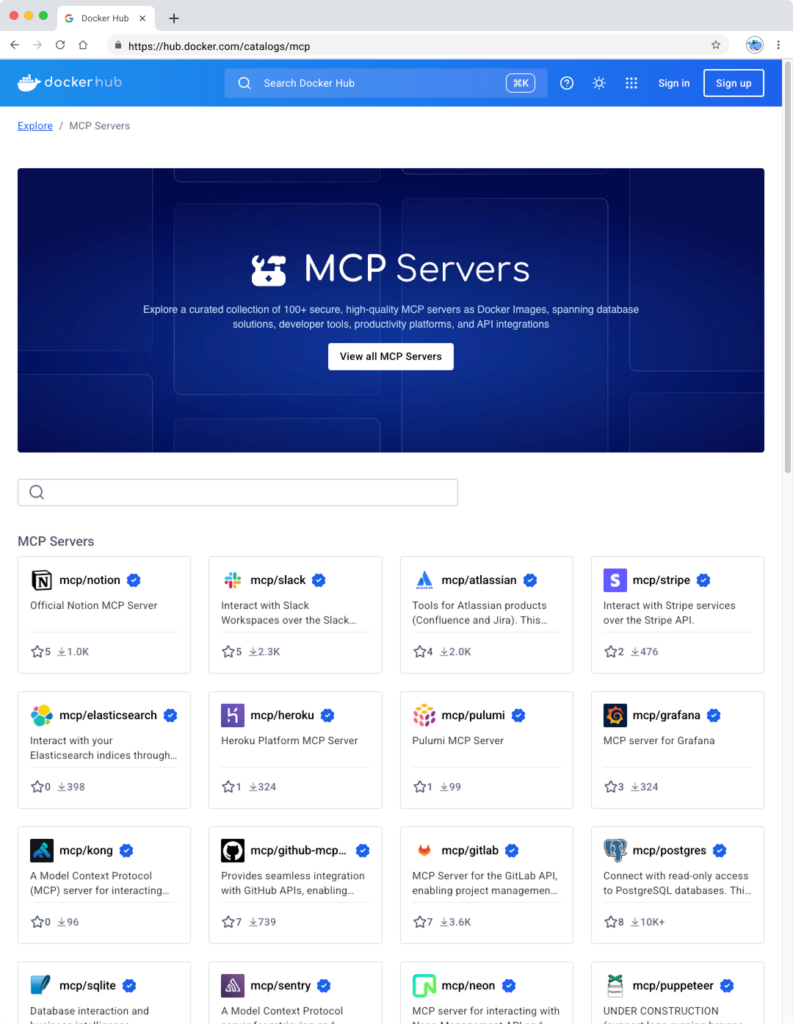
The MCP Catalog makes it easy to discover and access 100+ MCP servers — including Stripe, Elastic, Neo4j, and many more — all available on Docker Hub. With the MCP Toolkit Docker Desktop extension, you can quickly and securely run and interact with these servers. By packaging MCP servers as containers, developers can sidestep common challenges such as runtime setup, dependency conflicts, and environment inconsistencies — just run the container, and it works.
Figure 1: Discover curated and popular MCP servers in Docker MCP Catalog, part of the Docker Hub
We’re not just simplifying discovery and installation — we’re placing security at the heart of the MCP experience. Because MCPs run inside Docker container images, they inherit the same built-in security features developers already trust and a rich ecosystem of tools for securing software throughout the supply chain. And we’re going further. The Docker MCP Toolkit addresses emerging threats unique to MCP servers like Tool Poisoning and Tool Rug Pulls, by leveraging Docker’s strong position as both a provider of secure content and secure runtimes.
Figure 2: The MCP Toolkit Docker Desktop Extension allows you to easily and securely run MCP servers in containers.
Go to the extensions menu of Docker Desktop to get started with Docker MCP Catalog and Toolkit, or use this for installation. Check out our doc for more information.
One-Click MCP Client Integration with Built-In Secure Authentication
While a curated list of MCPs and simplified security is a great starting point, it’s just the beginning. You can connect popular MCP servers from the Docker MCP Catalog to any MCP client. For clients like Gordon (Docker AI Agent), Claude, Cursor, VSCode, Windsurf, continue.dev, and Goose, one-click setup will make integration seamless.
The Docker MCP Toolkit includes built-in OAuth support and secure credential storage, enabling clients to authenticate with MCP servers and third-party services without hardcoding secrets into environment variables. This ensures your MCP tools run securely and reliably right from the start.
Figure 3: Easily connect to your favorite MCP clients like Gordon, Claude, Cursor, and continue.dev with one click.
Enterprise-Ready MCP Tooling: Build, manage, and share in Docker Hub
Soon, you’ll be able to build and share your own MCPs on Docker Hub—home to over 14 million images, millions of active users, and a robust ecosystem of trusted content. Teams count on Docker Hub for verified images, deep image analysis, lifecycle management, and enterprise-grade tooling. Those same trusted capabilities will soon extend to MCPs, giving teams access to the latest tools and a secure, reliable way to distribute their own. And just like container images, MCPs will integrate with enterprise features like Registry Access Management and Image Access Management, ensuring secure, streamlined developer workflows from end to end.
Wrapping up
Docker MCP Catalog and Toolkit bring much-needed structure, security, and simplicity to the fast-growing world of MCP tools. By standardizing how MCP servers are discovered, installed, and secured, we’re removing friction for developers building smarter, more capable AI-powered applications and agents.
Whether you’re connecting to external tools, customizing workflows, or scaling automation inside your IDE, Docker makes the entire process easy and secure. And this is just the beginning. With ongoing investments in expanding the MCP ecosystem and streamlining how tools are managed, we’re committed to making powerful AI tooling accessible to every team.
With Docker Catalog and Toolkit, your AI agent isn’t limited by what’s built in — it’s empowered by everything you can plug in.
Go to the extensions menu of Docker Desktop to get started with Docker MCP Catalog and Toolkit, or use this for installation. See it in action during our upcoming webinar. Interested in hosting your MCP servers on Docker? Let’s connect.
Learn more
Get started with Docker MCP Catalog and Toolkit
Join the webinar for a live technical walkthrough.
Visit our MCP webpage
Authenticate and update today to receive your subscription level’s newest Docker Desktop features.
Subscribe to the Docker Navigator Newsletter.
New to Docker? Create an account.
Have questions? The Docker community is here to help.
Quelle: https://blog.docker.com/feed/