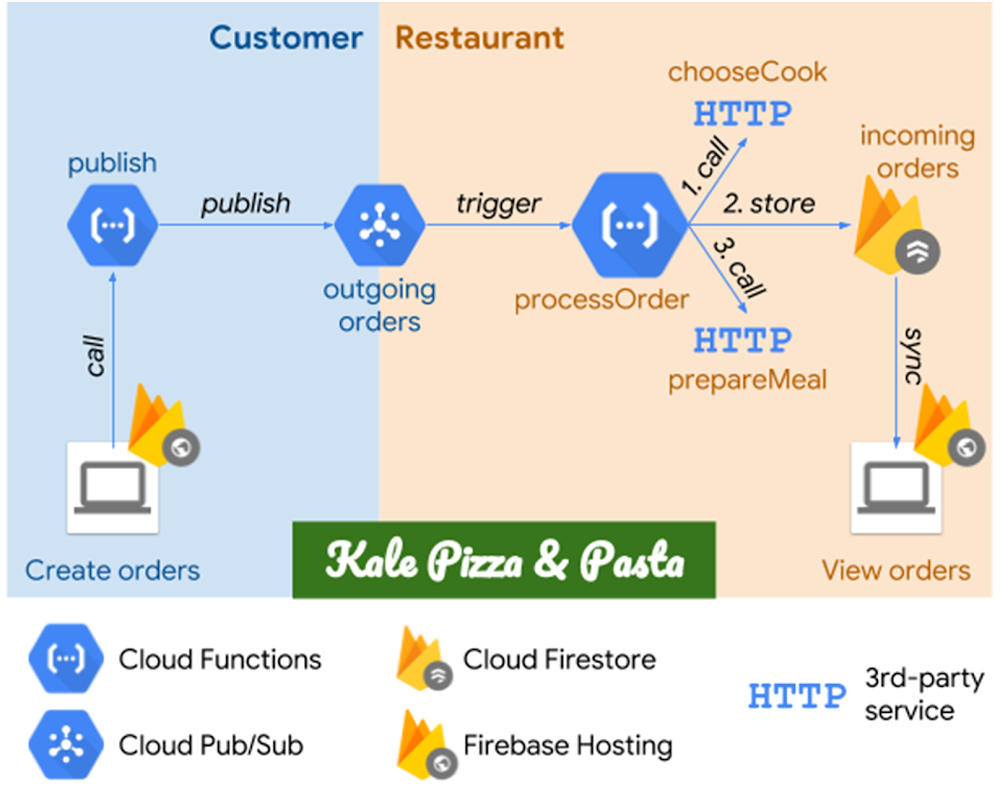
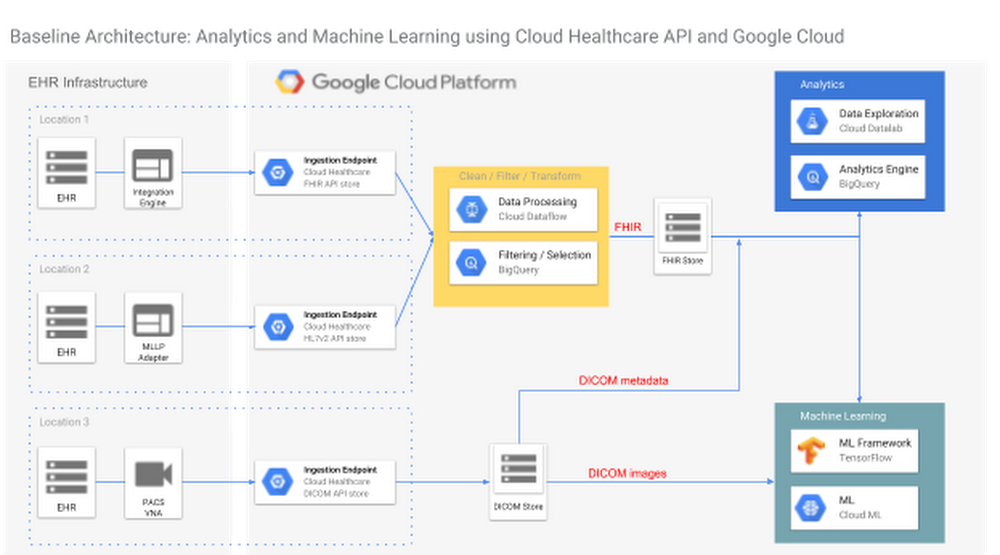
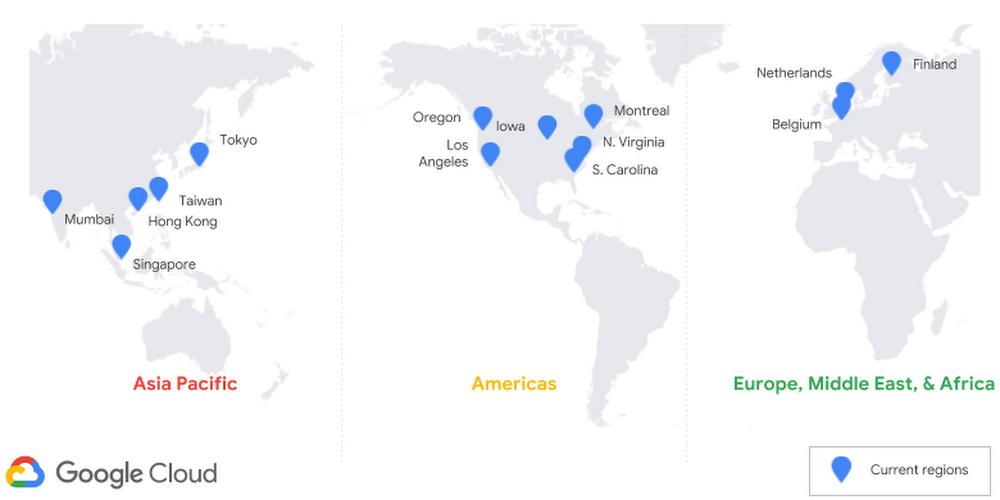
Every GCP blog post from 2018
Looking for a little light reading over the holidays? Below, we’ve compiled a list of all 557 (!) blog posts we published on GCP in 2018.Pro tip: Although we’ve listed these posts by month, you can also find them grouped by themes by clicking our topic tags, for example: AI & machine learning, data analytics, Kubernetes, databases, DevOps & SRE, networking, security, serverless, storage—and many, many more.JanuaryWhat Google Cloud, G Suite and Chrome customers need to know about the industry-wide CPU vulnerabilityCRE life lessons: Consequences of SLO violationsSimplify Cloud VPC firewall management with service accountsIntroducing Preemptible GPUs: 50% OffAnswering your questions about “Meltdown” and “Spectre”[Whitepaper] Lift and shift to Google Cloud PlatformProblem-solving with ML: automatic document classificationTrash talk: How moving Apigee Sense to GCP reduced our “data litter” and decreased our costsProtecting our Google Cloud customers from new vulnerabilities without impacting performanceStateful and ML workloads now run better on Google Kubernetes Engine with the latest version 1.9Why you should pick strong consistency, whenever possibleThree ways to configure robust firewall rulesExpanding our global infrastructure with new regions and subsea cables[Tutorial] Running dedicated game servers in Kubernetes EngineCloud AutoML: Making AI accessible to every businessAnalyzing your BigQuery usage with Ocado Technology’s GCP Census[Whitepaper] Embark on a journey from monoliths to microservicesCRE life lessons: An example escalation policyA guide to machine learning for the chronically curious: ML ExplorerHow we built a serverless digital archive with machine learning APIs, Cloud Pub/Sub and Cloud FunctionsCloud Shell Tutorials: Learning experiences integrated into the Cloud ConsoleOrbitera and MobileIron team up to make it easier to buy and sell apps in the cloudGoogle Cloud Platform opens region in the NetherlandsFiner-grained security using custom roles for Cloud IAMFebruaryUse Forseti to make sure your Google Kubernetes Engine clusters are updated for “Meltdown” and “Spectre”[Whitepaper] Modernizing your .NET Application for Google CloudGCP arrives in Canada with launch of Montréal regionHow to process weather satellite data in real-time in BigQueryToward effective cloud governance: designing policies for GCP customers large and small12 best practices for user account, authorization and password managementHow to use Weaveworks free tier for continuous delivery, monitoring and alerts for Kubernetes EngineAnnouncing Spring Cloud GCP—integrating your favorite Java framework with Google CloudWhy we used Elastifile Cloud File System on GCP to power drug discoveryGCP is building its second Japanese region in OsakaBitcoin in BigQuery: blockchain analytics on public dataCRE life lessons: Applying the Escalation PolicyEasy distributed training with TensorFlow using tf.estimator.train_and_evaluate on Cloud ML EngineIn our genes: How Google Cloud helps the Broad Institute slash the cost of researchCloud TPU machine learning accelerators now available in betaGPUs in Kubernetes Engine now available in betaPractice makes perfect: the Professional Data Engineer Practice Exam is now liveGet the most out of Google Kubernetes Engine with Priority and Preemption96 vCPU Compute Engine instances are now generally availableGoogle announces intent to acquire XivelyThe thing is . . . Cloud IoT Core is now generally availableManaging your Compute Engine instances just got easierCreating a single pane of glass for your multi-cloud Kubernetes workloads with CloudflareHow Google Cloud Storage offers strongly consistent object listing thanks to SpannerHow to handle mutating JSON schemas in a streaming pipeline, with Square EnixAnnouncing Google Cloud Spanner as a Vault storage backendGoogle Cloud and NCAA team up for a unique March Madness competition hosted on KaggleNew research: How to evolve your security for the cloudGoogle Cloud’s Response to Australian Privacy Principles (APP) and Australian Prudential Regulation Authority (APRA) RequirementsIntroducing Cloud Billing Catalog API: GCP pricing in real timeCloud poetry: training and hyperparameter tuning custom text models on Cloud ML EngineAnnouncing SSL policies for HTTPS and SSL proxy load balancersFully managed export and import with Cloud Datastore now generally availableMarchComparing regression and classification on US elections data with TensorFlow EstimatorsQueue-based scaling made easy with new Stackdriver per-group metricsHow Color uses the new Variant Transforms tool for breakthrough clinical data science with BigQueryGoogle Cloud for Healthcare: new APIs, customers, partners and security updatesExpanding the reach of Google Cloud Platform’s HIPAA-compliant offerings for healthcareFrom open source to sustainable success: the Kubernetes graduation storyLearn to run Apache Spark natively on Google Kubernetes Engine with this tutorialOptimizing your Cloud Storage performance: Google Cloud Performance AtlasGetting to know Cloud IAMIntroducing GCP’s new interactive CLIPredicting community engagement on Reddit using TensorFlow, GDELT, and Cloud Dataflow: Part 1Announcing new Stackdriver pricing—visibility for lessIntroducing Agones: Open-source, multiplayer, dedicated game-server hosting built on KubernetesHyperparameter tuning on Google Cloud Platform is now faster and smarterAutomatic serverless deployments with Cloud Source Repositories and Container BuilderBest practices for working with Google Cloud Audit LoggingIntroducing Skaffold: Easy and repeatable Kubernetes developmentGCP grows in the Netherlands region8 DevOps tools that smoothed our migration from AWS to GCP: TamrSecurity in the cloudGoogle Cloud Next ’18—Registration now open!Introducing new ways to protect and control your GCP services and dataJoining and shuffling very large datasets using Cloud DataflowNetwork policies for Kubernetes are generally availableUnderstand your spending at a glance with Google Cloud Billing reports betaPublic datasets: how nonprofits can drive social impact with planetary-scale dataNew ways to secure businesses in the cloudExpanding our Google Cloud security partnershipsIntroducing new ways to protect and control your GCP services and dataPre-built Cloud Dataflow templates: KISS for data movementCloud Identity: Manage users, devices and apps in one locationBuilding trust through Access TransparencyExtending GCP security to U.S. government customers through FedRAMP authorizationTake charge of your sensitive data with the Cloud Data Loss Prevention (DLP) APIExpanding MongoDB Atlas availability on GCPEasy HPC clusters on GCP with SlurmAutoML Vision in action: from ramen to branded goodsGetting to know Cloud Armor—defense at scale for internet-facing servicesKubernetes Engine Private Clusters now available in betaKubernetes 1.10: an insider take on what’s newHow Tokopedia modernized its data warehouse and analytics processes with BigQuery and Cloud DataflowIntroducing Cloud Text-to-Speech powered by DeepMind WaveNet technologyMonitor your GCP environment with Cloud Security Command CenterHow we used Cloud Spanner to build our email personalization system—from “Soup” to nutsTesting future Apache Spark releases and changes on Google Kubernetes Engine and Cloud DataprocIntroducing Stackdriver APM and Stackdriver ProfilerNow, you can automatically document your API with Cloud EndpointsSimplifying machine learning on open hybrid clouds with KubeflowExploring container security: An overviewAPI design: Which version of versioning is right for you?Tip off: how we’re using predictive analytics during the Final FourPredicting community engagement on Reddit using TensorFlow, GDELT, and Cloud Dataflow: Part 3Announcing Google Cloud Security Talks during RSA Conference 2018How to export logs from Stackdriver Logging: new solution documentationAprilUsing BigDL for deep learning with Apache Spark and Google Cloud DataprocGoogle Cloud using P4Runtime to build smart networksHow to run Windows Containers on Compute EngineStretching Elastic’s capabilities with historical analysis, backups, and cross-cloud monitoring on Google Cloud PlatformExpanding our cloud network for a faster, more reliable experience between Australia and Southeast AsiaNew ways to manage and automate your Stackdriver alerting policiesOro: How GCP smoothed our path to PCI DSS complianceServing real-time scikit-learn and XGBoost predictionsIntroducing VPC Flow Logs—network transparency in near real-timeNow, you can deploy to Kubernetes Engine from GitLab with a few clicksExploring container security: Node and container operating systemsViewing Stackdriver Trace spans and request logs in multi-project deploymentsToward better phone call and video transcription with new Cloud Speech-to-TextGoogle named a Leader in the Forrester Public Cloud Development Platform Wave, Q2 2018Introducing Kayenta: An open automated canary analysis tool from Google and NetflixHow to dynamically generate GCP IAM credentials with a new HashiCorp Vault secrets engineBigQuery lazy data loading: SQL data languages (DDL and DML), partitions, and half a trillion Wikipedia pageviewsHow to automatically scan Cloud Storage buckets for sensitive data: Taking charge of your securityBest practices for securing your Google Cloud databasesExploring container security: Digging into Grafeas container image metadataCloud-native architecture with serverless microservices—the Smart Parking storyReflecting on our ten year App Engine journey[Whitepaper] Running your modern .NET Application on KubernetesIntroducing kaniko: Build container images in Kubernetes and Google Container Builder without privilegesImproving the Google Cloud Storage backend for HashiCorp VaultBigQuery arrives in the Tokyo regionDialogflow Enterprise Edition is now generally availableCloud SQL for PostgreSQL now generally available and ready for your production workloadsExploring container security: Protecting and defending your Kubernetes Engine networkKubernetes best practices: How and why to build small container imagesEngineered for renewal: Google Cloud, Etsy and sustainabilityTwo higher ed collaborations expand access to Google Cloud PlatformIntroducing Partner Interconnect, a fast, economical onramp to GCPNow live in Tokyo: using TensorFlow to predict taxi demandAccelerating innovation for cloud-native managed databasesGoogle Cloud Platform announces new credits program for researchersExploring container security: Running a tight ship with Kubernetes Engine 1.10Introducing Kubernetes Service Catalog and Google Cloud Platform Service Broker: find and connect services to your cloud-native appsAccessing external (federated) data sources with BigQuery’s data access layerKubernetes best practices: Organizing with NamespacesRegistration for the Associate Cloud Engineer beta exam is now openAnnouncing variable substitution in Stackdriver alerting notificationsNew collaboration with Fitbit to drive positive health outcomesExpanding our GPU portfolio with NVIDIA Tesla V100MayCloud Composer is now in beta: build and run practical workflows with minimal effortIntroducing the Kubernetes Podcast from GoogleRegional replication for Cloud Bigtable now in betaScale big while staying small with serverless on GCP—the Guesswork.co storyApigee named a Leader in the Gartner Magic Quadrant for Full Life Cycle API Management for the third consecutive timeAnnouncing SAP CodeJams for Google Cloud Platform: learn to integrate SAP HANA with GCPAnnouncing Stackdriver Kubernetes Monitoring: Comprehensive Kubernetes observability from the startOpen-sourcing gVisor, a sandboxed container runtimeQueue your questions: common queries from Google Cloud customersIntroducing Asylo: an open-source framework for confidential computingExploring container security: Using Cloud Security Command Center (and five partner tools) to detect and manage an attackBuilding an image search application using Cloud Vision APIKubernetes best practices: Setting up health checks with readiness and liveness probesMusic in motion: a Firebase and IoT storyBigQuery at speed: new features help you tune your query execution for performanceCRE life lessons: Defining SLOs for services with dependenciesGCP is building a region in ZürichGoogle Cloud and NetApp collaborate on cloud-native, high performance storageSRE vs. DevOps: competing standards or close friends?Building a serverless mobile development pipeline on GCP: new solution documentationGoogle announces intent to acquire VelostrataIntroducing Cloud Memorystore: A fully managed in-memory data store service for RedisUsing Jenkins on Google Compute Engine for distributed buildsTransform publicly available BigQuery data and Stackdriver logs into graph databases with Neo4jGoogle Cloud: Ready for the GDPRKubernetes best practices: Resource requests and limitsExploring container security: Isolation at different layers of the Kubernetes stackGoogle Cloud for Life Sciences: new products and new partnersThree steps to prepare your users for cloud data migrationOpening a third zone in SingaporeIntroducing ultramem Google Compute Engine machine typesIncrease performance while reducing costs with the new App Engine schedulerUnderstanding native container routing with Alias IPsGoogle Maps Platform now integrated with the GCP ConsoleGetting more value from your Stackdriver logs with structured dataSharding of timestamp-ordered data in Cloud SpannerKubernetes best practices: terminating with graceCloud ML Engine adds Cloud TPU support for trainingGoogle Kubernetes Engine 1.10 is generally available and ready for the enterpriseGoogle Cloud Platform and Confluent partner to deliver a managed Apache Kafka serviceDialogflow adds versioning and other new features to help enterprises build vibrant conversational experiencesIntroducing Shared VPC for Google Kubernetes EngineNew machine learning specialization on Coursera teaches you to build production-ready models on GCPGet higher availability with Regional Persistent Disks on Google Kubernetes EngineGoogle Cloud named a leader in latest Forrester Research Public Cloud Platform Native Security WaveBetter cost control with Google Cloud Billing programmatic notificationsBeyond CPU: horizontal pod autoscaling with custom metrics in Google Kubernetes EngineStackdriver brings powerful alerting capabilities to the condition editor UIKubernetes best practices: mapping external servicesGoogle is named a leader in the 2018 Gartner Infrastructure as a Service Magic QuadrantIntroducing VPC-native clusters for Google Kubernetes EngineGain visibility and take control of Stackdriver costs with new metrics and toolsPartnering with KPMG to help more enterprises transform their businessesCloud Source Repositories: more than just a private Git repositorySecuring cloud-connected devices with Cloud IoT and MicrochipTroubleshooting tips: How to talk so your cloud provider will listen (and understand)JuneKubernetes best practices: upgrading your clusters with zero downtimeLast month today: GCP in MayRegional clusters in Google Kubernetes Engine are now generally available7 tips to maintain security controls in your GCP DR environmentHow to deploy geographically distributed services on Kubernetes Engine with kubemciBuilding on our SAP partnership: Working together to help businesses thriveA closer look at the HANA ecosystem on Google Cloud PlatformOCTO: Google Cloud’s two-way innovation streetIntroducing sole-tenant nodes for Google Compute Engine—when sharing isn’t an optionWhat DBAs need to know about Cloud Spanner, part 1: Keys and indexesTime to “Hello, World”: VMs vs. containers vs. PaaS vs. FaaSThe latest on our work with Cisco to help businesses on their journey to the cloudDoing DevOps in the cloud? Help us serve you better by taking this surveyIntroducing improved pricing for Preemptible GPUsNow, you can deploy your Node.js app to App Engine standard environmentIntroducing QUIC support for HTTPS load balancingLabelling and grouping your Google Cloud Platform resourcesIntroducing Cloud Dataflow’s new Streaming EngineBehind the scenes with the Dragon Ball Legends GCP backendPartner Interconnect now generally availableTry full-stack monitoring with Stackdriver on usPutting a Groovy twist on Cloud VisionGCP arrives in the Nordics with a new region in FinlandPowering up connected game development through our alliance with UnityCloud TPU now offers preemptible pricing and global availabilityBuilding scalable web applications with Cloud Datastore—new solutionGPUs as a service with Kubernetes Engine are now generally availableML Explorer: talking and listening with Google Cloud using Cloud Speech and Text-to-SpeechHow to run SAP Fiori Front-End Server (OpenUI5) on GCP in 20 minsAnnouncing a new certification from Google Cloud Certified: the Associate Cloud EngineerHow to connect Stackdriver to external monitoringHow RealtimeCRM built a business card reader using machine learningSix essential security sessions at Google Cloud Next 18Protect your Compute Engine resources with keys managed in Cloud Key Management ServiceGoogle Cloud for Electronic Design Automation: new partnersRunning format transformations with Cloud Dataflow and Apache BeamLights, camera, cloud: new tools for our media and entertainment customersNew Cloud Filestore service brings GCP users high-performance file storageBust a move with Transfer Appliance, now generally available in U.S.6 must-see sessions on AI and machine learning at Next ‘18Announcing MongoDB Atlas free tier on GCPWhy we believe in an open cloudCRE life lessons: Understanding error budget overspend (part one)BigQuery in June: a new data type, new data import formats, and finer cost controlsDataflow Stream Processing now supports PythonNew GitHub repo: Using Firebase to add cloud-based features to games built on UnityPreparing for a BeyondCorp world at your companyJulyKubernetes 1.11: a look from inside GoogleLast month today: GCP in JuneIntroducing Endpoint Verification: visibility into the desktops accessing your enterprise applicationsFive can’t-miss application development sessions at Google Cloud Next ‘18Connecting the dots: how the cloud operating model meets enterprise CIO needsIntroducing Jib—build Java Docker images betterPredict your future costs with Google Cloud Billing cost forecastGoogle Cloud hosts weekend-long event with DataKind to solve real-world challenges with dataHow to train a ResNet image classifier from scratch on TPUs on Cloud ML EngineMeasuring patent claim breadth using Google Patents Public Datasets7 best practices for building containers6 must-see sessions on the Internet of Things (IoT) at Next ‘187 must-see sessions on data analytics at Next ‘18Verifying PostgreSQL backups made easier with new open-source toolIntroducing new Apigee capabilities to deliver business impact with APIsGoogle Home meets .NET containers using DialogflowUsing Apache Spark DStreams with Cloud Dataproc and Cloud Pub/SubOur Los Angeles cloud region is open for businessDelivering increased connectivity with our first private trans-Atlantic subsea cableCloud Spanner adds import/export functionality to ease data movementGoogle Cloud AI Huddle: an open, collaborative, and developer-first AI forum driven by Google AI expertiseNow shipping: ultramem machine types with up to 4TB of RAMTop storage and database sessions to check out at Next 2018Introducing commercial Kubernetes applications in GCP MarketplaceDeveloping a JanusGraph-backed Service on Google Cloud PlatformMaking healthcare better for everyone—including providersKubernetes wins OSCON Most Impact AwardSRE fundamentals: SLIs, SLAs and SLOsVMware and Google Cloud: building the hybrid cloud together with vRealize OrchestratorBringing GPU-accelerated analytics to GCP Marketplace with MapD5 must-see network sessions at Google Cloud NEXT 2018Learning from our customers at Google Cloud Next ‘18Building a better cloud with our partners at Next ‘18Banking on the cloud: how financial services organizations are embracing cloud technologyPartnering with Intel and SAP on Intel Optane DC Persistent Memory for SAP HANATransforming the contact center with AIWorking with Accenture to help enterprises move to the cloudSky’s the limit: How businesses across every industry are taking advantage of Google CloudBuilding a global biomedical data ecosystem with the National Institutes of HealthBringing the best of serverless to youCloud Services Platform: bringing the best of the cloud to youUnlocking data analytics and machine learning for more businessesEmpowering businesses and developers to do more with AIBridging the gap between data and insightsBuilding on our cloud security leadership to help keep businesses protectedBringing intelligence to the edge with Cloud IoTData Solutions for Change: empowering nonprofits through large-scale analyticsAnnouncing resource-based pricing for Google Compute EngineOn GCP, your database your wayGoogle Cloud and GitHub collaborate to make CI fast and easyAccelerating software teams with Cloud BuildWhat a week! 105 announcements from Google Cloud Next ’18Transparent SLIs: See Google Cloud the way your application experiences itPreparing and curating your data for machine learningPreparing for a BeyondCorp world: Understanding your device inventoryDrilling down into Stackdriver Service MonitoringPerforming large-scale mutations in BigQueryIstio reaches 1.0: ready for prodAccess Google Cloud services, right from IntelliJ IDEAAugustA review of input streaming connectors for Apache Beam and Apache SparkRepairing network hardware at scale with SRE principlesGoogle is named a leader in the 2018 Gartner Magic Quadrant for Public Cloud Storage ServicesLast month today: July on GCPHortonworks and Google Cloud collaborate to expand data analytics offeringsWe’ve moved! Come see our new home!Introducing NVIDIA Tesla P4 GPUs for accelerating virtual workstations and ML inference on Compute EngineVirtual Trusted Platform Module for Shielded VMs: security in plaintextSecurity in plaintext: use Shielded VMs to harden your GCP workloadsSimple backup and replay of streaming events using Cloud Pub/Sub, Cloud Storage, and Cloud DataflowIntroducing App Engine Second Generation runtimes and Python 3.7Calling Java developers: Spring Cloud GCP 1.0 is now generally availableExpanding the Cloud Firestore beta to more usersGoogle Cloud’s continuing commitment to advance healthcare data interoperabilityA closer look at our newest Google Cloud AI capabilities for developers7 best practices for operating containersCloud Functions serverless platform is generally availableRobot dance party: How we created an entire animated short at Next ‘18Protecting against the new “L1TF” speculative vulnerabilitiesKubernetes Podcast rewind: What you missedPerforming VM mass migrations to Google Cloud with VelostrataWhat’s happening in BigQuery: integrated machine learning, maps, and moreIntroducing headless Chrome support in Cloud Functions and App EngineCloud AI Solutions: helping more industries solve common challenges with AIManaging Java dependencies for Apache Spark applications on Cloud DataprocHelping SaaS companies run reliably on Google CloudBuilding a hybrid render farm on GCP—new guide availableHyperparameter tuning using TPUs in Cloud ML EngineIntroducing Cloud HSM beta for hardware crypto key securityDeploy only what you trust: introducing Binary Authorization for Google Kubernetes EngineWho is this street artist? Building a graffiti artist classifier using AutoMLIntroducing PHP 7.2 runtime on the App Engine standard environmentDistributed optimization with Cloud DataflowUsing your existing identity management system with Google Cloud PlatformUsing BigQuery ML and BigQuery GIS together to predict NYC taxi trip costAutomatic documentation for your Cloud Endpoints API, now in GATesla V100 GPUs are now generally availableAnnouncing updates to Cloud Speech-to-Text and the general availability of Cloud Text-to-SpeechEthereum in BigQuery: a Public Dataset for smart contract analyticsNew research: what sets top-performing DevOps teams apartGoogle Cloud grants $9M in credits for the operation of the Kubernetes projectWhat makes TPUs fine-tuned for deep learning?Expanding our Public Datasets for geospatial and ML-based analyticsCloud Bigtable regional replication now generally availableTitan Security Keys: Now available on the Google StorePre-processing for TensorFlow pipelines with tf.Transform on Google CloudSeptemberLast month today: August on GCPOpen Match: Flexible and extensible matchmaking for gamesCisco Hybrid Cloud Platform for Google Cloud: Now generally availableA flexible way to deploy Apache Hive on Cloud DataprocHow Distributed Shuffle improves scalability and performance in Cloud Dataflow pipelinesAccess Transparency logs now generally available for six GCP servicesHow to deploy a TeamCity Continuous Integration solution to Google CloudIntroducing the Google Cloud blog: Our new home for cloud news, guides and storiesTrust through transparency: incident response in Google CloudUsing Stackdriver Workspaces to help manage your hybrid and multicloud environmentDeleting your data in Google Cloud PlatformEthereum in BigQuery: how we built this datasetCloud covered: What’s new with Cloud in AugustCloud TPUs in Kubernetes Engine powering Minigo are now available in betaIntroducing Cloud Inference API: uncover insights from large scale, typed time-series dataMaking connected games a reality for all developersNew Qwiklabs Quest available: Data Science on Google Cloud PlatformGoogle Cloud completes BSI C5 auditThe 5 most popular breakout sessions from Google Cloud Next ‘18 (according to YouTube)AI in motion: designing a simple system to see, understand, and react in the real world (Part I)Ibis and BigQuery: scalable analytics with the comfort of PythonIntroducing the Google Cloud Advanced Solutions Lab in Tokyo: Helping businesses do more with AIWorking with NEC to better serve Japanese enterprisesAnnouncing general availability of Cloud Memorystore for RedisGuard against security vulnerabilities in your software supply chain with Container Registry vulnerability scanningIntroducing new Cloud Source RepositoriesUnlock insights with ease: Data Studio and Cloud Dataprep are now generally availableNow on Coursera: Advanced Machine Learning with TensorFlow on Google Cloud PlatformSimplifying ML predictions with Google Cloud FunctionsSecuring your business and securing your fleet the BeyondCorp wayVisualize 2030: Google Cloud hosts data storytelling contest with the United Nations Foundation, the World Bank, and the Global Partnership for Sustainable Development DataA quick and easy way to set up an end-to-end IoT solution on Google Cloud PlatformA Kubernetes FAQ for the C-suiteScale Computing: Using hyperconverged infrastructure and cloud together for flexible DRProgress and updates on our partnership with SalesforceLaunching new GCP Support models: Role-Based and EnterpriseDigging into Kubernetes 1.12Register for a free 1:1 AI advisory consultation at Gartner SymposiumIntroducing private networking connection for Cloud SQLAnnouncing Cloud Tasks, a task queue service for App Engine flex and second generation runtimesAdding custom intelligence to Gmail with serverless on GCPOctoberBigQuery and surrogate keys: a practical approachDesigning and implementing your disaster recovery plan using GCPIntroducing PyTorch across Google CloudBuild it like you MEAN it with MongoDB Atlas on GCP[Whitepaper] The guide to financial governance in the cloudHow to transfer BigQuery tables between locations with Cloud ComposerGoogle Cloud Platform: Your cloud destination for mission critical SAP workloadsNetwork controls in GCP vs. on-premises: Not so different after allSecuring Kubernetes with GKE and Sysdig FalcoLast month today: September on GCPIs that a device driver, golf driver, or taxi driver? Building custom translation models with AutoML TranslateA strategy for implementing industrial predictive maintenance: Part IGCP infrastructure and operations: watch and learnA developer onramp to Kubernetes with GKEHow Traveloka built a Data Provisioning API on a BigQuery-based microservice architectureGain insights about your GCP resources with asset inventoryHow ZSL is working to protect at-risk animals and foster healthy ecosystems with the help of Google CloudBigQuery arrives in the London region, with more regions to comeHelping organizations increase visibility and control of cloud resourcesHow METRO AG is migrating its SAP finance systems to Google CloudBetter together: Working with EMEA businesses to help them do more in the cloudAI in motion: designing a simple system to see, understand, and react in the real world (Part II)Simplifying cloud networking for enterprises: announcing Cloud NAT and moreAccelerate with APIs: Apigee API monitoring, extensions and hosted targets now generally availableDevelop and deploy apps more easily with Cloud Spanner and Cloud Bigtable updatesStore it, analyze it, back it up: Cloud Storage updates bring new replication optionsSimplifying identity and access management for more businessesBuilding a more reliable infrastructure with new Stackdriver tools and partnersWhat’s happening in BigQuery: a new ingest format, data type updates, ML, and query schedulingIntroducing container-native load balancing on Google Kubernetes EngineWatch and learn: Kubernetes and GKE for developersServerless in action: building a simple backend with Cloud Firestore and Cloud FunctionsThe Halite competition returns, to teach ML enthusiasts how to design for intelligent machinesGet more control over your Compute Engine resources with new Cloud IAM featuresREST vs. RPC: what problems are you trying to solve with your APIs?On cats, TPUs, and pushing the boundaries of our imaginationMender and Cloud IoT facilitate robust device update managementCloud NAT: deep dive into our new network address translation serviceGo 1.11 is now available on App EngineIs there life on other planets? Google Cloud is working with NASA’s Frontier Development Lab to find outEnhancing Spinnaker’s Kubernetes support to ease app deployments5 cloud migration tasks you might be worried about (but don’t need to be)Introducing Stackdriver as a data source for GrafanaA process for implementing industrial predictive maintenance: Part IIUnderstanding native container routing with Alias IPsFirewall rules logging: a closer look at our new network compliance and security toolServerless from the ground up: Building a simple microservice with Cloud Functions (Part 1)Best practices for building Kubernetes Operators and stateful appsAI in Motion: designing a simple system to see, understand, and react in the real world (Part III)Protecting Cloud Storage with WORM, key management and more updatesIntroducing Private DNS Zones: resolve to keep internal networks concealedIntroducing the Cloud KMS plugin for HashiCorp VaultServerless from the ground up: Adding a user interface with Google Sheets (Part 2)Scripting with gcloud: a beginner’s guide to automating GCP tasksHow 20th Century Fox uses ML to predict a movie audienceGoogle named a leader in the latest Forrester Research API Management Solutions WaveCan cloud instances perform better than bare metal? Latest STAC-M3 benchmarks say yesModern data warehousing with BigQuery: a Q&A with Engineering Director Jordan TiganiAvailable first on Google Cloud: Intel Optane DC Persistent MemoryNode.js 10 available for App Engine, in lockstep with Long Term SupportIntegrating Google Cloud Build with JFrog ArtifactoryHow the public sector is working with Google Cloud to improve the health, safety, and wellbeing of citizensRun Apache Spark and Apache Hadoop workloads with the flexibility and predictability of Cloud DataprocGetting to know the Google Cloud Healthcare API: Part 1How Streak built a graph database on Cloud Spanner to wrangle billions of emailsNovemberBringing enterprise network security controls to your Kubernetes clusters on GKEExploring container security: running and connecting to HashiCorp Vault on KubernetesServerless from the ground up: Connecting Cloud Functions with a database (Part 3)Cutting costs with Google Kubernetes Engine: using the cluster autoscaler and Preemptible VMsSteering the right course for AIHDFS vs. Cloud Storage: Pros, cons and migration tipsCustomer Managed Encryption Keys (CMEK) for Dataproc is now generally availableContainerd available for beta testing in Google Kubernetes EngineAnnouncing Cloud Scheduler: a modern, managed cron service for automated batch jobsLast Month Today: GCP in OctoberDiscover Card: How we designed an experiment to evaluate conversational experience platformsDeep dive into managed TLS certs for HTTP(S) Load BalancersIntroducing AI Hub and Kubeflow Pipelines: Making AI simpler, faster, and more useful for businessesChoosing your cloud app migration orderPicture what the cloud can do: How the New York Times is using Google Cloud to find untold stories in millions of archived photosGoogle Cloud first to offer NVIDIA Tesla T4 GPUsHelp for slow Hadoop/Spark jobs on Google Cloud: 10 questions to ask about your Hadoop and Spark cluster performanceIntroducing Transfer Appliance in the EU for cloud data migrationLet’s talk AI: Customers meet in San Francisco to show how AI is helping their businessesGetting started with Kubeflow PipelinesSubatomic particles and big data: Google joins CERN openlabNew report examines the economic value of Cloud Dataproc’s managed Spark and Hadoop solutionTaking charge of your data: Using Cloud DLP to find and protect PIIGoogle Cloud Certification: Take the plungeCloud Functions pro tips: Using retries to build reliable serverless systemsExtending the SQL capabilities of your Cloud Dataproc cluster with the Presto optional componentUsing upstream Apache Airflow Hooks and Operators in Cloud ComposerAssociate Cloud Engineer certification now available in GermanNo tricks, just treats: Globally scaling the Halloween multiplayer Doodle with Open Match on Google CloudGoogle Cloud IoT and Microchip bring simple and secure cloud connectivity to 8-bit MCU with the AVR-IoT WG kitData for development: Supporting communities through data analyticsFinding data insights faster with BigQuery and GCP Marketplace solutionsKhan Bank: Using APIs to make banking faster and easier in MongoliaUnlocking what’s possible with medical imaging data in the cloudHTTP vs. MQTT: A tale of two IoT protocolsKubernetes users, get ready for the next chapter in microservices managementCloud Identity now provides access to traditional apps with secure LDAPHow modern is your data warehouse? Take our new maturity assessment to find outGrowing our presence in Asia Pacific: New GCP regions in Hong Kong and JakartaA solution for implementing industrial predictive maintenance: Part III8 common reasons why enterprises migrate to the cloudWelcoming more than 100 new partners to our SaaS programPega workflow automation: Simplifying Google’s network, and ready for your GCP workloadsGetting to know the Google Cloud Healthcare API: part 2Cloud Functions pro tips: Building idempotent functionsDecemberLast month today: GCP in NovemberStackdriver tips and tricks: Understanding metrics and building chartsThe Google Cloud Adoption Framework: Helping you move to the cloud with confidenceHow to connect Cloudera’s CDH to Cloud StorageHire by Google helps you match prior candidates with new jobsIntroducing Cloud IoT Core commands: increased flexibility to control your fleet of embedded devicesCloud Security Command Center is now in beta and ready to useKubernetes and GKE for developers: a year of Cloud ConsoleClearDATA: Running Forseti the serverless wayCloud covered: What was new in Google Cloud for NovemberA little light reading: What to read to stay updated on cloud technologyDeep reinforcement learning on GCP: using hyperparameter tuning and Cloud ML Engine to best OpenAI Gym gamesExploring container security: This year, it’s all about security. Again.Exploring container security: How containers enable passive patching and a better model for supply chain securityKnative: bringing serverless to Kubernetes everywhereExpanding our partnership with Palo Alto Networks to simplify cloud security and accelerate cloud adoptionReaders’ choice: Top Google Cloud Platform stories of 2018Accelerate your app delivery with Kubernetes and Istio on GKENurture what you create: How Google Cloud supports Kubernetes and the cloud-native ecosystemAnnouncing Cloud DNS forwarding: Unifying hybrid cloud namingNow you can train TensorFlow machine learning models faster and at lower cost on Cloud TPU PodsMLPerf benchmark establishes that Google Cloud offers the most accessible scale for machine learning trainingMark your calendar: Google Cloud Next ’19Google Cloud Platform now IRAP-certified by Australian Cyber Security CenterTaking a practical approach to BigQuery cost monitoringEnterprise IT can move up or out (or both)Introducing Access Approval and new Access Transparency services: Gain more meaningful oversight of your cloud providerCloud Identity for Customers and Partners (CICP) is now in beta and ready to useNew for Persistent Disk and Compute Engine: Control the storage location of your disk snapshotsPython 3.7 for App Engine is now generally availableCloud Spanner adds enhanced query introspection, new regions, and new multi-region configurationsAnnouncing the beta release of SparkR job types in Cloud DataprocExploring container security: Let Google do the patching with new managed base imagesHow the energy industry is using the cloudAI in depth: profiling the model training process for TensorFlow on Cloud ML EngineCloud Storage requests create data art and usage insightsCloud SQL now supports private connections and App Engine second generation runtimesGetting to know the Google Cloud Healthcare API: part 3Where poetry meets tech: Building a visual storytelling experience with the Google Cloud Speech-to-Text APINew Qwiklabs Quest available: IoT on Google CloudCloud Functions pro tips: Using retries to build reliable serverless systems (Part 3)Using data and ML to better track wildfire and assess its threat levelsWe’ll be back with more great content in 2019. But until then, happy holidays, and we’ll see you in the new year.
Quelle: Google Cloud Platform