Cook up your own ML recipes with AI Platform
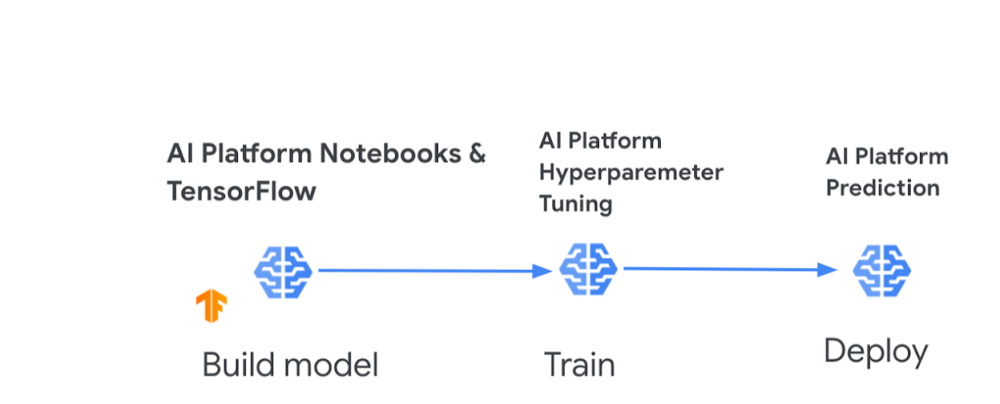
For anyone with a sweet tooth for confections and machine learning, I have some good news. You might remember recently my colleagues, Sara Robinson and Dale Markowitz, collaborated to create some delicious new baked inventions, including the Breakie (a fusion between cake, cookies, and bread). All of this was done through a baking ML model that they built with AutoML Tables, a no-code way to create machine learning models on tabular data.Well, it wasn’t long before legendary confectionery manufacturer Mars Wrigley approached Sara and Cloud AI for a Maltesers + AI kitchen collaboration. Sara trained a new ML model to generate recipes for cookies, cakes, scones, traybakes, and any “hy-bread” of these. After hours of model training and baking experiments, Sara combined Maltesers with her model’s AI-optimized cake and cookie recipes to create a brand new dessert, which even includes the classic British ingredient, Marmite. To break it down, Sara used a few tools to build and customize her model:AI Platform Notebooks (Jupyter lab environment for feature engineering and model development) and TensorFlow AI Platform Hyperparameter Tuning(model training)AI Platform Prediction (model deployment)You can try out Sara’s AI-powered Mars recipe yourself, but if you have an appetite to build your own ML model for other creations like pizzas, pies, milkshakes, or stir-frys, let’s boil down the objectives and steps to get you started:Objective: Create a model that takes a type of dish as input, and produces the amounts of the different ingredients needed to create it.Steps:Collect the data. You’ll want to collect a sizable dataset around the dish recipes you’re interested in (various types of pizzas, baked goods, or noodles for example). You’ll want data on the amount of each ingredient that goes into the dish. So if you’re focused on pizzas, you need data on the amounts of dough, cheese, and toppings that make up each pizza type. Prepare the data. Whittle down each of those recipes to core ingredients that span the dishes. This might be a bit arbitrary but think about which ingredients affect the fundamental makeup of all dishes like texture, flavor, or consistency. In the pizza example, I’d narrow it down to only dough ingredients, cheese type, sauce, and common toppings. Preprocess the data. Make sure all ingredient amounts are in the same measurement unit (e.g., ounces or grams). You may also need to scale the model inputs so that all ingredient amounts fall within a standard range. You can use data augmentation to create new training examples. If you’re using AutoML you can skip this step, as it handles many data preparation tasks for you, but keep in mind best practicesfor creating training data. Build your model. AI Platform lets you develop, train, and deploy your model using notebooks, a built-in Data Labeling Service, and the ability to store datasets in Cloud Storage or BigQuery. You can also use AutoML Tables and import data directly from CSV files, Google Sheets, or a BigQuery database. Train your model. You can use AI Platform Hyperparameter Tuning, a service for running multiple training job trials to optimize a model’s hyperparameters. Additionally, AutoML Tables provides automated feature engineering. With either tool, you can determine which ingredients are important predictors of each dish type, such as basil being an important predictor of a Margherita pizza (this can be more easily done using AutoML). Deploy your model and predict. Once you have tuned your hyperparameters and trained your model, you can use AI Platform Prediction to create custom recipes (amounts of ingredients to create a dish or combo-dish). With both AI Platform and AutoML you can also discover feature importance scores (how heavily weighted ingredients are for a dish). AI-powered recipes delivered! Now before you run off to grab your apron, let me share some sweet resources to help you get started.AI resources to give you a tasteAI Platform QuickstartThis tutorial shows how to train a neural network on AI Platform using the Keras sequential API and how to serve predictions from that model. You can also run the tutorial as a notebook in Colab. You’ll learn how to:Train a model on AI Platform using prewritten Keras codeDeploy the trained model to AI PlatformServe online predictions from the deployed modelPlus learn how to dig into the training code used for this model and ensure it’s compatible with AI Platform. Even though the dataset is around US Census income, you can use the tutorial as a framework for understanding how to train, deploy, and serve models on AI Platform for cooking-inspired (or other) datasets of your choosing. Build your first AI Platform NotebookIn this tutorial, Sara walks you through tools in AI Platform Notebooks for exploring your data and prototyping ML models. You’ll learn how to: Create and customize an AI Platform Notebooks instanceTrack your notebook code with git, directly integrated into AI Platform NotebooksUse the What-If Tool within your notebookAutoML TablesI’d be remiss if I didn’t emphasize that you can also create custom ML models without code. I mentioned that when Sara and Dale teamed up to create their Breakie recipe, they used AutoML Tables, which relieves much of the heavy burden by automating feature engineering so you can easily build and deploy state-of-the-art machine learning models on structured data. The codeless interface guides you through the full end-to-end ML workflow, making it easy for anyone to build models and reliably incorporate them into broader applications. There are a ton of quickstarts, samples, and videos to help you get started on AutoML Tables. Use them to learn how to:Create a dataset and modelImport data into a datasetDeploy a modelEvaluate your modelUse AutoML Tables from a Jupyter notebookAI Adventures video playlistCheck out coverage from Yufeng Guo and Priyanka Vergadia on AI Platform. In this featured video, Yufeng covers how you can use AI Platform built-in algorithms to train and deploy machine learning models without writing any training code. Plus check out other videos in the playlist to learn about:Training models with custom containers on AI PlatformAI Platform Pipelines for improving the reliability of your ML workflowsUsing AI Prediction service to get explanations of your models and better understand their outputsMaking the most of the AI Data Labeling service on AI PlatformIf you’ve made it to this point, you’re probably getting hungry and eager to put this in action. You can explore more AI on Google Cloud, and share your recipes with Sara, Dale, and me online. We’ve tried this with baking, but we’d love to hear if you have success with models for other types of recipes! – StephanieRelated ArticleHow sweet it is: Using Cloud AI to whip up new treats with Mars MaltesersMars uses Google Cloud AI to invent a tasty new cake that includes maltesers and marmite!Read Article
Quelle: Google Cloud Platform