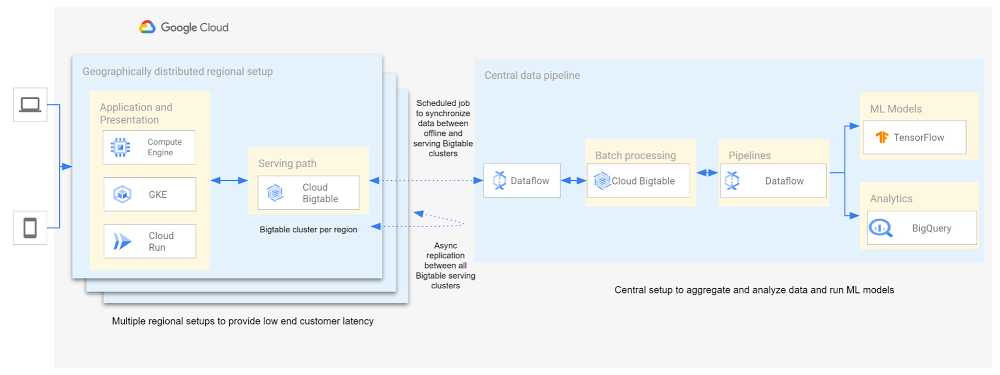
Customer expectations have shifted as a result of evolving needs. Across industries, customers expect that you treat them as individuals, and demonstrate how well you understand and serve their unique needs. This concept—personalization—is the idea that you’re delivering a tailored experience to each customer corresponding to their needs and preferences; you’re setting up a process to create individualized interactions that improves the customer’s experience. According to Salesforce, 84% of consumers say being treated like a person, not a number, is very important to winning their business. Entire industries are undergoing digital transformation to better serve their customers through personalized experiences. For example, retailers are improving engagement and conversion with personalized content, offers, and product recommendations. Advertising technology organizations are increasing the relevance and effectiveness of their ads using customer insights like their specific interests, purchasing intent, and buying behavior. Digital music services are helping their customers discover and enjoy new music, playlists, and podcasts based on their listening behavior and interests. As customers want more and more personalization, modern technology is making it possible for many more businesses to achieve this. In this post, we’ll look at some common challenges to implementing personalization capabilities and how to solve them with transformative database technologies like Google Cloud’s Bigtable. Bigtable powers core Google services such as Google Maps that supports more than a billion users, and its petabyte scale, high availability, high throughput, and price-performance advantages help you deliver personalization at scale. Challenges with personalization Data is at the heart of personalization. To deliver personalization at scale, an application needs to store, manage, and access large volumes of data (a combination of customer-specific data and anonymized aggregate data across customers) to develop a deep understanding of the behavior, needs, and preferences of each customer. Your database needs to very quickly write large volumes of data concurrently for all active customers. You need to continuously capture data on customer behavior because each step potentially informs the next, e.g., adding an item to a shopping cart can be used to trigger new recommendations for related or complementary products. Much of this data needed for personalization is semi-structured and sparse, and therefore requires a database with a flexible data model. Personalization at scale requires large volumes of data to be read in near real-time so that it can be in the critical serving path to deliver a seamless user experience, often with a total application latency of less than 100ms. This means your requests to the database need to return results with latencies of single-digit milliseconds. You need to ensure that application latencies do not degrade as you onboard more customers. Data needs to be organized efficiently and integrated with other tools so that you can run deep analytical queries and use machine learning (ML) models to develop personalized recommendations, and store the aggregates in your operational database for serving your customers. You also need the ability to run large batch reads for analytics without affecting the serving performance of your application. In addition, you need to ensure that your database costs do not explode with the popularity of your application. Your database needs to consistently deliver low total cost of ownership (TCO), and high price-performance as your data volumes and throughput needs grow. Your database needs to scale seamlessly and linearly to deliver consistent, predictable performance to all users around the world. Additionally, your database needs to be easy to manage, so that you can focus on your application instead of managing the complexity of your database.Why a NoSQL database is the right fit for personalization Every database reflects a set of engineering tradeoffs. When relational databases were designed 40 years ago, storage, compute, and memory were thousands of times more expensive than they are today. Databases were deployed on a single server to a relatively small number of concurrent users, whose access to the systems tended to be during normal business hours when users had network access. Relational databases were designed with these resources, costs, and use in mind. They work very hard to be storage and memory efficient, and assume a single server for deployments. As the costs of storage, memory, and compute decreased, and as data and workloads grew to exceed the capacity of commodity hardware, engineers began to reconsider these tradeoffs with different goals in mind. New types of databases later emerged that assumed distributed architectures so they could be easier to scale, especially with cloud infrastructure. With this approach the tradeoff in turn was to forego the sophistication of SQL and much of the data integrity and transactional capabilities developed in relational systems. These systems are commonly called NoSQL databases.Traditional relational databases assume a fixed schema that will change infrequently over time. While this predictability of data structure allows for many optimizations, it also makes it difficult and cumbersome to add new and varying data elements in your application. NoSQL databases, such as key value stores and document databases, relax the rigidity of the schema and allow for data structures to evolve much more easily over time. Flexible data models speed the pace of innovation in your application, and increase your ability to iterate on your ML models, which is essential for personalization. In addition, the scalability of systems like Cloud Bigtable allow you to deliver personalization to millions of concurrent users while you continue to evolve how you personalize experiences for your customers.How Cloud Bigtable enables personalization at scaleCloud Bigtable supports personalization at scale with its ability to handle millions of requests per second, cost-effectively store petabytes of data1, and deliver consistent single-digit millisecond latencies for reads and writes. Bigtable delivers a unique mix of high performance and low operating cost to reduce your TCO. We’ve heard from Spotify, Segment, and Algolia about how they’vebuilt personalized experiences for their customers with Bigtable. Check out this presentation to hear Peter Sobot of Spotify describe how they use Bigtable for personalization. Let’s imagine a scenario where your application takes off like a rocketship, and grows to 250 million users. Let’s assume a peak 1.75 million concurrent users of your application2, with each user sending two requests per minute to your database. This will drive 3.5 million requests per minute to your database, or approximately 58.3K requests per second. Pricing for Bigtable to run this workload will start at under $400 per day3.Bigtable scales throughput linearly with additional nodes. With separation of compute and storage, Bigtable automatically configures throughput by adjusting the association of nodes and data to provide consistent performance. When a node is experiencing heavy load, Bigtable automatically moves some of the traffic to a node with lower load to improve the overall performance. Bigtable also supports cross-region replication, with local writes in each region. This allows you to manage your data near your customers’ geographic locations, reducing network latency and bringing predictable, low-latency reads and writes to your customers in different regions around the world. Bigtable is a NoSQL database developed and operated by Google Cloud. Bigtable provides a column family data model that allows you to flexibly store varying data elements for customers associated with their behavior and preferences, store a very large number of such data elements across your customers, and quickly iterate on your application. Bigtable supports trillions of rows with millions of columns. Each row in Bigtable supports up to 256 MB of data, so that you can easily store all personalized data for a customer in a single row. Bigtable tables are sparse, and there is no storage penalty for a column that is not used in a row; you only pay for the columns that store values.BigQuery ML allows you to create and run ML models directly in BigQuery to develop personalization recommendations that you can bring back to Bigtable. You can easily pipe Bigtable data into BigQuery to run deep analytical queries and develop recommendations. These aggregates, like computed recommendations, are brought back to Bigtable so your application can serve those recommendations to users with low latency and massive scale. Bigtable integrates with the Apache Beam ecosystem and Dataflow to make it easier for you to process and analyze your data. With application profiles and replication in Bigtable, you can isolate your workloads so that batch reads do not slow down your serving workload that has a mix of reads and writes. This enables your application to perform near real-time reads at scale to develop and train machine learning models in TensorFlow for personalization. Bigtable gives you the right operational data platform to develop personalization recommendations offline or in real-time, and serve them to your customers.Click to enlargeHere’s a look at conceptual schema examples for personalization in ecommerce:Click to enlargeAnd here’s a quick overview of what personalization use cases require, and how Bigtable addresses them.Click to enlargeBigtable is fully managed to free you from the complexity of managing your database, so that you can focus on delivering a deeply personalized experience to your customers. Learn more about Bigtable.1. Storage pricing (HDD) starts at $0.026 per GB/mo (us-central1)2. Assumes application is used 24 hours a day, average user session is 5 minutes (Android app average), and daily peak is 2x the average. (250 million / (24 hours / 5 minutes) *2 = 1,736,111 peak concurrent users (us-central1 region)3. Cloud Bigtable pricing for us-central1 region. Assumes 25 TB SSD storage (100 KB per user, for 250 million users) per month, 10 compute nodes per month (with no replication), includes data backup. Bigtable pricing details.Related ArticleA primer on Cloud Bigtable cost optimizationCheck out how to understand resources that contribute to costs and how to think about cost optimization for the Cloud Bigtable database.Read Article
Quelle: Google Cloud Platform