Empowering operators through generative AI technologies with Azure for Operators
OpenAI’s offerings—ChatGPT, Codex, Sora, and DALL-E—have caught the public’s imagination and opened doors to many opportunities for infusing AI into networks, systems, services, and applications. These cutting-edge AI technologies are now deeply integrated with Microsoft products including Bing, Windows, Office, and Microsoft Teams. Within Azure for Operators, we are taking advantage of the significant investments Microsoft has made and its expertise in programming foundation models by developing technical solutions that will give our customers a competitive advantage. Our product portfolio, which includes Azure Operator Nexus, Azure Operator Insights, and Azure private multi-access edge compute is being augmented with generative AI technologies, empowering operators to efficiently solve real-world problems. But before we get into the solutions, let’s begin with a brief background on generative AI and recent AI advancements.
Azure for Operators
Get to know the Microsoft portfolio for operators
Discover solutions
Foundation models and the next era of ai
Read the blog
Background on generative AI
OpenAI’s generative models have drawn significant attention for their exceptional performance in generating text, image, video, and code. Among these generative models, a notable breakthrough is generative pre-trained transformer (GPT), a large language model with hundreds of billions of parameters. GPT is pre-trained on a vast corpus of data from the open internet, allowing it to comprehend natural language and generate human-like responses to input prompts from users. ChatGPT, Codex (the model behind GitHub Copilot), Sora, and DALL-E are all derived from the pre-trained GPT (or foundation model). Codex is additionally trained on code from 54 million GitHub repositories—a process known as “fine-tuning.” To enable the customization of GPT for new language tasks, OpenAI offers a paid API service that allows developers to fine-tune GPT on domain-specific data through a command-line interface and query the fine-tuned model without accessing the underlying model. Through a partnership with OpenAI, Microsoft benefits from exclusive access to the underlying model and parameters of GPT, placing us in a strong position to develop inference and a fine-tuning infrastructure.
Microsoft and openai exclusively license gpt-3
Read the blog
We have divided our AI and machine learning investments into four categories:
Reactive management: Automated incident management.
Proactive management: Automated anomaly detection and fault localization.
AI and machine learning infused into Azure for Operators products.
AI and machine learning engineering platform across Azure for Operators.
I want to talk a little about our investments that fall under the first two categories. These systems showcase the potential of foundation models as they are incorporated into our products, and they can significantly impact the way mobile operator networks are developed, operated, and managed.
Reactive management: Data intelligence copilot for operators
Operators gather vast amounts of data, including node-level, gNodeB-level, user-level, and flow-level data, for purposes like network monitoring, performance tracking, capacity management, and debugging. In commercial operator networks, the number of such counters and metrics that are regularly computed often exceeds several thousands, accounting for tens of Gbps of data transfer. Retrieving relevant metrics and visualizing them is crucial for network operations. However, the complexity of modern wireless systems and the vast number of counters involved make this task challenging, necessitating expert knowledge to perform this essential operation.
The process today involves specialists with expert knowledge creating dashboards for a limited number of metrics, which the operators browse through to obtain relevant information. However, if operators require customized data, such as visualizing throughput for a specific user rather than aggregate throughput or if they need access to a different set of metrics for complex debugging purposes, a loop through the specialists is required. The specialists need to identify the relevant variables, write code in database query language to combine them in an appropriate manner, and then create and share a dashboard.
Can operators interact with their data by asking simple questions in natural language, without having to remember any of the complex counter names or how to combine them in a database query language?
We believe that such a system has the potential to significantly transform the status quo. It would provide a more natural way to interact with operator data without heavy reliance on specialists. This would reduce the time to mitigate network issues, and it would provide more value from the operator data by reducing the barrier to customized insights.
The development of foundation models like GPT-4 has significantly advanced the capabilities of natural language interfaces for data interaction, demonstrating remarkable performance on standard text-to-SQL datasets. Despite these achievements, challenges persist in specialized and niche domains such as operator data. These challenges include the handling of specialized information that is often not publicly available, the overwhelming volume of data counters and metrics that exceeds the prompt size limits of these models, and the need for numerical accuracy that is crucial for decision-making in network operations but which the foundation models are not adept at.
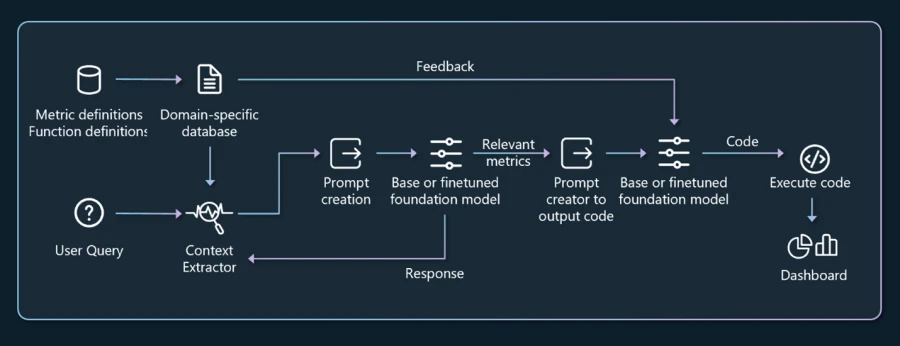
System architecture for data intelligence copilot for operators.
We have developed data intelligence copilot for operators, a natural language interface for retrieval and analytics tasks on operator data, leveraging foundation models. It addresses the challenges posed by operator data through a combination of a domain-specific database with comprehensive metrics descriptions, a semantic search for filtering relevant metrics within the models’ prompt size limits, few-shot learning for enhancing numerical accuracy in code generation, and expert feedback mechanisms that allow for continuous improvement of the database through contributions from domain experts.1 This copilot is being integrated into our Azure Operator Insights product as a knowledge assistant.
Reactive management: Intent-based network management
Generally, operator networks are very complex with management operations, heavily relying on highly skilled professionals and sophisticated management tools to create, update, and deploy network configurations. Configuration files can be several tens of thousands of lines long. This process is not only labor-intensive but also error-prone, underscoring a need for automation to alleviate the management burden for network operators.
We have been working on a promising paradigm called intent-based networking (IBN), a solution to simplify network management for operators. It allows network operators to specify the desired behavior or “intent” of their network in natural language. They can say, “Allow ICMP traffic in my network,” and then the solution automatically translates the intent into updated network configurations. IBN can present these updated configurations to network administrators for review prior to their deployment, ensuring network safety while keeping minimal human intervention.
Intent-based networking agent powered by GPT simplifies network management.
Although the concept of IBN has been around for some time, its implementation has been hindered by the complexities of natural language understanding and the intricate task of configuration generation. Motivated by recent advances in generative AI (for example GPT), we revisited this problem and developed a tool named “IBN agent” based on GPT. Our IBN agent takes as input the running network configuration and the user’s natural language intent. It then queries GPT to update the network configuration according to the user intent. Utilizing existing configuration syntax checks and network verification tools, the IBN agent also flags errors in the GPT-generated configurations. Moreover, users can intervene at any point and provide feedback on any undesired behavior. Based on these identified errors or user feedback, the IBN agent iteratively refines the configuration with GPT until all automated and human checks are passed. We believe that IBN holds substantial potential to simplify network configuration in the future.
Proactive maintenance: Next generation communications copilot for operators
Practitioners, engineers, researchers, and students can find themselves grappling with a multitude of acronyms and intricate terminology with information spread across many documents, which makes working with and developing standards-compliant systems an onerous and time-consuming task. For example, an engineering team working on implementing a registration request procedure as a part of building 5G virtual core would need to identify all the relevant technical specifications from among thousands of documents and understand the call flow and message formats as described in those specifications.
The current method of acquiring this information involves sifting through numerous webpages and technical specification documents. While this approach provides extensive comprehension of a topic from various sources, it can also be time-intensive and tedious to identify, gather, and synthesize information from multiple relevant sources.
Foundation models represent a significant advancement in providing synthesized, readily comprehensible answers to user queries related to wireless communication specifications. However, despite the usefulness of state-of-the-art large language models, they also produce irrelevant or inaccurate responses to many queries related to niche and specialized domains.
We have developed a conversational AI tool for information synthesis of wireless communication specifications.
Like ChatGPT, the nextgen communications (NGC) copilot offers a question-and-answer interface, but with an enhanced ability to provide more accurate and relevant answers on topics pertaining to wireless communication technical specifications. NGC copilot builds on foundation models, prompt engineering, and retrieval augmented generation approaches; it features a domain-specific database, tailored word embeddings, and a user feedback mechanism. For more accurate responses, it integrates into its database technical specifications and standards that are often overlooked by traditional models due to their niche nature. The system uses a specialized word-embedding model to better understand telecom jargon, improving its query response relevance. Experts can also provide feedback, which helps refine the database and improve answer quality. We have been piloting NGC within our engineering teams and its performance has been excellent.
Proactive management: Network configuration anomaly detection
One of the most common causes of network disruptions today is network configuration errors. Configuration governs the protocols and policies that regulate and control network access, performance, security, billing, and more. Misconfigurations, when they occur, can lead to a frustrating user experience with slow performance, lack of connectivity, or even sweeping service outages. Operators who experience such outages often suffer from loss of reputation and revenue.
Despite the importance of correct network configuration, configuration management today remains a challenge for operators. Manual peer review of configuration changes can have limited effectiveness. Device configurations are often low-level, complex, and long—making them notoriously challenging to audit manually and at scale. On the other hand, automation is also not a panacea; it’s prone to errors, bugs, and mistakes.
The configuration anomaly detection analysis pipeline.
Many configuration errors are obvious in hindsight and could be detected by sufficiently intelligent learning models. For this reason, we have invested in developing AI-driven anomaly-detection tools that can proactively identify and block erroneous configuration changes before they are applied to the network—before they can impact real users. Machine learning is adept at identifying common configuration usage patterns and anti-patterns. It can effectively sift through changes to ignore those that are intentional and alert operators about those that are likely unintentional or erroneous.
Given a collection of similar configuration files (such as JSON, XML, or YAML), our system synthesizes a common template that captures the similarities between these configurations, leaving placeholders for differing values. Using the synthesized template, our system employs a state-of-the-art, unsupervised anomaly-detection technique, known as the isolation forest, to pinpoint likely errors in configurations. These potential anomalies are reported with an anomaly-likelihood score for review. In this way, we aim to help operators with safe and reliable management of their 5G networks by leveraging automated validation of configurations. For real-world scenarios and additional technical details, please read our recent paper.2
Microsoft responsible AI
empowering responsible ai practices
Learn more
We realize that AI and machine learning-based solutions may involve ethical concerns regarding the underlying models, their training data, and associated biases. To address these concerns, the office of responsible AI shepherds the AI projects at Microsoft on risk assessment and mitigation. We work hard to understand the aspects that require improvement regarding bias and discrimination, and we strive to receive broad approval on compliance. We pass on all guidelines to the engineers to ensure responsible usage without slowing progress.
Explore the Microsoft portfolio of products
My hope is that these examples show that foundation models significantly enhance the Azure for Operators portfolio of products. There is a lot more to say, and there are many additional examples of systems we have developed, but I will leave that for another time.
1 Microsoft, Adapting Foundation Models for Operator Data Analytics, Manikata Kotaru, HotNets 2023.
2 Microsoft, Diffy: Data-Driven Bug Finding for Configurations, Siva Kesava Reddy Kakarla, Francis Y. Yan, and Ryan Beckett, April 2024.
The post Empowering operators through generative AI technologies with Azure for Operators appeared first on Azure Blog.
Quelle: Azure



