In this article
AI is reshaping how enterprises operate, make decisions, and innovate at scaleFrontier innovation for ERP systemsYour agentic intelligencePutting enterprise AI into productionAdvancing a new era of AI collaborationPowering AI with a unified data foundationMicrosoft and SAP expand partnership to deliver trusted sovereign cloud solutionsExpanding platform availability and ecosystem innovationCloud Acceleration Factory expansion: Driving AI innovation for SAPExpanding the Global RISE with SAP Acceleration Program on Microsoft AzureCustomer innovation in actionA global partner ecosystem driving scalePowering the future of SAP with Microsoft CloudDiscover what SAP and Microsoft Cloud have to offer
AI is reshaping how enterprises operate, make decisions, and innovate at scale
Together, Microsoft and SAP are helping enterprises transform operations, decision-making, and innovation at scale on Azure.
At SAP Sapphire 2026, Microsoft and SAP continue to build on a deep, decades-long partnership—one that is increasingly centered on a shared vision for how enterprises innovate in the age of AI. We’re excited to unveil how Microsoft’s Frontier Transformation helps customers realize SAP’s autonomous enterprise journey.
See how SAP on Azure drives business value for these customers
Frontier innovation for ERP systems
Microsoft Azure is the foundation of Frontier Transformation. To succeed, it must be built on a global, trusted, AI-first commercial cloud. Modern AI at scale requires a different kind of platform—one designed for agents, intelligence platforms, and continuous learning with AI embedded where people already work—augmenting decisions and actions in real time. That is how AI moves from experimentation to everyday impact.
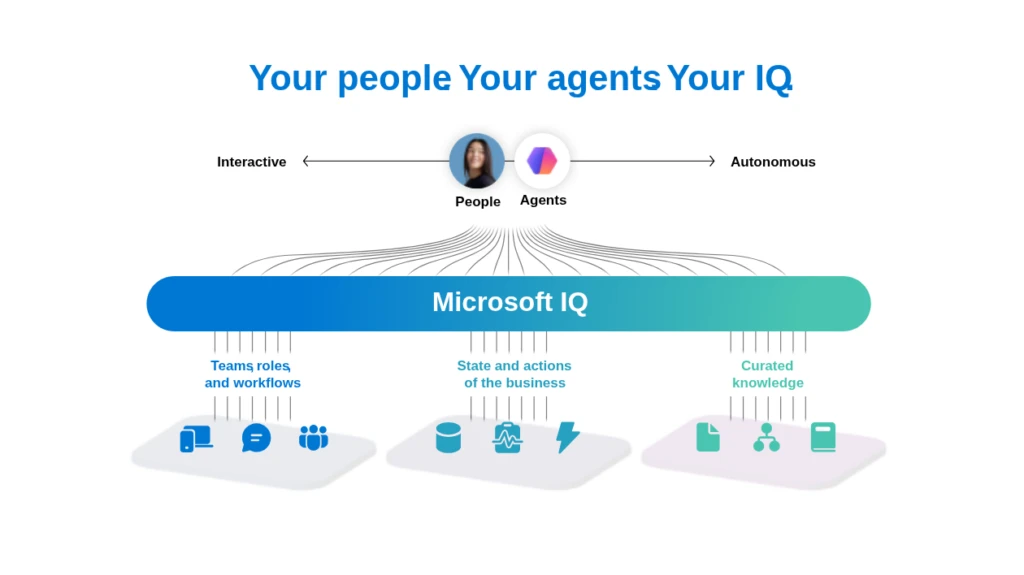
What differentiates these experiences is intelligence and context. Agents that understand enterprise data, business processes, and organizational semantics improving relevance, accuracy, and decision quality over time. We call this Microsoft IQ.
Your agentic intelligence
Microsoft IQ is a shared intelligence layer built to power enterprise AI. It brings together three dimensions of intelligence: how people work, how the business operates, and how knowledge is unlocked and activated. From collaboration and workflows, to business data and systems of record, to policies and institutional knowledge—these signals are connected through a common platform, enabling AI to operate with full context across the organization.
This creates a new model for the enterprise:
Employees are supported by AI that understands their work in context.
Business operations are powered by real-time, connected data.
Knowledge is continuously surfaced, reasoned over, and applied through intelligent agents.
The result is an enterprise that moves faster, adapts more quickly, and drives better decisions with AI.
This is where the joint innovation between Microsoft and SAP becomes uniquely powerful. By combining SAP’s deep business process expertise with Microsoft’s intelligence layer, customers can extend this Frontier model into core business operations. SAP’s enterprise applications and data—spanning across SAP Business AI Platform and Joule—connect smoothly with Microsoft Teams, Microsoft Fabric, Microsoft Copilot, and a new generation of AI agents.
Putting enterprise AI into production
A central theme at SAP Sapphire 2026 is making AI real—moving from experimentation to production-ready, business-driven outcomes.
Save the bAIkery AI experience
Microsoft’s AI Immersion Experience showcases this shift in action. Through interactive scenarios like “Save the bAIkery,” attendees step into a dynamic business environment where every decision matters. Powered by Azure OpenAI, SAP Joule, SAP Cloud ERP, Microsoft Copilot Studio, and Power BI. This experience demonstrates how insights are generated to drive business outcomes across SAP systems—bringing together generative AI, analytics, and business processes in a seamless flow.
What makes this experience compelling is not just the technology—it’s the shift it represents. AI is no longer a layer on top of enterprise systems. It is becoming embedded into the core of how businesses operate, enabling faster decisions, greater agility, and entirely new ways of working.
Interactive: Explore how Microsoft and SAP AI capabilities can work together to connect business context, productivity tools and enterprise workflows.
Together, this enables end-to-end AI transformation:
Business data flows into a unified data foundation.
Intelligence is applied through SAP Joule and Copilot and agent-driven experiences.
Actions are executed across systems through tightly integrated workflows, in a governed, secure, and observable way.
The result is not just better integration—but a fundamentally new way of operating. Creating intelligent, interconnected systems where data, AI, and business processes continuously learn, adapt, and improve. This is the path to becoming a Frontier enterprise—where AI delivers measurable impact across the business, not as isolated gains, but as a continuous engine of innovation.
Advancing a new era of AI collaboration
One of the most exciting areas of innovation between Microsoft and SAP is the continued evolution of AI innovation across systems.
Over the past year, integration between SAP Joule and Copilot has taken important steps forward, enabling users to access business data and take action across SAP and Microsoft 365 environments.
At Sapphire, that vision continues to evolve and we are excited to announce agent-to-agent (A2A) integration between Microsoft 365 Copilot and Joule—delivering connected AI experiences using agent‑to‑agent capabilities, enabling Joule to work seamlessly across the Microsoft 365 productivity suite. This announcement opens up a world in which AI systems don’t just assist users—they begin to coordinate with each other across workflows.
Business collaboration happens in Microsoft 365 (for example, Teams chats about supply chain, finance, sales, or external emails with customers and suppliers) A2A enables Joule and Copilot to execute agentic flows with the collective intelligence of Microsoft Work IQ and SAP Knowledge Graph to truly deliver contextually aware enterprise AI.
This emerging model allows SAP and Microsoft AI capabilities to work together more seamlessly, enabling scenarios where business tasks can be orchestrated end-to-end across applications. Internally, this direction focuses on enabling more secure, governed, and scalable workflows across SAP landscapes while using the broader Microsoft ecosystem of applications and partner solutions.
For example, customers can prepare for performance reviews by starting directly in Microsoft 365 Copilot within Word, leveraging SAP-delivered Joule skills for systems like SAP S/4HANA or SAP SuccessFactors, and seamlessly scheduling a one-on-one meeting with their manager—all within the same interface.
It’s a meaningful step toward a future where AI becomes an active participant in how work gets done.
Powering AI with a unified data foundation
AI is only as powerful as the data behind it—and for many organizations, that data is still fragmented across systems, limiting its full potential.
At Ignite 2025, Microsoft and SAP took a major step forward in addressing this challenge. With the announcement of SAP Business Data Cloud Connect for Microsoft Fabric, we committed to a simplified method of accessing semantically rich data products from SAP through bi-directional, zero-copy delta sharing with Microsoft Fabric. Coming in the latter half of 2026, delta sharing will enable enterprises to gain instant access to trusted, business-ready insights for advanced analytics—bringing together SAP and non-SAP data into a single, unified foundation for AI.
Through bi-directional, zero-copy sharing between the SAP Business Data Cloud solution and Microsoft Fabric, customers can realize a fundamentally different data experience: one where data is no longer siloed, insights are no longer delayed, and AI is no longer constrained—enabling organizations to move faster, act with confidence, and turn intelligence into impact across every part of the business.
To lay the foundation for this delta-sharing Microsoft and SAP already deployed SAP BDC in eight Azure Datacenters. We will also add Japan by the end of May and Germany in June. With three additional deployments planned by the end of 2026, that will bring a total of 13 Azure regions available to support SAP BDC for customer analytics.
Microsoft and SAP expand partnership to deliver trusted sovereign cloud solutions
Sovereignty has become a decisive factor for organizations operating in regulated industries and the public sector—where data control, compliance, and operational assurance are critical. SAP and Microsoft are expanding their partnership to help customers meet growing sovereign cloud requirements as they modernize SAP landscapes.
Building on sovereign offerings such as SAP NS2, Delos Cloud, and BLEU, SAP and Microsoft continue to deepen their collaboration to deliver trusted sovereign cloud solutions for customers worldwide. Together, SAP and Microsoft are expanding support for RISE with SAP on SAP Sovereign Cloud running on Azure, giving customers greater choice in how and where they run mission‑critical SAP workloads, without compromising data residency, security, or governance.
Learn more about this announcement
Customers benefit from Microsoft’s and SAP’s sovereign cloud and service capabilities, supporting strong data residency, security, and governance.
The offering is available for customers today in these regions, with continuous worldwide expansion:
Australia
New Zealand
Canada
India
Europe
The United Kingdom
Together, SAP and Microsoft are empowering customers to innovate while maintaining the highest standards of sovereignty and trust.
Expanding platform availability and ecosystem innovation
Microsoft and SAP continue to expand global availability and ecosystem integration:
SAP Business Technology Platform (BTP) is available on Azure, the leading hyperscaler for SAP BTP, with 12 Azure regions live, so customers can meet data residency, and compliance needs while improving performance and scaling innovation closer to their users.
Azure Marketplace provides a streamlined path to discover and procure SAP BTP, SAP LeanIX solutions, and SAP Business Suite, helping customers standardize purchasing, accelerate deployments, and simplify governance through consolidated billing and procurement workflows (available in the US Azure Marketplace).
Joint innovations are enabling deeper integration with Microsoft 365, Teams, and Azure AI—unlocking productivity gains and new business scenarios.
These advancements reinforce Azure as a leading cloud platform for SAP workloads—supporting both migration and innovation at scale.
Cloud Acceleration Factory expansion: Driving AI innovation for SAP
We are expanding Cloud Acceleration Factory to help SAP customers and partners move beyond migration and unlock immediate AI value. By enabling integration between Microsoft 365 Copilot and SAP Joule within RISE and GROW environments, organizations can seamlessly connect data, workflows, and productivity tools from day one, accelerating real business outcomes with AI.
Through Azure Accelerate, customers can quickly operationalize AI with the first three agent-based use cases, built and deployed using Copilot Studio or Foundry. These prebuilt agents automate key business processes and establish a foundation for scaling intelligent operations across the enterprise.
This expansion is further strengthened by Microsoft Sentinel for SAP, providing integrated security and monitoring across SAP landscapes. Together, these innovations enable customers and partners to securely adopt AI and immediately take advantage of SAP and Microsoft’s joint AI innovation, accelerating time to value and increasing measurable business impact on Azure.
Expanding the Global RISE with SAP Acceleration Program on Microsoft Azure
Microsoft and SAP are excited to announce the expansion of the global RISE with SAP Acceleration program on Microsoft Azure, a joint initiative between Microsoft and SAP designed to deliver technical expertise, support, and innovation for RISE with SAP on Microsoft Azure customers.
In 2026, we will more than double the number of customers allowed into the program, marking an important milestone in our mission to provide RISE with SAP on Azure customers extraordinary support and expertise throughout their experience. Thousands of enterprise customers are already transforming their businesses with RISE on Azure, including Nestle, Migros, and Samsung.
First publicly announced in January 2025, this program brings together the best technical teams from SAP and Microsoft to enable a more seamless, high-touch migration and onboarding experience for the customer with no additional cost for an accelerated path to business transformation and faster cloud innovation.
Customer innovation in action
From manufacturing to logistics to energy, organizations are building more intelligent, resilient enterprises on Microsoft Cloud—where insights are embedded into workflows and decisions are driven in real time.
For example, Riddell, leading designer and manufacturer of protective sports equipment and helmets, modernized its operations on Azure to gain deeper visibility across its business and accelerate decision-making. In the logistics sector, Maersk transformed its global SAP estate on Azure to improve scalability and operational efficiency, creating a stronger foundation for innovation across its supply chain. And in the energy industry, MAIRE is enhancing its security posture with Microsoft Sentinel—gaining greater visibility and protection across its SAP and enterprise environments.
At SAP Sapphire 2026, you will also hear directly from Cargill, showcasing how it has modernized its SAP environment on Azure while preparing for an AI-powered future—bringing together SAP data, Copilot, and a secure, governed cloud platform to enable new business scenarios.
Together, with Microsoft and SAP, customers are moving beyond transformation to continuous, AI-powered innovation, using data and AI intelligence with embedded security as core drivers of growth and competitive advantage.
A global partner ecosystem driving scale
Partners play a critical role in helping customers navigate their SAP journey—from migration to modernization to AI transformation. Together, we are enabling industry-specific solutions, accelerating deployment timelines, and ensuring customers can realize value faster.
This ecosystem approach allows organizations to not only adopt new technologies, but also to operationalize them effectively—turning innovation into tangible business impact.
Supported by Microsoft’s cloud, data and AI platforms, EY teams built the EY.ai Agentic Acceleration Engine, which allowed them to analyze SAP business processes, identify over 175 high‑value agentic use cases, and rapidly translate them into interactive prototypes and solution designs that produce tangible impact, including agent teams supporting SAP‑based financial close activities, and intelligent supply chain and inventory management platforms where AI agents transact directly across SAP Finance, Logistics, Inventory and Sales modules. Together, EY teams and Microsoft are demonstrating how agentic AI can extend SAP from a system of record into a system of autonomous action—delivering measurable operational value today while creating a scalable blueprint for future enterprise transformation.
Unlock SAP value with EY, Microsoft and agentic AI
Modernizing large SAP environments often involves a difficult trade-off between speed, risk, and business continuity. For Microsoft, maintaining uninterrupted operations while transitioning to SAP S/4HANA was essential. Together with SNP, the company used a selective data migration approach to complete the transformation over a single weekend.
Massive scale with zero disruption: How Microsoft modernized to S/4HANA in record time with SNP
Powering the future of SAP with Microsoft Cloud
As enterprises look ahead, the opportunity is no longer just to transform SAP systems—it is to reimagine how business runs end-to-end.
Microsoft Cloud is uniquely positioned to enable this next phase. By combining a globally trusted cloud platform with a unified data foundation, advanced AI capabilities, and a seamless productivity layer, Microsoft provides customers with the full stack needed to move from ERP-centric operations to intelligent, AI-powered enterprises.
Our partnership with SAP is foundational to this vision. Together, we are driving innovation across cloud, data, and AI—creating a platform where insights, decisions, and actions are continuously connected.
This is what sets Microsoft apart in the SAP ecosystem. It’s not just about where customers run their SAP workloads—it’s about how they unlock new value across their entire business, using data and AI to drive outcomes, accelerate innovation, and stay competitive in a rapidly evolving world.
Together with SAP, we are shaping a future where enterprise systems are no longer static—but adaptive, intelligent, and built for continuous innovation.
Discover what SAP and Microsoft Cloud have to offer
Visit us at SAP Sapphire 2026 this week at booth #302 in Orlando, Florida and at #9.203 in Hall 9 in Madrid, Spain. Register for the Microsoft sessions.
Read our product blog for additional details on the announcements.
Read more about how customers are unlocking AI innovation and business transformation with SAP and Microsoft Cloud.
SAP on the Microsoft Cloud
Discover why Microsoft Cloud is the leading cloud platform for SAP workloads.
Learn more
The post Advancing enterprise AI: New SAP on Azure announcements from SAP Sapphire 2026 appeared first on Microsoft Azure Blog.
Quelle: Azure