A few years ago, the most powerful AI tools in a developer’s workflow helped write code. Today, they can do much more. It’s increasingly common to hand an AI agent a task like:
Read this repository, refactor the authentication service to match the new specification, run the test suite, and open a pull request if everything passes.
The agent reads files, analyzes dependencies, executes commands, modifies code, and interacts with external systems. In many cases, it can complete meaningful chunks of engineering work with minimal supervision. The shift sounds incremental until you realize something important: We’re no longer delegating suggestions. We’re delegating actions.
What’s interesting is that the biggest challenge increasingly isn’t whether agents can perform these tasks. In many cases, they already can. The harder question is whether developers trust them enough to delegate meaningful work. The bottleneck is shifting from capability to confidence.
While reading Srini Sekaran’s recent announcement introducing Docker AI Governance, one statement stood out:
“Your laptop is the new prod.”
The more I thought about it, the more it felt less like a marketing tagline and more like a useful way to understand what is changing about software development.
From Assistants to Agents
The last few years of developer tooling can be viewed as a progression. First, AI tools assisted developers by generating snippets and answering questions. Then, copilots emerged, helping developers complete larger tasks within existing workflows. Now we’re entering the era of agents. Unlike earlier tools, agents don’t just recommend actions. They increasingly perform them. Once software begins taking actions instead of offering suggestions, the governance conversation changes fundamentally.
A Small Observation From Building With Agents
One thing I’ve noticed while working on AI projects and experimenting with agent-based workflows is how quickly the trust boundary moves.
When I first started using AI tools, I mostly treated them like a second set of eyes. I’d ask questions about a codebase, sanity-check an approach, generate a small piece of code, or help make sense of documentation. The tools were useful, but they weren’t doing anything on their own. Every action still depended on me deciding what happened next. That changed as coding agents became more capable.
Tasks that previously involved copying code between windows increasingly became workflows where an agent could inspect a repository, modify files, run tests, and iterate on failures with minimal supervision. The productivity gains were undeniable, but so was the realization that the agent now had access to the same environment, credentials, and tooling that I did.
As a Docker Captain, this is what makes the current conversation around AI governance so interesting to me. The challenge isn’t simply that models are becoming more capable. It’s that they’re increasingly interacting with real systems rather than generating text in isolation.
Once an agent can execute actions on your behalf, the challenge is no longer just capability. Developers need confidence that the agent will operate within understood boundaries. Governance becomes important not only because it protects systems, but because it helps people trust the systems they are using.
Why Developers Still Hesitate
Most developers aren’t worried about whether agents can generate code. They’re worried about whether the agent will operate predictably once it starts interacting with real systems. That hesitation often comes from the fact that our existing trust models were designed around human operators, not autonomous software.
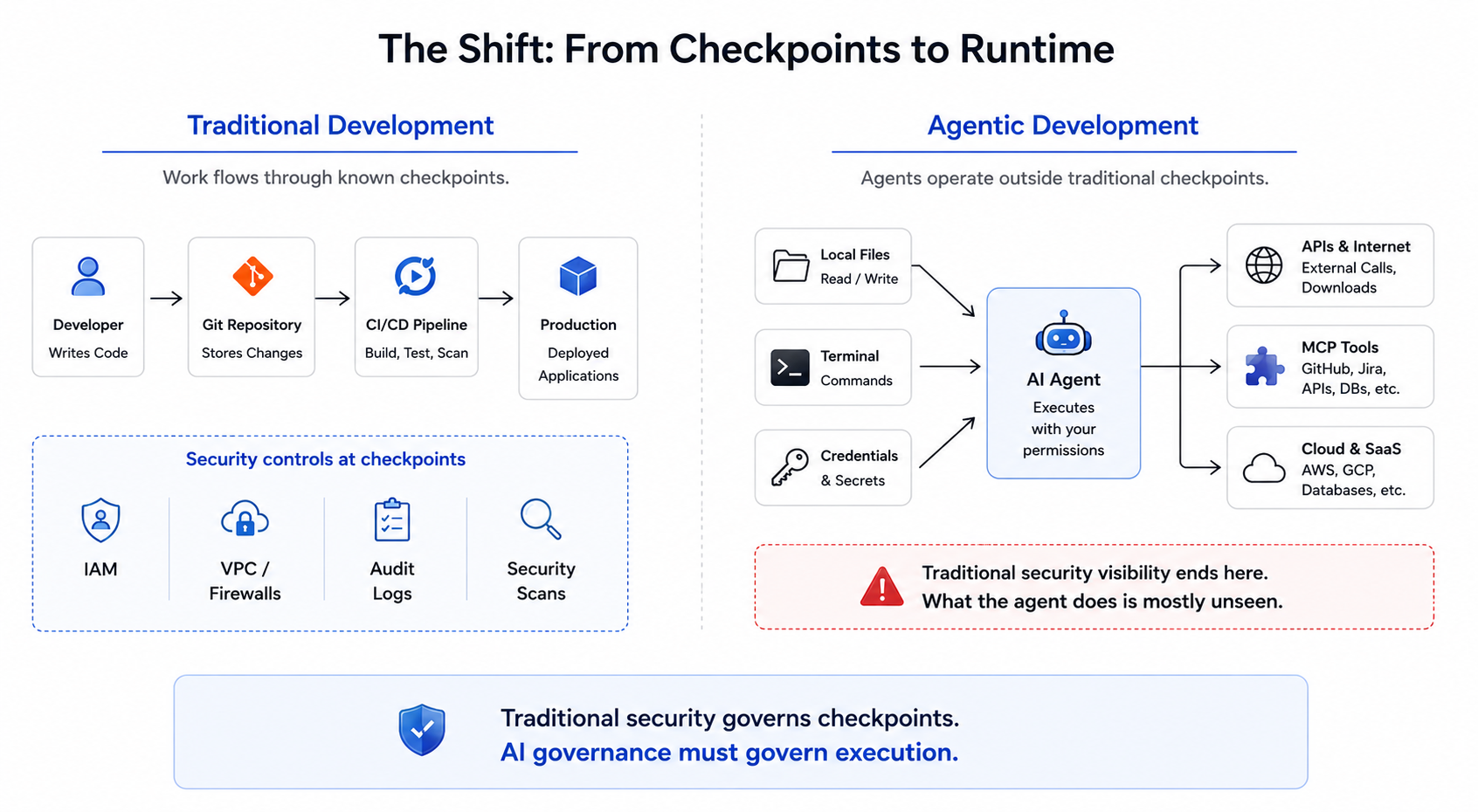
Most enterprise security controls evolved around a relatively simple assumption: humans perform actions and systems enforce controls around those actions. Source code flows through repositories. Changes pass through CI/CD pipelines. Production workloads run inside managed environments. Identity systems determine who can access what. Network controls restrict where workloads can communicate. The security stack works because work typically moves through predictable checkpoints. Organizations know where to observe activity, apply policy, and collect audit trails.
Agents Don’t Follow Those Checkpoints
AI agents introduce a different operating model. An agent running on a developer’s machine can inspect repositories, execute commands, install packages, access local files, query APIs, and interact with external tools all within a single session. More importantly, it often does so using the same permissions as the person operating it. From the organization’s perspective, a significant amount of work is shifting outside the systems that were originally designed to govern it. The laptop is no longer just where code is written. It is increasingly where decisions are executed.
Figure 1. Traditional security governs workflow checkpoints. Agent governance must account for execution at runtime.
A coding agent doesn’t need to wait for a pull request before interacting with a codebase. It can analyze and modify files long before a change reaches a repository. It can access credentials available to the local environment. It can connect to external services using the same permissions available to its operator.
Consider a common scenario: an agent is asked to investigate why an integration test is failing. To debug the issue, it might inspect configuration files, generate temporary scripts, install additional dependencies, execute diagnostic commands, and repeatedly rerun the test suite before a human ever reviews the result. None of these actions are unusual, but they illustrate how much activity can now occur directly within the developer’s environment. This doesn’t make agents inherently unsafe. It does mean that many existing security assumptions deserve a second look.
Why Prompt-Based Guardrails Aren’t Enough
One common response is to rely on instructions. Tell the agent not to access sensitive files. Tell the agent not to call external services. Tell the agent not to perform risky actions. These instructions are useful, but they are fundamentally different from enforcement. A prompt can influence behavior. A runtime can restrict behavior. That distinction becomes increasingly important as agents gain more autonomy. Security has traditionally been strongest when controls exist below the application layer. Filesystem permissions don’t suggest restrictions; they enforce them. Network policies don’t ask whether traffic should be blocked; they block it. The same principle applies to AI agents. If an organization wants confidence in what an agent can and cannot do, those guarantees ultimately need to exist at the layer where actions are actually executed.
The Two Ways Agents Interact With The World
When I simplify the problem, most agent activity falls into two categories. The first is execution. Agents read files, modify code, install software, execute commands, and open network connections. The second is tool usage. Agents interact with external systems through APIs, integrations, and MCP tools. These might include GitHub, Jira, cloud platforms, internal services, communication tools, or customer systems. Both paths create tremendous value. Both paths can also introduce risk. Governing only one of them leaves a blind spot. An organization might carefully control external tool access while overlooking what an agent can execute locally. Or it might secure local execution while providing broad access to external systems. Effective governance requires visibility and control across both surfaces.
The Governance Challenge
The question for many organizations is no longer whether AI agents will be adopted, but how they can be adopted responsibly. That decision is already being made in engineering teams around the world because the productivity gains are real. The more important question is how organizations can embrace agent autonomy without sacrificing visibility, accountability, and control. Just as importantly, developers need confidence that they understand those boundaries. The easier it is to understand what an agent can access, execute, and modify, the easier it becomes to incorporate agents into everyday workflows. Traditional security models were built around infrastructure boundaries. Agent governance increasingly requires runtime boundaries.
Where is the agent running?
What can it access?
What can it execute?
Which tools can it invoke?
Which credentials can it use?
And can those controls be enforced consistently regardless of whether the agent is running on a laptop, in CI, or in production?
These questions are quickly becoming infrastructure questions, not merely AI questions. Because if AI agents are becoming active participants in software delivery, then the environments they operate in deserve the same level of attention that we have historically given to production systems.
The laptop is no longer just where software gets written. Increasingly, it’s where software acts. And that’s why “your laptop is the new prod” feels less like a prediction and more like a description of where modern development is already headed. The real challenge isn’t simply giving agents more autonomy. It’s creating environments where developers feel comfortable using that autonomy. Because the future of agentic development may depend less on what agents are capable of doing and more on what developers are willing to trust them to do.
In Part 2, we’ll explore what governance looks like at the runtime layer and why isolation, policy enforcement, and controlled tool access are becoming foundational building blocks for agentic systems.
Quelle: https://blog.docker.com/feed/