Waymo: Robotaxis verursachen Stau während Stromausfall
Am Samstag sind Waymo-Taxis im laufenden Verkehr stecken geblieben und haben Staus in San Francisco verursacht. Grund war wohl ein Stromausfall. (Waymo, Auto)
Quelle: Golem

Am Samstag sind Waymo-Taxis im laufenden Verkehr stecken geblieben und haben Staus in San Francisco verursacht. Grund war wohl ein Stromausfall. (Waymo, Auto)
Quelle: Golem

Die meisten Streamingdienste bieten inzwischen ein Abo mit Werbung an. Bei Netflix und Disney+ steigen die Abonnenten hierfür deutlich. (Streaming, Disney)
Quelle: Golem

Dazu gehören ein experimentelles Frachtraumfahrzeug, eine Technik-Demomission und ein Fernerkundungssatellit. (Satelliten, Raumfahrt)
Quelle: Golem

GTA: Vice City aus 2002 ist ein Liebling der Fans. Ein Projekt von Enthusiasten macht den vierten Teil der Serie nun im Browser spielbar. (Rockstar, Urheberrecht)
Quelle: Golem

Am Boden unterlegen, wehrt sich die Ukraine per Luftoffensive. Doch trotz neuer Waffensysteme erreichen kaum Flugkörper ihr Ziel. Warum? Eine Analyse von Friedrich List (Ukrainekrieg, Politik)
Quelle: Golem
At Microsoft Ignite 2025, we explored what it means for organizations to move into the era of Frontier transformation. This shift is focused on embedding AI across every part of the business to improve decision-making, increase speed, and create new value. Organizations leading in AI make it foundational. They rethink processes and integrate new technologies from the start to improve efficiency.
For partners, this move toward Frontier represents a significant opportunity to lead customers into this new era. By building AI-powered solutions, connecting data for intelligent insights, and deploying Microsoft Azure’s cloud-ready platforms, partners can deliver value faster and scale confidently through the Microsoft ecosystem.
Microsoft Ignite came with a significant number of announcements, so I’ve gathered the Azure updates that matter most for partners. These are the capabilities that can strengthen your ability to deliver intelligent solutions, drive operational efficiency, and differentiate your product or service in the market. You can also explore how partners are turning momentum into action, access highlights, and grab practical guidance from my Microsoft Ignite session.
Azure Copilot: Now in private previewAzure Copilot introduces specialized agents to the Azure portal, PowerShell, and CLI. Powered by Azure Resource Manager (ARM)-driven scenarios and advanced AI models from Microsoft and partners, Azure Copilot streamlines migration, assessment, and modernization activities with data-driven insights, guided workflows, and improved governance across customer environments. For partners, this creates a unified way to deliver intelligent automation for cloud workloads, accelerate modernization projects, reduce operational overhead, and strengthen governance through integrated agentic workflows across Azure and GitHub Copilot.
For more information, check out these additional resources:
Blog: Ushering in the Era of Agentic Cloud Operations with Azure CopilotMicrosoft Ignite session: Agentic AI Tools for Partner-Led Migration and Modernization SuccessMicrosoft Ignite session: Partners: Accelerate Secure Migrations and Innovate in the Era of AI
Foundry Control Plane: Now in public previewMicrosoft Foundry Control Plane extends Agent 365 by bringing unified visibility, security, and control to AI agents operating across the Microsoft Cloud. It centralizes policy management, lifecycle governance, and observability, offering a consistent way to manage agent behavior and performance. By providing enterprise-grade governance and security capabilities that support safe, scalable, and efficient agent management for customers across varied environments, Control Plane empowers confident deployment and operation of AI-powered solutions.
For more information, review these additional resources:
Microsoft Learn: What is the Microsoft Foundry Control Plane?Microsoft Ignite session: Build Partner Advantage: Drive Key AI Use-Cases with Azure Tech Stack
Foundry IQ: Now in public previewFoundry IQ provides a unified endpoint for agent knowledge, automating source routing and retrieval workflows through Azure AI Search. It equips agents to work with enterprise content securely and with greater contextual grounding by connecting a unified knowledge base to multiple data sources. For partners, this creates a streamlined way to build retrieval augmented generation (RAG) solutions, link agents to customer-specific knowledge sources, and deliver consistent, context-rich capabilities that empower organizations to unlock more value from their data.
Read our blog to learn more: Foundry IQ: Unlocking ubiquitous knowledge for agents
Fabric IQ: Now in public previewMicrosoft Fabric IQ offers a live, unified view of enterprise data and AI agents, organizing information by business concepts and using OneLake to support real-time analytics across hybrid and multicloud environments. For partners, Fabric IQ creates a foundation for building intelligent, context-aware solutions that align to business processes, accelerate analytics performance, and strengthen governance to improve reliability and efficiency across customer deployments.
For more information, check out these additional resources:
Blog: From Data Platform to Intelligence Platform: Introducing Microsoft Fabric IQMicrosoft Ignite session: Microsoft Fabric IQ: Turning unified data into unified intelligenceMicrosoft Ignite session: How Microsoft’s data platform is creating value for partners
Microsoft Agent Factory: Now availableMicrosoft Agent Factory is a new program designed for organizations that want to move from experimentation to execution faster. At the heart of this program is the Microsoft Agent Pre-Purchase Plan (P3), which streamlines procurement and reduces complexity. With P3, partners can offer their customers access to 32 Microsoft services through one flexible pool of funds, eliminating the need to manage multiple contracts or choose between platforms. This single metered plan not only reduces upfront licensing and provisioning but also supports greater predictability for organizations investing in AI innovation. Eligible organizations can also tap into hands-on support from top AI Forward Deployed Engineers (FDEs) and access tailored, role-based training to boost AI fluency across teams. Together, they unlock new opportunities for growth and innovation while encouraging customers to confidently embrace the future of AI.
Read our blog to learn more: Accelerate innovation with Microsoft Agent Factory
Microsoft Foundry: Anthropic Claude models are now availableMicrosoft Foundry now offers Anthropic Claude models that support advanced reasoning for research, coding, and agentic workflows, all within the Microsoft unified governance and observability framework. For partners, this expands choice across model capabilities to develop multistep agents using the right model per task while maintaining governance and deployment consistency across Azure, Foundry, and Microsoft 365 Copilot environments.
Read our blog to learn more: Introducing Anthropic’s Claude models in Microsoft Foundry: Bringing Frontier intelligence to Azure
Resale enabled offers: Now available through Microsoft MarketplaceResale enabled offers are now available in nearly all Marketplace-supported regions, allowing software companies to work with channel partners to manage listings and expand reach. For partners, this creates new channel-led sales opportunities by making it easier to promote and manage listings on behalf of publishers and reach more customers globally without adding operational complexity.
For more information, check out these resources:
Marketplace: Cloud solutions, AI apps, and agentsBlog: The Microsoft Marketplace opportunity for channel ecosystemMicrosoft Ignite session: Executing on the channel-led marketplace opportunity for partnersMicrosoft Ignite session: Marketplace success for partners—from SMB to enterpriseMicrosoft Ignite session: Partner: Benefits for Accelerating Software Company Success
Azure HorizonDB for PostgreSQL: Now in private previewAzure HorizonDB is a new PostgreSQL cloud database for mission-critical applications and modern AI workloads, offering auto-scaling storage, rapid compute scale out, advanced vector indexing, and integration with the Microsoft AI and analytics ecosystem. For partners, HorizonDB supports the development of intelligent and resilient applications, modernization of legacy systems, and creation of high-performance data platforms designed for security, scale, and future AI workloads.
Check out these additional resources:
Blog: Announcing Azure HorizonDBPreview sign-up: Apply for the preview hereMicrosoft Ignite session: Azure HorizonDB: Deep Dive into a New Enterprise-Scale PostgreSQL
Microsoft Agent 365: The control plane for AI agentsAgent 365 extends the Microsoft user management infrastructure to AI agents, empowering organizations to govern agents across Microsoft 365, Azure, and Foundry. Available in the Microsoft 365 admin center with the Frontier program, it combines capabilities from Microsoft 365 Defender, Entra, Purview, and Microsoft 365 for unified security, productivity, and management. For partners, this creates a consistent approach to deploying, securing, and managing fleets of AI agents across customer environments with streamlined governance and operational clarity.
Read our blog to learn more: Microsoft Agent 365: The control plane for AI agents
Looking forwardMicrosoft Ignite is about more than product updates; it’s a time to celebrate what we can achieve together as partners. Continue your journey and explore the Cloud & AI Platforms partner sessions at Microsoft Ignite and read the Azure at Microsoft Ignite 2025: All the intelligent cloud news explained blog post for more product updates.
Stay connected with us. Follow Microsoft Partner on LinkedIn, join the conversation in our Partner News Community, and explore the Microsoft partner site to keep your momentum going.
For details on recent announcements, please read the “What’s new in Azure for Partners” newsletter on the Microsoft Community Hub and follow the tag “Azure News” to stay updated.
November update: What’s new in Azure for Partners | Microsoft Community HubOctober update: What’s new in Azure for Partners | Microsoft Community Hub
The post Azure updates for partners: December 2025 appeared first on Microsoft Azure Blog.
Quelle: Azure
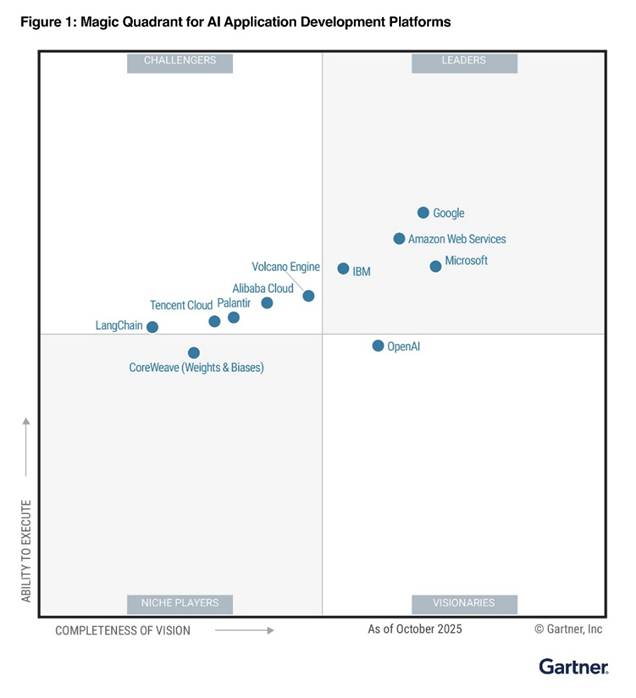
A recognition for AI innovation
Microsoft is recognized as a Leader in the 2025 Gartner® Magic Quadrant™ for AI Application Development Platforms and is positioned furthest for Completeness of Vision. This leadership reflects a long‑term conviction: the next wave of applications is agentic, and real customer impact requires far more than great demos. Organizations need agents grounded in real data and tools, capable of driving business workflows, and governed with end‑to‑end observability at scale. Our investment in agent frameworks, orchestration, and enterprise‑grade governance is how we make that full journey real and practical for every customer.
Read the full Gartner report
Why we believe this matters
Gartner evaluates vendors on two dimensions: Completeness of Vision (where the platform is headed) and Ability to Execute (whether it can deliver today). Being positioned furthest on vision isn’t about having the boldest roadmap: it’s about whether that vision translates into the real capabilities customers need for the future of AI.
Microsoft Foundry is our unified platform for building, deploying and governing AI applications—and over the past year, we’ve focused it on four areas that customers tell us separate production AI from proof-of-concept:
Real data, real tools. Agents are only as useful as what they can access. Foundry IQ provides a single secure grounding API that connects agents to enterprise data, while Foundry Tools offers over 1,400 pre-built connectors for document processing, translation, speech, and business systems.
Workflow integration, not just conversation. The shift from chatbot to agent means moving from Q&A to action. Foundry Agent Service supports multi-agent orchestration where agents can handle off tasks, coordinate decisions, and drive end to end business processes: deployable directly into Copilot or your applications.
Observability and governance at scale. When agents act autonomously, you need to see what they’re doing and why. Foundry Control Plane provides organization-wide visibility, audit trails, and policy enforcement. “Trust but verify” doesn’t scale without tooling.
Models from cloud to edge. Build and run AI models wherever your workloads live—from cloud to edge. Fine-tune and deploy models from Foundry Models using enterprise-grade GenAI Ops, then run them on-device with Foundry Local for low-latency, offline, or regulated scenarios.
With these pillars in place, Foundry delivers everything organizations need to build AI applications and multi-agent systems at scale. That’s why we’ve ensured it works seamlessly with the tools developers and businesses use most. Foundry integrates deeply with development tools including Visual Studio Code, GitHub, Azure, and productivity tools such as Microsoft 365, Microsoft Teams, and the broader enterprise stack.
Explore Microsoft Foundry
Walking the talk: Our agent-driven approach
This year, Microsoft adopted a fundamentally new approach for preparing our submission for AI Application Development Platforms. Instead of relying on manual data gathering and coordination, our team developed custom agents designed to collect, organize, and validate all the information required for the evaluation.
How the agent was created:
The agent’s development is detailed in a recent blog post, which outlines the technical architecture and methodology behind its creation. Built using Microsoft Agent Framework, our open-source offering, the agents leverage advanced orchestration capabilities and multimodal content processing. It was designed to automate the complex process of assembling submission data, ensuring accuracy and completeness while reducing manual effort.
Technical highlights:
The agent uses a structured prompt and workflow, as specified here. It integrates with Microsoft Foundry platform-as-a-service (PaaS) model, supporting both pay-as-you-go and provisioned throughput options.
Benefits of the agent-driven process:
By automating the submission workflow, the agent improved data accuracy and transparency, allowing our experts to focus on strategic insights rather than manual compilation. The process was more efficient, reduced the risk of errors, and ensured that our submission was both comprehensive and up to date.
This innovation reflects Microsoft’s commitment to technical excellence and continuous improvement, providing customers with greater confidence in the quality and reliability of its AI solutions. By streamlining critical processes, Microsoft delivers more accurate, transparent, and timely updates, enabling organizations to make informed decisions and accelerate innovation with enterprise-grade AI platforms that maintain compliance and security standards.
Empowering organizations with Microsoft Foundry
We believe our recognition in the Gartner Magic Quadrant™ for AI Application Development Platforms is a testament to Microsoft’s commitment to empowering organizations to develop robust, scalable, and intelligent AI solutions. The agent-driven submission process exemplifies our drive to innovate, operate transparently, and share process with our community.
More than 80,000 enterprises and software development companies across healthcare, manufacturing, and retail industries are leveraging Foundry to deliver transformative solutions—from predictive supply chain insights to personalized customer experiences. These success stories highlight how Foundry accelerates innovation while maintaining trust and compliance.
Genie is offering provider practices a way to use AI to converse with patients through their preferred channel. This will reduce the amount of administrative work and cost for practices to simply give patients the answers to their questions.
Sidd Shah, Vice President of Strategy & Business Growth, healow
With Genix Copilot, we have unlocked the power of generative and agentic AI from shop floor to top floor, cutting troubleshooting time by 60-80%. Genix Copilot on Azure OpenAI is reshaping industrial performance and advancing environmental goals, turning data into real outcomes for customers across very different sectors.
Rajesh Ramachandran, Global Chief Digital Officer, Process Automation, ABB
Foundry Agent Service and Microsoft Agent Framework connect our agents to data and each other, and the governance and observability in Microsoft Foundry provide what KPMG firms need to be successful in a regulated industry.
Sebastian Stöckle, Global Head of Audit Innovation and AI, KPMG International
Microsoft is at the cutting edge of AI-based shopping, and with Ask Ralph, we’re blending the world of fashion and the world of technology to reimagine how consumers shop online.
Naveen Seshadri, Chief Digital Officer, Ralph Lauren
Thank you to our customers and partners for making this recognition possible. We look forward to helping you grow more with Microsoft Foundry.
Discover resources for your AI journey
Read the Gartner report
Discover more at Microsoft Customer Stories
Learn more about Microsoft Foundry
*Gartner, Magic Quadrant for AI Application Development Platforms, 17 November 2025
Gartner and Magic Quadrant are registered trademarks of Gartner, Inc. and/or its affiliates and is used herein with permission. All rights reserved.
This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from Microsoft.
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s business and technology insights organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
The post Microsoft named a Leader in Gartner® Magic Quadrant™ for AI Application Development Platforms appeared first on Microsoft Azure Blog.
Quelle: Azure

Von Cloud- und Security-Engineering über Softwareentwicklung bis IT-Management: Diese Positionen verbinden Technologie mit Verantwortung. (Golem Karrierewelt, Betriebssysteme)
Quelle: Golem

Die Geschichte einer frühen Spielekonsole, die fast in Vergessenheit geriet. Von Martin Wolf (golem retro_, Homebrew)
Quelle: Golem
2025 was the year software teams stopped optimizing models and started optimizing systems.
By December, a few truths were impossible to ignore.
1. Developer Productivity Became the Real Competitive Advantage
By mid-year, every major AI lab had cleared the “good enough reasoning” bar. With model quality converging, the differentiator was no longer raw intelligence. It was how fast teams could ship.
The fastest teams used systems that were:
Declarative: automation defined in YAML and config, not code
Composable: agents calling tools with minimal glue
Observable: evaluated, traced, and versioned
Reproducible: identical behavior every run
Productivity became a platform problem, not a talent problem.
2. Security Went From “Filters” to “Blast Radius”
The real problem wasn’t what models say. It was what they could do.
Once agents can act, blast radius matters more than the prompt.
Production incidents across the industry made it clear:
Agents leaking internal data within minutes
Malicious plugins shipping ransomware
Supply-chain bugs in AI tooling
Agents deleting repos or months of work
Smart teams adopted the same guardrails they use for privileged system processes:
Sandboxed runtimes
Containerized toolchains
Signed artifacts
Policies in front of tool calls
Hardened bases and reproducible builds
The industry stopped filtering danger out of the model. They focused on containing it.
3. Agents Stopped Being Demos
Agents became good enough to do real jobs.
At the start of the year, “agent” meant a clever prototype. By the end, agents were doing operational work: updating infrastructure, resolving customer issues, moving money, managing SaaS tools.
Two shifts unlocked this:
Reasoning took a leap.OpenAI’s o3 solved 25% of FrontierMath, problems that take researchers hours or days. DeepSeek sent waves with their R1 model, proving that the frontier moved from model size to compute at inference time.
Tools became standardized.MCP became the USB-C port of AI, a universal way for agents to safely access tools, data, and workflows. Once the ecosystem aligned on a common port, everything accelerated.
4. Containers Quietly Remained the Execution Layer for Everything
Containers continued doing the quiet work of powering every stack.
More than 90% of companies used containers as the default environment where:
Applications run
Build systems operate
Agents execute real tasks
Infrastructure is tested before hitting production
Even in an agent-driven world, developers need environments that act the same way every time. Containers remained a universal, stable execution surface.
5. Hardened Images Became the New Starting Point
You can’t trust the system if you don’t trust the base image.
Docker Hardened Images (DHI) solved the first question every team had to ask: “What are we actually running?”
DHI answered that with:
A known, verified base image
A transparent bill of materials
Reproducible builds
Signed artifacts
When hardened images became free, the cost of doing the right thing dropped to zero. Teams no longer layered security patches on top of unknown upstream risk. They began from a secure, trusted baseline.
What’s Next for 2026
The race for raw model intelligence is over. What separates winners in 2026 will be everything around the model.
Agents become a standard runtime target. Versioned and deployed like services.
Security frameworks treat agents as users. With permissions, onboarding, and monitoring.
Ecosystem gravity increases. MCP is the start. The dominant tool interface becomes the center of the agent economy.
Trust becomes infrastructure. Signed models to verified tools to hardened bases. Winners will have the smallest blast radius when things break.
The term “AI engineer” fades. What remains is what has always been: software engineers who build secure, governable, and resilient systems.
In 2023, we learned to talk to models. In 2024, we learned to chain them. In 2025, we gave them real power.
2026 will be about earning the right to keep it.
Quelle: https://blog.docker.com/feed/