Einzelstück: Mini stellt elektrisches Cabrio vor
Mini hat ein Einzelstück des Mini Electric als Cabrio vorgestellt. Das Elektroauto wird derzeit auf einem Kundenevent präsentiert. (BMW, Technologie)
Quelle: Golem

Mini hat ein Einzelstück des Mini Electric als Cabrio vorgestellt. Das Elektroauto wird derzeit auf einem Kundenevent präsentiert. (BMW, Technologie)
Quelle: Golem

Zwar bleibt die Geheimniskrämerei um Fuchsia weiter bestehen. Aus dem Code von Google lassen sich dennoch Pläne ableiten. (Fuchsia, Google)
Quelle: Golem

Die FDP will Homeoffice-Regeln unterstützen, sollte es einen Gas-Lieferstopp geben. Dann würden Büro-Gebäude weniger geheizt. (Homeoffice, Bundesregierung)
Quelle: Golem

Der Bau zahlreicher Batteriezellwerke ist bereits angekündigt. Wenn das so weitergeht, könnte Deutschland ein Hauptstandort bei der Produktion werden. (Wissenschaft)
Quelle: Golem

Hasbro bietet Actionfiguren aus Star Wars, Marvel, Ghostbusters und GI Joe mit 3D-gedruckten Köpfen nach Kundenwunsch an. (Hasbro, Technologie)
Quelle: Golem

Ein LED-Smartphone und künstlerische Intelligenz: die Woche im Video. (Golem-Wochenrückblick, Elon Musk)
Quelle: Golem

Transformers und Lego sollten ein natürliches Match sein. Optimus Prime sieht auch cool aus und verwandelt sich, fällt aber fix auseinander. Von Oliver Nickel (Lego, Test)
Quelle: Golem
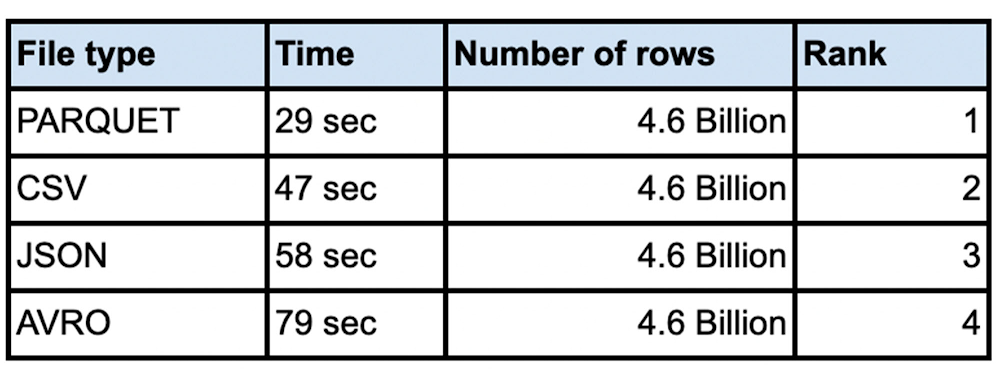
It is not unusual for customers to load very large data sets into their enterprise data warehouse. Whether you are doing an initial data ingestion with hundreds of TB of data or incrementally loading from your systems of record, performance of bulk inserts is key to quicker insights from the data. The most common architecture for batch data loads uses Google Cloud Storage(Object storage) as the staging area for all bulk loads. All the different file formats are converted into an optimized Columnar format called ‘Capacitor’ inside BigQuery.This blog will focus on various file types and data loading tools for best performance. Data files that are uploaded to BigQuery, typically come in Comma Separated Values(CSV), Avro, Parquet, JSON, ORC formats. We are going to use a large dataset to compare and contrast each of these file formats. We will explore loading efficiencies of compressed vs. uncompressed data for each of these file formats. Data can be loaded into BigQuery using multiple tools in the GCP ecosystem. You can use the Google Cloud console, bq load command, using the BigQuery API or using the client libraries. We will also compare and contrast each loading mechanism for the same dataset. This blog attempts to elucidate the various options for bulk data loading into BigQuery and also provides data on the performance for each file-type and loading mechanism.Introduction There are various factors you need to consider when loading data into BigQuery. Data file formatData compressionTool used to load dataLevel of parallelization of data loadSchema autodetect ‘ON’ or ‘OFF’Data file formatBulk insert into BigQuery is the fastest way to insert data for speed and cost efficiency. Streaming inserts are however more efficient when you need to report on the data immediately. Today data files come in many different file types including comma separated(CSV), json, parquet, avro to name a few. We are often asked how the file format matters and whether there are any advantages in choosing one file format over the other. CSV files (comma-separated values) contain tabular data with a header row naming the columns. When loading data one can parse the header for column names. When loading from csv files one can use the header row for schema autodetect to pick up the columns. With schema autodetect set to off, one can skip the header row and create a schema manually, using the column names in the header. CSV files can use other field separator/newline characters too as a separator, since many data outputs already have a comma in the data. You cannot store nested or repeated data in CSV file format.JSON (JavaScript object notation) data is stored as a key-value pair in a semi structured format. JSON is preferred as a file type because it can store data in a hierarchical format. The schemaless nature of json data rows gives the flexibility to evolve the schema and thus change the payload. JSON and XML formats are user-readable, but JSON documents are typically much smaller than XML. REST-based web services use json over other file types.Parquet is a column-oriented data file format designed for efficient storage and retrieval of data. Parquet compression and encoding is very efficient and provides improved performance to handle complex data in bulk.Avro: The data is stored in a binary format and the schema is stored in JSON format. This helps in minimizing the file size and maximizes efficiency. Avro has reliable support for schema evolution by managing added, missing, and changed fields. From a data loading perspective we did various tests with millions to hundreds of billions of rows with narrow to wide column data .We have done this test with a public dataset named `bigquery-public-data:worldpop.population_grid_1km`. We used 4000 flex slots for the test and the number of loading slots is limited to the number of slots you have allocated for your environment, though the load slots do not use all of the slots you throw at it.. Schema Autodetection was set to ‘NO’. For the parallelization of the data files each file should typically be less than 256MB for faster throughput and here is a summary of our findings:Do I compress the data? Sometimes batch files are compressed for faster network transfers to the cloud. Especially for large data files that are being transferred, it is faster to compress the data before sending over the cloud Interconnect or VPN connection. In such cases is it better to uncompress the data before loading into BigQuery? Here are the tests we did for various file types with different compression algorithms.Shown results are the average of five runs:How do I load the data?There are various ways to load the data into BigQuery. You can use the Google Cloud Console, command line, Client Library(shown python here) or use the Direct API call. We compared these data loading techniques and compared the efficacy of each method. Here is a comparison of the timings for each method. You can also see that Schema Autodetect works very well, where there are no datatype quality issues in the source data and you are consistently getting the same columns from a data sourceConclusionThere is no advantage in loading time when the source file is in compressed format. In fact for the most part uncompressed data loads in the same or faster time than compressed data. We noticed that for csv and avro file types you do not need to uncompress for faster load times. For other file types including parquet and json it takes longer to load the data when the file is compressed. Decompression is a CPU bound activity and your mileage varies based on the amount of load slots assigned to your load job. Data loading slots are different from the data querying slots. For compressed files, you should parallelize the load operation, so as to make sure that data loads are efficient. Split the data files to 256MB or less to avoid spilling over the uncompression task to disk.From a performance perspective avro, csv and parquet files have similar load times. Use the command line to load larger volumes of data for the most efficient data loading. Fixing your schema does load the data faster than schema autodetect set to ‘ON’. Regarding ETL jobs, it is faster and simpler to do your transformation inside BigQuery using SQL, but if you have complex transformation needs that cannot be done with SQL, use Dataflow for unified batch and streaming, Dataproc for open source based pipelines, or Cloud Data Fusion for no-code / low-code transformation needs.To learn more about how Google BigQuery can help your enterprise, try out Quickstarts page here.Disclaimer: These tests were done with limited resources for BigQuery in a test environment during different times of the day with noisy neighbors, so the actual timings and the number of rows might not be reflective of your test results. The numbers provided here are for comparison sake only, so that you can choose the right file types, compression and loading technique for your workload. Related ArticleLearn how BI Engine enhances BigQuery query performanceThis blog explains how BI Engine enhances BigQuery query performance, different modes in BI engine and its monitoring.Read Article
Quelle: Google Cloud Platform
IBM mainframes have been around since the 1950s and are still vital for many organizations. In recent years many companies that rely on mainframes have been working towards migrating to the cloud. This is motivated by the need to stay relevant, the increasing shortage of mainframe experts and the cost savings offered by cloud solutions. One of the main challenges in migrating from the mainframe has always been moving data to the cloud. The good thing is that Google has open sourced a bigquery-zos-mainframe connector that makes this task almost effortless.What is the Mainframe Connector for BigQuery and Cloud Storage?The Mainframe Connector enables Google Cloud users to upload data to Cloud Storage and submit BigQuery jobs from mainframe-based batch jobs defined by job control language (JCL). The included shell interpreter and JVM-based implementations of gsutil and bq command-line utilities make it possible to manage a complete ELT pipeline entirely from z/OS. This tool moves data located on a mainframe in and out of Cloud Storage and BigQuery; it also transcodes datasets directly to ORC (a BigQuery supported format). Furthermore, it allows users to execute BigQuery jobs from JCL, therefore enabling mainframe jobs to leverage some of Google Cloud’s most powerful services.The connector has been tested with flat files created by IBM DB2 EXPORT that contain binary-integer, packed-decimal and EBCDIC character fields that can be easily represented by a copybook. Customers with VSAM files may use IDCAMS REPRO to export to flat files, which can then be uploaded using this tool. Note that transcoding to ORC requires a copybook and all records must have the same layout. If there is a variable layout, transcoding won’t work, but it is still possible to upload a simple binary copy of the dataset.Using the bigquery-zos-mainframe-connectorA typical flow for Mainframe Connector involves the following steps:Reading the mainframe datasetTranscoding the dataset to ORCUploading ORC to Cloud StorageRegistering it as an external tableRunning a MERGE DML statement to load new incremental data into the target tableNote that if the dataset does not require further modifications after loading, then loading into a native table is a better option than loading into an external table.In regards to step 2, it is important to mention that DB2 exports are written to sequential datasets on the mainframe and the connector uses the dataset’s copybook to transcode it to an ORC.The following simplified example shows how to read a dataset on a mainframe, transcode it to ORC format, copy the ORC file to Cloud Storage, load it to a BigQuery-native table and run SQL that is executed against that table.1. Check out and compile:code_block[StructValue([(u’code’, u’git clone https://github.com/GoogleCloudPlatform/professional-servicesrncd ./professional-services/tools/bigquery-zos-mainframe-connector/rn rn# compile util library and publish to local maven/ivy cacherncd mainframe-utilrnsbt publishLocalrn rn# build jar with all dependencies includedrncd ../gszutilrnsbt assembly’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e135cd450>)])]2. Upload the assembly jar that was just created in target/scala-2.13 to a path on your mainframe’s unix filesystem.3. Install the BQSH JCL Procedure to any mainframe-partitioned data set you want to use as a PROCLIB. Edit the procedure to update the Java classpath with the unix filesystem path where you uploaded the assembly jar. You can edit the procedure to set any site-specific environment variables.4. Create a jobSTEP 1:code_block[StructValue([(u’code’, u’//STEP01 EXEC BQSHrn//INFILE DD DSN=PATH.TO.FILENAME,DISP=SHRrn//COPYBOOK DD DISP=SHR,DSN=PATH.TO.COPYBOOKrn//STDIN DD *rngsutil cp –replace gs://bucket/my_table.orcrn/*’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e115c0850>)])]This step reads the dataset from the INFILE DD and reads the record layout from the COPYBOOK DD. The input dataset could be a flat file exported from IBM DB2 or from a VSAM file. Records read from the input dataset are written to the ORC file at gs://bucket/my_table.orc with the number of partitions determined by the amount of data.STEP 2:code_block[StructValue([(u’code’, u’//STEP02 EXEC BQSHrn//STDIN DD *rnbq load –project_id=myproject \rn myproject:MY_DATASET.MY_TABLE \rn gs://bucket/my_table.orc/*rn/*’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e126e2850>)])]This step submits a BigQuery load job that will load ORC file partitions from my_table.orc into MY_DATASET.MY_TABLE. Note this is the path that was written to on the previous step. STEP 3:code_block[StructValue([(u’code’, u’//STEP03 EXEC BQSHrn//QUERY DD DSN=PATH.TO.QUERY,DISP=SHRrn//STDIN DD *rnbq query –project_id=myprojectrn/*’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e126e2690>)])]This step submits a BigQuery Query Job to execute SQL DML read from the QUERY DD (a format FB file with LRECL 80). Typically the query will be a MERGE or SELECT INTO DML statement that results in transformation of a BigQuery table. Note: the connector will log job metrics but will not write query results to a file.Running outside of the mainframe to save MIPSWhen scheduling production-level load with many large transfers, processor usage may become a concern. The Mainframe Connector executes within a JVM process and thus should utilize zIIP processors by default, but if capacity is exhausted, usage may spill over to general purpose processors. Because transcoding z/OS records and writing ORC file partitions requires a non-negligible amount of processing, the Mainframe Connector includes a gRPC server designed to handle compute-intensive operations on a cloud server; the process running on z/OS only needs to upload the dataset to Cloud Storage and make an RPC call. Transitioning between local and remote execution requires only an environment variable change. Detailed information on this functionality can be found here. AcknowledgementsThanks to those who tested, debugged, maintained and enhanced the tool: Timothy Manuel, Suresh Balakrishnan,Viktor Fedinchuk,Pavlo KravetsRelated Article30 ways to leave your data center: key migration guides, in one placeEssential guides for all the workloads your business is considering migrating to the public cloud.Read Article
Quelle: Google Cloud Platform
Over the past couple of years, businesses across every industry have faced unexpected challenges in keeping their enterprise IT systems safe, secure, and available to users. Many have experienced sudden spikes or drops in demand for their products and services and most are now operating in a hybrid work environment. In such changing conditions, with business requirements and expectations constantly evolving, it is a best practice to periodically revisit your IT system service-level objectives (SLOs) and agreements (SLAs) and ensure they are still aligned with your business needs.Adapting to these new requirements can be especially complex for companies that run their SAP enterprise applications in on-premises environments. These organizations are often already struggling with running business-critical SAP instances as they can be complex and costly to maintain. They know how much their users depend on these systems and how disruptive dealing with unplanned outages can be, so they see the on-premises setup—backed up with major investments in high availability (HA) systems and infrastructure—as the best way to ensure the security and availability of these essential applications. IT organizations charged with running on-premises SAP landscapes, in many cases, must also manage a growing number of other business-critical applications—all while under pressure to do more with less.For many organizations, this is an unsustainable approach. In fact, according to a SIOS survey looking at trends in HA solutions, companies at the time were already struggling to hold the line with on-premises application availability:95% of the companies surveyed reported at least occasional failures in the HA services that support their applications.98% reported regular or occasional application performance issues, and 71% reported them once or more per monthWhen HA application issues occurred, companies surveyed spent 3–5 hours, on average, to identify and fix the problem.Things aren’t getting easier for these companies. Today’s IT landscape is dominated by risk, uncertainty, and the prospect of belt-tightening down the road. At the same time, it’s especially important now to keep your SAP applications—the software at the heart of your company—secure, productive, and available for the business.At Google Cloud, we’ve put a lot of thought into solving the challenges around high availability for SAP environments. We recognize this as a potential make-or-break issue for customers and we prioritize giving them a solution: a reliable, scalable, and cost-effective SAP environment, built on a cloud platform designed to deliver high availability and performance.When you use Google Cloud, you get many services that are designed to be fault tolerant or highly available. The concepts are similar, but understanding the difference can save you time and effort when designing your architecture.We consider fault tolerant components as fully redundant mechanisms, where any failure of these components is designed to be seamless to the system availability. It includes components like storage (Google Cloud Storage, Persistent Disks) and network (Google Network, Cloud DNS, Cloud Load Balancer). Highly available services, however, will have an automated recovery mechanism of all the relevant architectural components, also known as single points of failure, which minimizes the recovery time objective (RTO) and recovery point objective (RPO). It usually involves replicating components and automating the failover process between them.Four levels of SAP high availability on Google CloudUnderstanding how to give SAP customers the right availability solution starts with recognizing that each customer will have different target availability SLAs and those targets will vary depending on their business needs, budgets, SAP application use cases, and other factors. Let’s look at the SAP high availability landscape infrastructure, operating system and application availability components, and what you would need to consider for your SAP system’s overall availability strategy.Level 1: InfrastructureMany customers find that simply moving their SAP system from on-premises to Google Cloud can increase their system’s uptime, because they are able to leverage the platform’s embedded security, networking, compute and storage features which are highly available by default.Compute ServicesFor compute services, Google Cloud Compute Engine has three built-in capabilities that are especially important and can reduce or even eliminate disruptions to applications due to hardware failures:Live Migration: When a customer’s VM instances are running on a host system that needs scheduled maintenance, Live Migration moves the VM instance from one host to another, without triggering a restart or disrupting the application. This is a built-in feature that every Google Cloud user gets at no additional cost. It works seamlessly and automatically, no matter how large or complex a user’s workloads happen to be. Google Cloud conducts hardware maintenance and applies hypervisor security patches and updates globally and seamlessly without ever having to inform a single customer to restart their VM as our maintenance does not impact your running applications, thanks to the power of Live Migration. Memory Poisoning Recovery (MPR): Even the highest-quality hardware infrastructure could break at some point and memory errors are the most common type of hardware malfunction (see Google Cloud’s study on memory reliability). Modern CPU architectures have native features like Error Correction Code (ECC), which enable hosts to recover from correctable errors. However, uncorrectable errors will crash and restart all VMs in the host, resulting in unexpected downtime. If you have HANA databases, you also have to account for the time it takes to load the data into memory. In that case, a host crash can cause hours of business critical service downtime, depending on the database size.Google Cloud developed a solution which integrates the CPU native error handling capabilities, SAP HANA and Google Cloud capabilities to reduce disruptions and downtime due to memory errors. With MPR, the uncorrectable memory error is detected and isolated until the VMs can be live migrated off of the affected host.If the uncorrectable error is found on a VM hosting SAP HANA, Google Cloud MPR will send a signal to SAP HANA, with Fast Restart enabled, to reload only the affected memory from disk, thus resolving the issue without downtime in most situations. Subsequently, all VMs on the affected host will be live migrated to a healthy host to prevent any downtime or disruption to customer’s applications running on those VMs.Automatic Restart: In the rare case when an unplanned shutdown cannot be prevented, this feature swings into action and automatically restarts the VM instance on a different host. When necessary, it calls up a user-defined startup script to ensure that the application running on top of the VM restarts at the same time. The goal is to ensure the fastest possible recovery from an unplanned shutdown, while keeping the process as simple and reliable as possible for users. These services aim to increase the uptime of the single node, but highly critical workloads need resilience against compute related failures, including a complete zone outage. To cover this, Google Cloud Compute Engine offers a monthly uptime percentage SLAof 99.99% for instances distributed across multiple zones. Network File System storage (NFS)Another important component of highly available SAP infrastructure is the Network File System storage (NFS), which is used for SAP shared files, such as the interfaces directory and transport management. Google Cloud offers several file sharing solutions, like its first party Filestore Enterprise and third party solutions, such as NetApp CVS-Performance, both offering a 99.99% availability SLA. (if you need more information comparing NFS solutions on Google Cloud, please check the documentation available).Level 2: Operating SystemA critical part of the failover mechanism is clustering compute components at operating system level. It allows for fast component failure detection and triggers the failover procedures, minimizing the application downtime. Clustering at the OS level on Google Cloud, is very similar to the on-prem approach to clustering, with a couple improved features. Both SUSE Enterprise Linux (SLES) and Red Hat Enterprise Linux (RHEL) implement Pacemaker as a clustering resource manager and provide cluster agents designed for Google Cloud, which allows it to seamlessly manage functions and features like STONITH fencing, VIP routes and storage actions. When deploying OS clusters on Google Cloud, customers can avail themselves of the HA/DR provider hooks that allow SAP HANA to send out notifications to ensure a successful failover without data loss. For more information, see the detailed documentation for configuring HA clusters on RHEL and on SLES in our SAP high availability deployment guides.Windows-based workloads use Microsoft failover clustering technology and have special features on Google Cloud to enable and configure the cluster. Here you can find detailed documentation.Level 3: DatabaseEvery SAP environment depends on a central database system to store and manage business-critical data. Any SAP high availability solution must consider how to maintain the availability and integrity of this database layer. In addition, SAP systems support a variety of database systems—many of which employ different mechanisms to achieve high availability performance. By supporting and documenting the use of HA architectures for SAP HANA, MaxDB, SAP ASE, IBM Db2, Microsoft SQL Server and Oracle workloads (using our Bare Metal Solution, you can use HA certified hardware and even install Oracle RAC solution). Google Cloud gives customers the freedom to decide how to balance the costs and benefits of HA for their SAP databases.SAP HANA System Replication (HSR) is one of the most important application-native technologies for ensuring HA for any SAP HANA system. It works by replicating data continuously from a primary system to one or more secondary systems, and that data can be preloaded into memory to allow for a rapid failover if there’s a disaster.Google Cloud supports and complements HSR by supporting the use of synchronous replication for SAP instances that reside in any zone within the same region. That means users can place their primary and secondary instances in different zones to keep them protected against a single-point-of-failure in either zone.Other database systems like SAP ASE or IBM Db2 offer similar functionalities, which are also supported to run on Google Cloud infrastructure. The low network latency between zones in the same region coupled with our tools for automated deployments give companies the choice to run a variety of database HA options, tailored to their current business needs. Review our latest documentation for a current list of supported database systems and reference architectures.Level 4: Application serverSAP’s NetWeaver architecture helps users avoid app-server bottlenecks that can threaten HA uptime requirements. Google Cloud takes that advantage and runs with it by giving customers the high availability compute and networking capabilities they need to protect against the loss of data through synchronization and to get the most reliability and performance from SAP NetWeaver. It uses one OS level cluster (SLES or RHEL), with Pacemaker cluster resource manager and STONITH fencing for the ABAP SAP Central Services (ASCS) and Enqueue Replication Server (ERS), each with is own internal load balancer (ILB) for virtual IP. Detailed documentation for deploying and configuring HA clusters can be found for both RHEL and SLES in our NetWeaver high availability planning guides.Distributing application server instances across multiple zones of the same region provides the best protection against zonal failures while still providing great performance to the end user. Through automated deployments your IT team can quickly react to changes in demand and spin up additional instances in moments to keep the SAP system up and running, even during peak situations. Other ways Google Cloud supports high availability SAP systemsThere are many other ways Google Cloud can help maximize SAP application uptime, even in the most challenging circumstances. Consider a few examples, and keep in mind how tough it can be for enterprises, even larger ones, to implement similar capabilities at an affordable cost:Geographic distribution and redundancy. Google Cloud’s global footprint currently includes 30 regions, divided into 91 zones and over 140 points of presence. By distributing key Google Cloud services across multiple zones in a region, most SAP users can achieve their availability goals without sacrificing performance or affordability. Powerful and versatile load-balancing capabilities. For many enterprises, load balancing and distribution is another key to maintaining the availability of their SAP applications. Google Cloud meets this need with a range ofload-balancing options, including global load balancing that can direct traffic to a healthy region closest to users. Google Cloud Load Balancing reacts instantaneously to changes in users, traffic, network, backend health, and other related conditions. And, as a software-defined service, it avoids the scalability and management issues many enterprises encounter with physical load-balancing infrastructure. Another important load balancer service for highly available SAP systems is the Internal Load Balancer, which allows you to automate the Virtual IP (VIP) implementation between the primary and secondary systems.Tools that keep developers focused and productive. Google Cloud’sserverless platform includes managed compute and database products that offer built-in redundancy and load balancing. It allows a company’s SAP development teams to deploy side-by-side extensions to the SAP systems without worrying about the underlying infrastructure. By using Apigee API Management, companies can provide a scalable interface to their SAP systems for these extensions, which protects the backend system from traffic peaks and malicious attacks. Google Cloud alsosupports CI/CD through native tools and integrations with popular open source technologies, giving modern DevOps organizations the tools they need to deliver software faster and more securely. Moreover, Google Cloud’s Cortex Framework provides accelerators and best practices to reduce risk, complexity and costs when innovating alongside SAP and unlocks the best of Google Cloud’s Analytics in a seamless setup that brings more value to the business.Flexible, full-stack monitoring. Google Cloud Monitoring gives enterprises deep visibility into the performance, uptime, and overall health of their SAP environments. It collects metrics, events, and metadata from Google Cloud, Amazon Web Services, hosted uptime probes, application instrumentation, and even application components such as Cassandra, Nginx, Apache Web Server, Elasticsearch, and many others. With a custom monitoring agent for SAP HANA and the Cloud Operation’s Ops Agent, Cloud Monitoring uses this data to power flexible dashboards and rich visualization tools, which helps SAP teams identify and fix emerging issues before they affect your business.Explore your HA optionsWe’ve only scratched the surface when it comes to understanding the many ways Google Cloud supports and extends HA for SAP instances. For an even deeper dive, our documentation goes into more technical detail on how you can set up a high availability architecture for SAP landscapes using Google Cloud services.Related ArticleLearn how to tackle supply chain disruptions with SAP IBP and Google CloudSAP IBP now integrated with Google Cloud for faster, more accurate forecasting to navigate challenges with supply chain disruptionsRead Article
Quelle: Google Cloud Platform