Intermot 2022: Horwin zeigt Elektro-Roller SK1 und Motorrad HT5
Horwin hat auf der Messe Intermot 2022 mit den Modellen SK1 und HT5 seine Produktpalette von Elektromotorrädern erweitert. (Elektromotorrad, Technologie)
Quelle: Golem

Horwin hat auf der Messe Intermot 2022 mit den Modellen SK1 und HT5 seine Produktpalette von Elektromotorrädern erweitert. (Elektromotorrad, Technologie)
Quelle: Golem

Die Rolle des BSI soll laut der Cybersicherheitsagenda gestärkt werden. Ob dafür auch Personal aufgestockt werden soll, ist noch nicht klar. Ein Bericht von Ulrich Hottelet (BSI, Internet)
Quelle: Golem

Netzwerke gab es schon immer, das Internet forciert sie. Die Dokumentation Networld sieht sich diese Netzwerke aus unterschiedlichsten Perspektiven an. Von Peter Osteried (Audio/Video, Internet)
Quelle: Golem
Have you used Patterns on your site yet?
These prebuilt, customizable templates combine professionally-designed blocks for specific uses like stylized quotes, contact page layouts, and product listings. But that’s just the beginning. All told, we have more than 260 Patterns you can insert into your pages and posts at the press of a button.
If you’ve never used Patterns before, they’re like any other site element: Access them by hitting the “+” button at the top left of the page or post you’re working on, then selecting the “Patterns” tab. You can also click on the “Explore” button to bring up our entire library of Patterns, organized by category.
Think of them as sophisticated slices of web design for your posts and pages. You can drop them in as-is, or customize them to your liking. Even better, we’re adding more all the time.
Here are just a few of the most recent arrivals to the Pattern library.
Headers and Footers
One of the most common questions our Happiness Engineers hear from users is how to customize a site’s header and footer areas. One way to easily and efficiently do that? Patterns. Note: Be sure to add these patterns to your header and footer template parts, which are found in the Site Editor (Appearance → Editor). A single update or change here will apply across all pages.
Find these and more in the “Header” and “Footer” categories.
Link in Bio Patterns
We’ve added a number of stunning Patterns for your link-in-bio pages and sites. Pick one, customize as desired, add your links, and you’ve got a brand new way to let your readers know what’s new.
Explore All of Our Patterns!
Even if you don’t have a specific need in mind, take a look around the full Patterns library. Galleries, contact pages, subscribe boxes, quotes: with so many options, you’re sure to find something that adds a fresh new wrinkle to your site.
Patterns can be an incredibly useful resource for your design toolbox. Customize, experiment, and turn inspiration into eye-catching reality.
If you need help with Patterns, check out our more detailed guide.
And be sure to let us know in the comments how you’ve used Patterns on your site and any ideas you have for new ones. We’re always working on more — so stay tuned!
Quelle: RedHat Stack
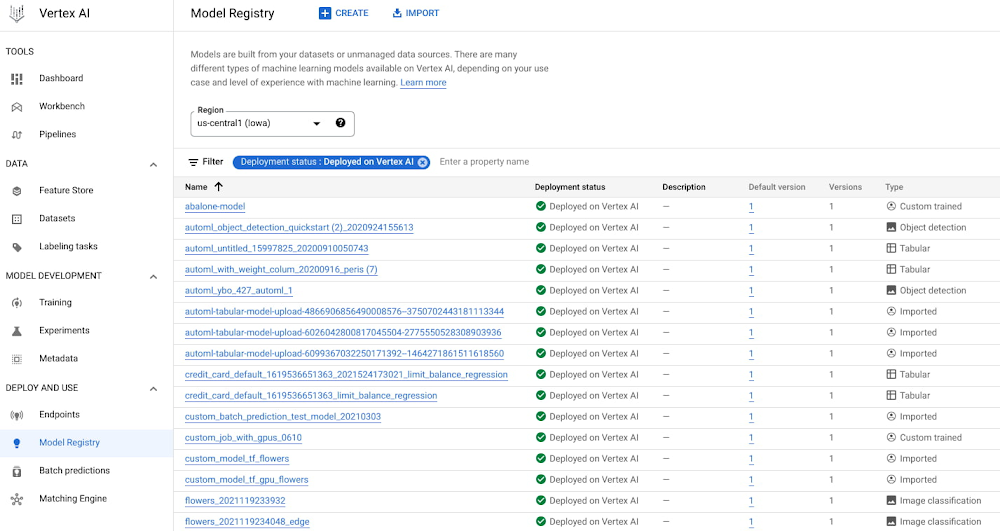
Machine learning (ML) is iterative in nature — model improvement is a necessity to drive the best business outcomes. Yet, with the proliferation of model artifacts, it can be difficult to ensure that only the best models make it into production.Data science teams may get access to new training data, expand the scope of use cases, implement better model architectures, or simply make adjustments as the world around your models is constantly changing. All of these scenarios require building new versions of models to be released into production. And with the addition of new versions, it matters to be able to manage, compare, and organize them. Moreover, without a central place to manage your models at scale, it’s difficult to govern model deployment with appropriate gates on release and maintenance according to compliance to industry standards and regulations. To address these challenges, today we are excited to announce the Global Availability (GA) launch of the Vertex AI Model Registry.Fig. 1 – Vertex AI Model Registry – Landing pageWith the Vertex AI Model Registry, you have a central place to manage and govern the deployment of all of your models, including BigQuery, AutoML and custom models. You can use the Vertex AI Model Registry at no charge. The only cost that occurs when using the registry is if you deploy any of your models to endpoints or if you run a batch prediction.Vertex AI Model Registry offers key benefits to build a streamlined MLOps process: Version control and ML metadata tracking to guarantee reproducibility across different model versions over time. Integrated model evaluation to validate and understand new models using evaluation and explainability metrics. Simplified model validation to enhance model release.Easy deploymentto streamline models to production. Unified model reporting to ensure model performanceVersion control and ML metadata tracking to guarantee model reproducibilityVertex AI Model Registry allows you to simplify model versioning and track all model metadata to guarantee reproducibility over time. With the Vertex AI SDK, you can register custom models, all AutoML models (text, tabular, image, and video), and BQML models. You can also register models that you trained outside of Vertex AI by importing them to the registry.Fig. 2 – Vertex AI Model Registry – Versioning viewIn Vertex AI Model Registry, you can organize, label, evaluate, and version models. The registry gives you a wealth of model information at your fingertips, such as model version description, model type, and model deployment status. You can also associate additional information such as the team who built a particular version or the application the model is serving.In the end, you can get a single picture of your models and all of their versions using the Model Registry console. You can drill down and get all the information about a specific model and its associated versions so you can guarantee reproducibility across different model versions over time. Integrated model evaluation to ensure model quality Thanks to the integration with the new Vertex AI Model Evaluation service, you can now validate and understand your model versions using evaluation and explainability metrics. This integration allows you to quickly identify the best model version and audit the quality of the model before deploying it in production. For each model version, the Vertex AI Model Registry console shows classification, regression, and forecasting metrics depending on the type of model.Fig. 3 – Vertex AI Model Registry – Model Evaluation viewSimplified model validation to improve model release. In an MLOps environment, automation is critical for ensuring that the correct model version is used consistently across all downstream systems. As you scale your deployments and expand the scope of your use cases, your team will need solid infrastructure for flagging that a particular model version is ready for production.In Vertex AI Model Registry, aliases are uniquely named references to a specific model version. When you register a new model, the first version automatically gets assigned the default alias. Then you can create and assign custom aliases to your models depending on how you decide to organize your model lifecycle. An example of model alias usage would be assigning the stage of the reviewing process (not started, in progress, under review, approved) or the status of the model life cycle (experimental, staging, or production).Fig. 4 – Vertex AI Model Registry – Aliases viewIn this way, the Model Registry simplifies the entire model validation process by making it easy for downstream services, such as model deployment pipelines or model serving infrastructure, to automatically fetch the right model.Easy deployment to streamline models to productionAfter a model has been trained, registered, and validated, the model is ready to be deployed. With Vertex AI Model Registry, you can easily productionalize all of your models (BigQuery models included) with point-and-click model deployment thanks to the integration with Vertex AI Endpoints and Vertex AI Batch Predictions. In the Vertex AI Model Registry console, you select the approved model version, you define the endpoint and you specify some model deployment and model monitoring settings. Then you deploy the model. After the model has been successfully deployed, you can see that the model status is automatically updated in the models view and it is ready to generate both online and batch predictions.Fig. 5 – Vertex AI Model Registry – Model DeploymentUnified model reporting to ensure model performanceA deployed model keeps performing if the input data remains similar to the training data. But realistically, data changes over time and the model performance degrades. This is why model retraining is so important. Typically, models are retrained at regular intervals, but ideally models should be continuously evaluated with new data before making any retraining decisions. With the integration of Vertex AI Model Evaluation, now in preview, after you deploy your model, you define a test dataset and an evaluation configuration as inputs. In turn, it returns model performance and fairness metrics directly in the Vertex AI Model Registry console. Looking at those metrics you can determine when the model needs to be retrained based on the data you record in production. These are important capabilities for model governance, ensuring that only the freshest, most accurate models are used to drive your business forward.Fig. 6 – Vertex AI Model Registry – Model Evaluation comparison viewConclusion The Vertex AI Model Registry is a step forward for model management in Vertex AI. It provides a seamless user interface which shows you all of the models that matter most to you free of charge, and at-a-glance metadata to help you make business decisions.In addition to a central repository where you can manage the lifecycle of your ML models, it introduces new ways to work with models you’ve trained outside of Vertex AI, like your BQML models. It also provides model comparison functionality via the integration with our Model Evaluation service, which makes it easy to ensure that only the best and freshest models are deployed. Additionally, this one stop view improves governance and communication across all stakeholders involved in the model training and deployment process. With all these benefits of the Vertex AI Model Registry, you can confidently move your best models to production faster. Want to learn more?To learn more about the Vertex AI Model Registry, please visit our other resources:Vertex AI Model Registry DocumentationBQML Model Registry Documentation Vertex AI Model Evaluation Documentation Want to dive right in? Check out some of our Notebooks, where you can get hands-on practice: Get started with Vertex AI Model RegistryGet started with Model Governance with Vertex AI Model RegistryDeploy BigQuery ML Model on Vertex AI Model Registry and Make PredictionsGet started with Vertex AI Model EvaluationSpecial thanks to Ethan Bao, Shangjie Chen, Marton Balint, Phani Kolli, Andrew Ferlitch, Katie O’Leary, and all the Vertex AI Model Registry team for support and great feedback.Related ArticleRead Article
Quelle: Google Cloud Platform

Editor’s note: The post is part of a series highlighting our awesome partners, and their solutions, that are Built with BigQuery.What are Customer Data Platforms (CDPs) and why do we need them?Today, customers utilize a wide array of devices when interacting with a brand. As an example, think about the last time you bought a shirt. You may start with a search on your phone as you take the subway to work. During that 20 minute ride, you narrow down the type of shirt . Later, as you take your lunch break, you spend a few more minutes refining your search on your work laptop and you are able to find two shirt models of interest. Pressed for time, you add both to your shopping cart at an online retailer to review at a later point. Finally, after you arrive back home and as you are checking your physical mail, you stumble across a sales advertisement for the type of shirt that you are looking for, available at your local brick and mortar store. The next day you visit that store during your lunch break and purchase the shirt. Many marketers face the challenge of creating a consistent 360 customer view that captures the customer lifecycle, as illustrated in the example above – including their online/offline journey, interacting with multiple data points across multiple data sources.The evolution of managing customer data reached a turning point in the late 90’s with CRM software that sought to match current and potential customers with their interactions. Later as a backbone of data-driven marketing, Data Management Platforms (DMPs) expanded the reach of data management to include second and third party datasets including anonymous IDs. A Customer Data Platform combines these two types of systems, creating a unified, persistent customer view across channels (mobile, web etc) that provide data visibility and granularity at individual level.A new approach to empowering marketing heroesTinyclues is a company that specializes in empowering marketers to drive sustainable engagement from their customers and generate additional revenue, without damaging customer equity. The company was founded in 2010 on a simple hunch: B2C marketing databases contain sufficient amounts of implicit information (data unrelated to explicit actions) to transform the way marketers interact with customers, and a new class of algorithms based on Deep Learning (sophisticated machine learning that mimics the way humans learn) holds the power to unlock this data’s potential. Where other players in the space have historically relied – and continue to rely – on a handful of explicit past behaviors and more than a handful of assumptions, Tinyclues’ predictive engine uses all of the customer data that marketers have available in order to formulate deeply precise models, down even to the SKU level. Tinyclues’ algorithms are designed to detect changes in consumption patterns in real-time, and adapt predictions accordingly.This technology allows marketers to find precisely the right audiences for any offer during any timeframe, increasing engagement with those offers and, ultimately, revenue; additionally, marketers are able to increase campaign volume while decreasing customer fatigue and opt-outs, knowing that audiences are receiving only the most relevant messages. Tinyclues’ technology also reduces time spent building and planning campaigns by upwards of 80%, as valuable internal resources can be diverted away from manual audience-building.Google Cloud’s Data Platform, spearheaded by BigQuery, provides a serverless, highly scalable, and cost-effective foundation to build this next generation of CDPs. Tinyclues Architecture:To enable this scalable solution for clients, Tinyclues receives purchase and interaction logs from clients in addition to product and user tables. In most cases, this data is already in the client’s BigQuery instance, in which case they can be easily shared with Tinyclues utilizing BigQuery authorized views. In cases where the data is not in BigQuery, flat files are sent to Tinyclues via GCS and are ingested in the client’s data set via a lightweight Cloud Function. The orchestration of all pipelines is implemented via Cloud Composer (Google’s managed Airflow). The transformation of data is accomplished by utilizing simple select statements in the Data Built Tool (DBT), which is wrapped inside an airflow DAG that powers all data normalization and transformations. There are several other DAGs to fulfill more functionalities, including: Indexing the product catalog on Elastic Cloud (Elasticsearch managed service) on GCP to provide auto-complete search capabilities to TCs clients as shown below:The export of Tinyclues-powered audiences to the clients’ activation channels, whether they are using SFMC, Braze, Adobe, GMP, or Meta.Tinyclues AI/ML Pipeline powered by Google Vertex AITCs ML Training pipelines are used to train models that calculate propensity scores. They are composed using Airflow DAGs, powered by Tensorflow & Vertex AI Pipelines. BigQuery is used natively, without data movement, to perform as much feature engineering as possible in-place. TC uses the TFX library to run ML Pipelines in Vertex AI. Building on top of Tensorflow as their main deep learning framework of choice due to its maturity, open source platform, scalability and support for complex data structures (Ragged and Sparse Tensors). Below is a partial example of TC’s Vertex AI Pipeline graph, illustrating the workflow steps in the training pipeline. This pipeline allows for the modularization & standardization of functionality into easily manageable building blocks. These blocks are composed of TFX components (TC reuses most of the standard components in addition to customizing some such as a proprietary implementation of the Evaluator to compute both ML Metrics (which is part of the standard implementation) but also more Business Metrics like Overlap of clickers etc. The individual components/steps are chained with DSL to form a pipeline that is modular and easily orchestrated or updated as needed.With the trained Tensorflow models available in GCS, TCs exposes these in BigQuery ML (BQML) to enable their clients to score millions of users for their propensity to buy X or Y within minutes. This would not be possible without the power of BigQuery and also frees TC from previously experienced scalability issues.As an illustration, TC has the need to score thousands of topics among millions of users. This used to take north of 20 hours on their previous stack, and now takes less than 20 minutes thanks to the optimization work that TC has implemented in their custom algorithm and the sheer power of BQ to scale to any workload accordingly. Data Gravity: Breaking the Paradigm – Bringing the Model to your DataBQML enables TC to call pre-trained TensorFlow models within an SQL environment, thus avoiding exporting data in and out of BQ using already provisioned BQ serverless processing power. Using BQML removes the layers between the models and the data warehouse and allows them to express the entire inference pipe as a number of SQL requests. TC no longer has to export data to load it into their models. Instead, they are bringing their models to the data.Avoiding the export of data in and out of BQ and the serverless provisioning and start of machines saves significant time. As an example, exporting an 11M lines campaign for a large client previously took 15 min or more to process. Deployed on BQML it now takes minutes with more than half of the processing time attributed to network transfers to our client system. Inference times in BQML compared to TCs legacy stack:As can be seen, using this approach enabled by BQML, the reduction in the number of steps leads to a 50% decrease in overall inference time, improving upon each step of the prediction.The Proof is in the puddingTinyclues has consistently delivered on its promises of increased autonomy for CRM teams, rapid audience building, superior performance against in-house segmentation, identification of untapped messaging and revenue opportunities, fatigue management, and more, working with partners like Tiffany & Co, Rakuten, and Samsung, among many others.ConclusionGoogle’s data cloud provides a complete platform for building data-driven applications like the headless CDP solution developed by Tinyclues — from simplified data ingestion, processing, and storage to powerful analytics, AI, ML, and data sharing capabilities — all integrated with the open, secure, and sustainable Google Cloud platform. With a diverse partner ecosystem, open-source tools, and APIs, Google Cloud can provide technology companies the portability and differentiators they need to serve the next generation of marketing customers. To learn more about Tinyclues on Google Cloud, visit Tinyclues. Click here to learn more about Google Cloud’s Built with BigQuery initiative. We thank the many Google Cloud team members who contributed to this ongoing data platform collaboration and review, especially Dr. Ali Arsanjani in Partner Engineering.Related ArticleRead Article
Quelle: Google Cloud Platform

A comprehensive API security strategy requires protection from fraud and abuse. To better protect our publicly-facing APIs from malicious software that engages in abusive activities, we can deploy CAPTCHAs to disrupt abuse patterns. Developers can prevent attacks, reduce their API security surface area, and minimize disruption to users by implementing Google Cloud’s reCAPTCHA Enterprise and Apigee X solutions. As Google Cloud’s API management platform, Apigee X can help protect APIs using a reverse-proxy approach to HTTP requests and responses. One important feature of Apigee X is the ability to include a reCAPTCHA Enterprise challenge in the authentication (AuthN) stage of the request. This post shows how to provision a reCAPTCHA proxy flow to protect your APIs. Complete code samples are available in this Github repo.When and why to use Apigee X for implementing CAPTCHAsThe initial way to use reCAPTCHA Enterprise as part of a Web Application and API Protection (WAAP) solution is through Cloud Armor. For developers who want a purely API-based solution, Apigee X allows developers to define the reCAPTCHA process as a set of Apigee X proxy flows. As a dedicated solution, it moves as much API security code as possible into Apigee. This method can also make code maintenance easier and can allow API business rules to be managed in code. The reCAPTCHA process can be included directly in Apigee proxies, either individually or as shared flows. This code can then be added to the same source control as all the Apigee proxy code, in line with the API business rules.Let’s first review a few implementations of reCAPTCHA Enterprise, and then contrast those with an Apigee X implementation example to see which might be best for you.An introduction to reCAPTCHA EnterpriseA reCAPTCHA challenge page can redirect incoming HTTP requests to reCAPTCHA Enterprise, which can help stop possible malicious attacks. When reCAPTCHA Enterprise is integrated with Cloud Armor, and the Challenge Page option is selected, a reCAPTCHA will trigger when the policy rule of Cloud Armor matches the incoming URL/traffic pattern.To avoid CAPTCHA fatigue (mouse-click fatigue due to too many CAPTCHA challenges), developers should consider using reCAPTCHA session-tokens, which we explain in more detail below. A challenge page is most useful for dealing with a bot making repeated programmatic HTTP requests. The challenge page redirect and possible reCAPTCHA challenge can stop malicious bots. However, the challenge page can also interrupt a legitimate user’s activity — a reCAPTCHA challenge page is less desirable for a well-intended human user.For more details, please check out the reCAPTCHA challenge page documentation.To protect important user interactions, reCAPTCHA Enterprise uses an object called an action-token. These can help protect human users and their legitimate interactions, such as shopping cart checkouts or sensitive knowledge base requests that you want to safeguard.A deeper review of reCAPTCHA Enterprise action tokens can be found in the reCAPTCHA action-tokens documentation.As an alternative to action-tokens, session-tokens protect the whole user session on the site’s domain. This can help developers reuse an existing reCAPTCHA Enterprise assessment, which is analogous to a session key, but for authentication not encryption. It is recommended to use a reCAPTCHA session-token on all the web pages of your site. This enables reCAPTCHA Enterprise to secure your entire site and recognize deviations in human browsing patterns, such as a bot crawling your site.For more details, please check out the reCAPTCHA session-tokens documentation.Using Apigee X and reCAPTCHA EnterpriseAll of the above can also be accomplished in Apigee X, without the need for Cloud Armor. Code for an Apigee X flow that initiates a reCAPTCHA Enterprise challenge is below, and is also available in our Github repo file SC-AccessReCaptchaEnterprise.xml.code_block[StructValue([(u’code’, u'<ServiceCallout name=”SC-AccessReCaptchaEnterprise”>rn <Request>rn <Set>rn <Payload contentType=”application/json”>{rn “event”: {rn “token”: “{flow.recaptcha.token}”,rn “siteKey”: “{flow.recaptcha.sitekey}”rn }rn}</Payload>rn <Verb>POST</Verb>rn </Set>rn </Request>rn <Response>recaptchaAssessmentResponse</Response>rn <HTTPTargetConnection>rn <Authentication>rn <GoogleAccessToken>rn <Scopes>rn <Scope>https://www.googleapis.com/auth/cloud-platform</Scope>rn </Scopes>rn </GoogleAccessToken>rn </Authentication>rn <URL>https://recaptchaenterprise.googleapis.com/v1/projects/{flow.recaptcha.gcp-projectid}/assessments</URL>rn </HTTPTargetConnection>rn</ServiceCallout>’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e723ce0a310>)])]The most important line is the initiation of the reCAPTCHA handshake (shown in the above diagrams), with a POST request. The POST request includes both the reCAPTCHA token (either action-token or session-token, discussed above) and the reCAPTCHA sitekey (how reCAPTCHA Enterprise protects your API endpoint).code_block[StructValue([(u’code’, u'<Request>rn <Set>rn <Payload contentType=”application/json”>{rn “event”: {rn “token”: “{flow.recaptcha.token}”,rn “siteKey”: “{flow.recaptcha.sitekey}”rn }rn}</Payload>rn <Verb>POST</Verb>rn </Set>rn </Request>’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e722ca98610>)])]Here is an explanation of all the proxy definitions included in the Github repo. A reCAPTCHA token is silently and periodically retrieved by a client app and transmitted to an Apigee runtime when an API is invoked.The shared flow configuration in this example is able to get a reCAPTCHA token validation status and a risk score from the Google reCAPTCHA Enterprise assessment endpoint. The sf-recaptcha-enterprise-v1 Apigee X shared flow gets a reCAPTCHA token validation status and a risk score from the Google reCAPTCHA Enterprise assessment endpoint. The risk score is a decimal value between 0.0 and 1.0.The score 1.0 indicates that the interaction poses low risk and is very likely legitimate, whereas 0.0 indicates that the interaction poses high risk and might be fraudulent. Between both extremes, the shared flow’s processing decides if an API invocation must be rejected or not. For the purpose of this reference, we consider a minimum score of 0.6: This value is configurable and can be set to a higher or lower value depending on the risk profile of the client application.The pipeline script deploys a shared flow (sf-recaptcha-enterprise-v1) on Apigee X, containing the full configuration of the reCAPTCHA Enterprise reference as well as the following artifacts:recaptcha-data-proxy-v1: a data proxy, which calls the reCAPTCHA Enterprise shared flow. The target endpoint of this proxy is httpbin.orgrecaptcha-deliver-token-v1: an API proxy used to deliver an HTML page that includes a valid reCAPTCHA token (cf. Option 2 above). This proxy is not intended to be used in production but only during test phases.The reCAPTCHA Enterprise API productA developer (Jane Doe)app-recaptcha-enterprise: a single developer app when Option 1 has been selected2 developer apps with real app credentials and reCAPTCHA Enterprise sitekeys when Option 2 has been selected:app-recaptcha-enterprise-always0App-recaptcha-enterprise-always1Google Cloud’s Web App and API Protection (WAAP) solutionThis implementation is a part of Google Cloud’s WAAP solution. Google’s WAAP security solution stack is a comprehensive solution which is an integration of web application firewall (WAF), DDoS prevention, bot mitigation, content delivery network, Zero Trust, and API protection. The Google Cloud WAAP solution consists of Cloud Armor (for DDoS and web app defense), reCAPTACHA Enterprise (for bot defense) and Apigee (for API defense). This solution is a set of tools and controls designed to protect web applications, APIs, and associated assets. Learn more about the WAAP solution here. Google’s WAAP Security solution is driven by the following principles:Safe by default Build on tested and proven components and codeDetect risky functionalityNew code should be reviewed Bypassing safe patterns should also be justified High-risk activities should be scrutinized Automate If you do it more than once, automate What’s nextGive it a try and test out the reCAPTCHA Enterprise Apigee proxy flow code for yourself. An existing reCAPTCHA token and sitekey are required so please acquire those first. When you are ready, you can explore all of Apigee X’s security features in the following documentation: Securing a proxy and Overview of Advanced API Security.Related ArticleRead Article
Quelle: Google Cloud Platform
Containers. Serverless. CI/CD. For forward-looking developers, Google Cloud is practically synonymous with the latest trends in application development. With Google Cloud Next starting on October 11, here are a few must-watch developer sessions to add to your playlist:1. BLD106What’s next for application developersStart your foray into Google Cloud application development news here, where Tom De Leo, Director, Product Management, Platform Developer Tools, will take you through all the new application developer services and features that we are announcing at Next ‘22. 2. BLD201Building a serverless event-driven web app in under 10 minsLed by Google Cloud Developer Advocate Prashanth Subrahmanyam, in this session we take a traditional monolithic use case, break it down into composable pieces, and build an end-to-end application using Google Cloud’s portfolio of serverless products.3. BLD209What’s new in cloud-native CI/CD: speed, scale, securityApplication development teams are increasingly embracing CI/CD. Join Google Cloud Product Manager David Jacobs and Software Engineer Edward Thiele to learn about new capabilities in Cloud Build, Artifact Registry, Artifact Analysis, and Google Cloud Deploy, and how they can help your teams deliver software to Cloud Run and Google Kubernetes Engine (GKE).4. BLD300What’s new in Kubernetes: Run batch and high performance computing in GKESpeaking of GKE, did you know that it’s emerged as a great place to deploy high performance computing workloads? Here, PGS Chief Enterprise Architect Louis Bailleul and Google Cloud Senior Product Manager Maciek Różacki share how PGS used GKE to replace its 260,000-core Cray supercomputers. The session will also go over recent feature launches in the data processing space for GKE and what’s coming up on the roadmap.5. BLD2055 reasons why your Java apps are better on Google CloudWhy should you run your Java workloads on Google Cloud? Simple: Java Cloud Client Libraries now support Native Image out of the box. In this session, Google Cloud Senior Product Manager Cameron Balahan and Developer Advocate Aaron Wanjala show you how to compile your Java applications ahead of time, so you can dramatically speed up your cold start times.Build your developer playlistTo explore the full catalog of breakout sessions and labs designed for application developers, check out the entire Build track in the Catalog. And don’t forget to tune into the Developer Keynote presented live from the Next Innovators Hive from Sunnyvale on Tuesday October 11 from 10:00 – 11:00 PT – and again from Bengaluru, Munich, and Tokyo. See the Innovators Hive for local playtimes. Register for Next ‘22.Related ArticleRead Article
Quelle: Google Cloud Platform
The higher energy cost and the resulting increase in the cost of doing business have led to a tighter economic outlook for most businesses around the world. This, in turn, is a major contributing factor to customers becoming more cost-conscious, leading to an increased need for optimization features in products and services. Azure Migrate’s comprehensive suite includes many features to optimize cost, while catering to your performance needs to meet service level agreements (SLAs). Agentless discovery and mapping of your entire on-premises IT estate, software inventory analysis for assessment and planning, and right-sized migration using a single portal to start, run, and track your projects, are a few cost-effective features that also contribute to ease of use. Once in Azure, the path towards greater optimization and cost savings continues through modernization to platform as a service (PaaS) and software as a service (SaaS).
Customer requirements and benefits
The customer must stay competitive, both on the technical and business fronts, to ensure continued success. Technical competency requires an agile and innovative IT platform with data analytics to provide insights that can help differentiate from the competition. It would be ideal if such an innovative platform were available at a competitive cost. Incidentally, modernizing existing IT infrastructure, applications, and data-to-PaaS/SaaS models in the cloud delivers on all these requirements, leading to a higher return on investment (ROI) for the customer.
The higher efficiency and lower cost due to the adoption of modern cloud-native architectures also lead to greater levels of flexibility and reduced vendor lock-in. Thus, setting the stage for the customer to realize greater value as they progress from IaaS to PaaS and onto SaaS models. Please download our analyst report for details on options and value due to application modernization in Azure.
Microsoft’s focus on cost optimization
During Microsoft Ignite, we are highlighting our continued commitment to cost optimization through support for SQL Server assessments, prior to migration and modernization using Azure Migrate. Customers can now perform unified, at-scale, agentless discovery and assessment of SQL Servers on Microsoft Hyper-V, bare-metal servers, and infrastructure as a service (IaaS) of other public clouds, such as AWS EC2, in addition to VMware environments. The capability will allow customers to analyze existing configurations, performance, and feature compatibility to help with right-sizing and estimating cost. It will also check on readiness and blockers for migrating to Azure SQL Managed instance, SQL Server on Azure virtual machine, and Azure SQL Database. All this information can also be presented in a single coherent report for easy consumption while reducing cost for customers.
Please see our tech community blog for more details. The blog presents a step-by-step procedure to get started, followed by details on scaling and support. Post-assessment options and more details on related topics are covered as well.
Learn more
Attend this Microsoft Ignite breakout session to learn more about how you can do more with less on Azure. For more details on other migration and modernization topics, including best-practice guidance and procedures for containers, networking and storage components, third-party tool integrations and hybrid management, please refer to the relevant blog topic in our migrate and modernize section.
Check out this FastTrack link for moving to Azure efficiently and get best practice guidance from the Azure migration and modernization center. The Azure migration and modernization program (AMMP) is now one comprehensive program for all migration and modernization needs of our customers. Learn more and join AMMP today.
Source:
Trends in Cloud Computing: 2022 State of the Cloud Report | Flexera Blog
Quelle: Azure

Among the many important reasons why telecommunication companies should be attracted to Microsoft Azure are our network and system management tools. Azure has invested many intellectual and engineering cycles in the development of a sophisticated, robust framework that manages millions of servers and several hundred thousand network elements distributed in over one hundred and forty countries around the world. We have built tools and expertise to maintain these systems, use AI to predict problem areas and solve them before they become issues, and provide transparency in the performance and efficiency of a very large and complicated system.
At Microsoft, we believe these tools and expertise can be repurposed to manage and optimize telecommunication infrastructure as well. This is because the evolving infrastructure for telecommunication operators includes elements of edge and cloud computing that lend themselves well to global management. In this article, I will describe some of the more interesting technologies that fit into the management of a cloud-based telecommunications infrastructure.
Up and running in just a few clicks
If you want to set up a 5G cellular site, there are a few key requirements. After gathering and interconnecting your hardware (servers, network switches, cables, power supplies, and other components), you then plug in your edge server machines to power and networking outlets. Each machine will be accessible via a standards-based board management controller (BMC) that usually runs a lightweight operating system, Linux, for example, to remotely manage the machine via the network.
When powered up, the BMC will obtain an IP address, most likely from a networked DHCP server. Next, an Azure VPN Gateway will be instantiated—this is a Microsoft Azure-managed service that is deployed into an Azure Virtual Network (VNet), and provides the endpoint for VPN connectivity for point-to-site VPNs, site-to-site VPNs, and Azure ExpressRoute. This gateway is the connection point into Azure from either the on-premises network (site-to-site) or the client machine (point-to-site). Using private VNet peering allows Azure to talk to the BMC on each machine.
Once this is working, the network operator can enable scripts that talk to the BMC via Azure to run automatically and can install the basic input/output system (BIOS) and proper software operating system (OS) images on the machine. Once these edge machines have an OS, a Kubernetes (K8s) cluster can be created, encompassing multiple machines by using tools such as Kubeadm. The K8s cluster is connected to Microsoft Azure Arc so that workloads can be scheduled onto the cluster using Azure APIs.
Management via Azure Arc
Microsoft Azure Arc is a set of technologies that extend Azure management to any infrastructure, enabling the deployment of Azure data services anywhere. Specifically, Azure management can be extended to Linux and Windows physical and virtual servers, and to K8s clusters so Azure data services can run on any K8s infrastructure. In this way, Azure Arc provides a unified management experience across the entire telecommunications infrastructure estate, whether it’s on-premises, in a public cloud, or in multiple public clouds.
This creates a single pane view and automation control plane of its heterogeneous environments, as well as the ability to govern and manage all these resources in a consistent way. Microsoft Azure portal, role-based access control, resource groups, search, and services like Azure Monitor and Microsoft Sentinel are also enabled. Security for next-generation networks, like the ones telecommunications operators are lighting up, is a topic I recently wrote about.
For developers, this unified framework delivers the freedom to use the tools they are familiar with while focusing more on the business logic in their applications. Microsoft Arc along with other existing and new Microsoft technologies and services forms the basis of our Azure Operator Distributed Services which will bring a carrier-grade hybrid cloud service to the market.
However, running radio access network (RAN) functions on a vanilla Arc-connected Kubernetes cluster is difficult. It requires manual and vendor-specific tuning, resource management, and monitoring capabilities, making it difficult to deploy across servers with different specs and to scale as more virtual RAN (vRAN) deployments come up. Therefore, in addition to Microsoft Azure Arc and Azure Operator Distributed Services, we have developed the Kubernetes for Operator RAN (KfOR) framework, which provides extensions that are installed on top of vanilla K8s clusters to specifically enhance the deployment, management, and monitoring of RAN workloads on the cluster. These are the essential components necessary for lighting up the automatic management and self-healing properties of next-generation telecommunication cloud networks, creating an edge platform that turns the vRAN into yet another cloud-managed application.
Kubernetes for Operator RAN (KfOR) extensions for virtualized RAN
To optimally utilize edge server resources and provide reliability, telecommunication RAN network functions (NFs) typically run in containers within a server cluster, utilizing K8s for container orchestration. Although Kubernetes allows us to take advantage of a rich ecosystem of components, there are several challenges related to running high service-level agreements, high-performance, and latency-sensitive RAN NFs in edge datacenters.
For example, RAN NFs run close to the cell tower in the far-edge, which in many cases is owned by the telecommunications operator. Performance requirements for high availability, high performance, and low latency needed by vRAN necessitate the use of single root I/O virtualization(SR-IOV) working with a data plane development kit (DPDK), programmable switches, accelerators, and custom workload lifecycle controllers. This is well beyond what standard K8s offer.
To address these challenges, we have developed KfOR, which patches this hole and enables end-to-end deployment, RAN management, monitoring, and analytics experience through Azure.
The figure shows how the various components of Azure and Kubernetes (blue) and those developed by the Azure for Operators team (green) fit together. Specifically, it shows the use of an Azure Resource Provider (RP) and an Azure Managed App, which allows the spin-up of a Management Azure Kubernetes Service (AKS) cluster on Azure. This control-plane management cluster can then utilize open source and in-house developed components to deploy and manage the edge cluster (the Azure Arc–enabled Kubernetes workload cluster).
The control plane manages both the provisioning of the bare-metal nodes on the workload cluster, as well as the Kubernetes components running on these nodes. Within the workload cluster, KfOR provides custom Kubernetes extensions to simplify the development, deployment, management, and monitoring of multi-vendor NFs. KfOR utilizes extension points available in Kubernetes such as custom controllers, DaemonSets, mutating webhooks, and custom runtime hooks. Here are some examples of its capabilities:
Container suspension capability. KfOR can create pods that have containers that start in a suspended state but can be automatically activated in the future. This capability can be used for creating "warm standbys," which means these pods can immediately replace active pods that unfortunately fail, reducing downtime from several seconds to under one. In addition, this feature can also be used to ensure that pods launch in a predetermined order by specifying pod dependencies. vRAN workloads have some pods that require another pod to have reached a particular state prior to launching.
Advanced Kubernetes networking stack. KfOR provides an advanced networking library using DPDK and a method to auto-inject this library into any pod using a sidecar container. KfOR also provides a mechanism to autoload this library ahead of the standard sockets library. This allows for code written using standard User Datagram Protocol sockets to achieve microsecond latency using DPDK underneath, without modifying a single line of code.
Cloud-native user-space eBPF codelets. Extended Berkeley packet filter (eBPF) is used to extend the capabilities of the kernel safely and efficiently without requiring changing the kernel source code or loading kernel modules. KfOR provides a mechanism to submit user-space eBPF codelets to the K8s cluster, as well as a method for insertion of these codelets by using K8s pod annotations. The codelets attach dynamically to hook points in running code in the network functions and can be used for monitoring and analytics.
Advanced scheduling and management of cluster resources. KfOR provides a K8s device plugin that allows for the scheduling and usage of isolated CPU cores as a resource separate from standard CPU cores. This enables RAN workloads to run on a K8s cluster with no manual configuration, such as pinning threads to predefined cores. KfOR also provides a custom runtime hook to isolate resources so containers cannot use CPUs, network interface controllers, or accelerators that have not been assigned to them.
With these capabilities, we have accomplished one-click deployment of RAN workloads as well as real-time workload migration and defragmentation. As a result, KfOR is able to shut off unused nodes to save energy. KfOR is also able to properly configure programmable switches that are used to route traffic from one server to the next. Furthermore, with KfOR, we can deliver fine-grain RAN analytics, which will be discussed in a future blog.
KfOR goes beyond simple automation. It turns the far-edge into a true platform that treats the vRAN as yet another app that you can install, uninstall, and swap easily with a simple click of a button. It provides APIs and abstractions that allow vRAN vendors to fine-tune their functions for real-time performance without needing to know the details of the bare metal. This is in contrast to existing vRAN solutions that even though virtualized, still treat the vRAN as an appliance, which needs to be manually tuned and is not easily portable across servers with even slightly different configurations.
Deployment of KfOR extensions is completed by using the management cluster to launch the add-ons on the workload cluster. KfOR capabilities can be used by any K8s deployment by simply adding annotations to the workload manifest.
Robust stress-free RAN management
What I have described here is how the full power of preexisting cloud management tools along with the new KfOR technology can be put together to manage, monitor, automate, and orchestrate the near-edge and far-edge machines and software deployed within the emerging telecommunications infrastructure. Once the hardware and network are available, these capabilities can light up a cell site impressively quickly, without any pain, and without requiring deep expertise. KfOR, developed specifically for virtual RAN management, has significant built-in value for our customers. It enables Azure to plug in artificial intelligence for sophisticated automation along with tried-and-true technologies needed for self-managing and self-healing networks. Overall, it creates a differentiation of our offering in the telecommunications and enterprise markets.
Learn more
Follow us for additional developments in this space and more.
Learn more about Microsoft Azure Arc and Azure Kubernetes Service (AKS).
Sign up for Microsoft Azure today.
Quelle: Azure