Aus JoynPlus+ wird Joyn+: Höhere Abopreise für minimale Download-Funktion
ProSiebenSat.1 erhöht den Abopreis für JoynPlus+, das dabei in Joyn+ umbenannt wird. Trotz Preiserhöhung gibt es im Abo Werbung. (Joyn, Streaming)
Quelle: Golem

ProSiebenSat.1 erhöht den Abopreis für JoynPlus+, das dabei in Joyn+ umbenannt wird. Trotz Preiserhöhung gibt es im Abo Werbung. (Joyn, Streaming)
Quelle: Golem

Lucasfilm veröffentlicht den finalen Trailer zu The Mandalorian and Grogu. Der Vorverkauf für den Kinostart läuft. (The Mandalorian, Digitalkino)
Quelle: Golem

Es ist der bisher größte N-1 Starfighter im Lego-Sortiment. Dafür ist er auch mit Abstand der teuerste. (Star Wars, Lego)
Quelle: Golem
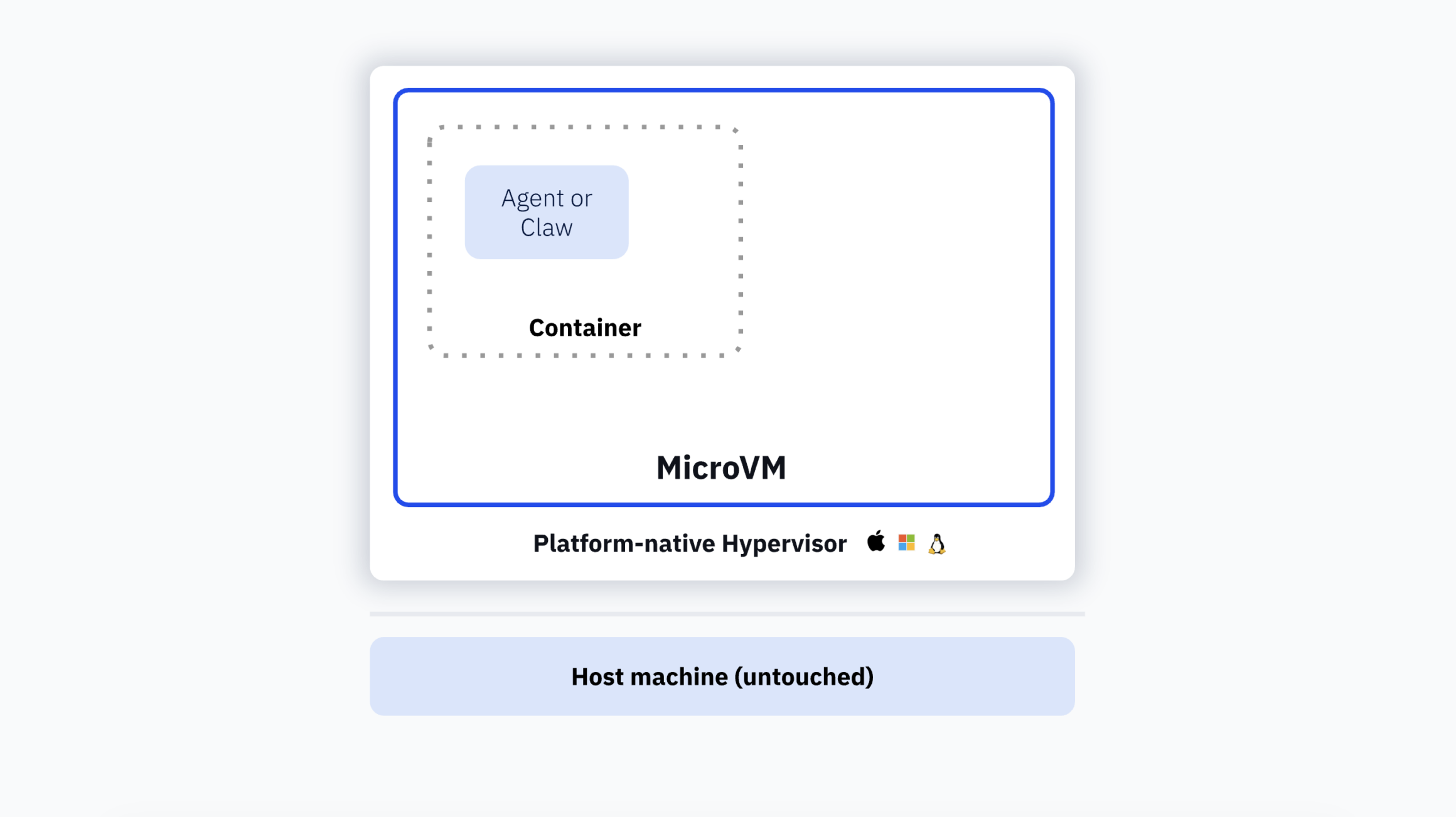
Last week, we launched Docker Sandboxes with a bold goal: to deliver the strongest agent isolation in the market.
This post unpacks that claim, how microVMs enable it, and some of the architectural choices we made in this approach.
The Problem With Every Other Approach
Every sandboxing model asks you to give something up. We looked at the top four approaches.
Full VMs offer strong isolation, but general-purpose VMs weren’t designed for ephemeral, session-heavy agent workflows. Some VMs built for specific workloads can spin up more effectively on modern hardware, but the general-purpose VM experience (slow cold starts, heavy resource overhead) pushes developers toward skipping isolation entirely.
Containers are fast and are the way modern applications are built. But for an autonomous agent that needs to build and run its own Docker containers, which coding agents routinely do, you hit Docker-in-Docker, which requires elevated privileges that undermine the isolation you set up in the first place. Agents need a real Docker environment to do development work, and containers alone don’t give you that cleanly.
WASM / V8 isolates are fast to spin up, but the isolation model is fundamentally different. You’re running isolates, not operating systems. Even providers of isolate-based sandboxes have acknowledged that hardening V8 is difficult, and that security bugs in the V8 engine surface more frequently than in mature hypervisors. Beyond the security model, there’s a practical gap: your agent can’t install system packages or run arbitrary shell commands. For a coding agent that needs a real development environment, WASM isn’t one.
Not using any sandboxing is fast, obviously. It’s also a liability. One rm -rf, one leaked .env, one rogue network call, and the blast radius is your entire machine.
Why MicroVMs
Docker Sandboxes run each agent session inside a dedicated microVM with a private Docker daemon isolated by the VM boundary, and no path back to the host.
That one sentence contains three architectural decisions worth unpacking.
Dedicated microVM. Each sandbox gets its own kernel. It’s hardware-boundary isolation, the same kind you get from a full VM. A compromised or runaway agent can’t reach the host, other sandboxes, or anything outside its environment. If it tries to escape, it hits a wall.
Private, VM-isolated Docker daemon. This is the key differentiator for coding agents. AI is going to result in more container workloads, not fewer. Containers are how applications are developed, and agents need a Docker environment to do that development. Docker Sandboxes give each agent its own Docker daemon running inside a microVM, fully isolated by the VM boundary. Your agent gets full docker build, docker run, and docker compose support with no socket mounting, no host-level privileges, none of the security compromises other approaches require. This means we treat agents as we would a human developer, giving them a true developer environment so they can actually complete tasks across the SDLC.
No path back to the host. File access, network policies, and secrets are defined before the agent runs, not enforced by the agent itself. This is an important distinction. An LLM deciding its own security boundaries is not a security model. The bounding box has to come from infrastructure, not from a system prompt.
Why We Built a New VMM
Choosing microVMs was the easy part. Running them where developers actually work was the hard part.
We looked hard at existing options, but none of them were designed for what we needed. Firecracker, the most well-known microVM runtime, was designed for cloud infrastructure, specifically Linux/KVM environments like AWS Lambda. It has no native support for macOS or Windows, full stop. That’s fine for server-side workloads, but coding agents don’t run in the cloud. They run on developer laptops, across macOS, Windows, and Linux.
We could have shimmed an existing VMM into working across platforms, creating translation layers on macOS and workarounds on Windows, but bolting cross-platform support onto a Linux-first VMM means fighting abstractions that were never designed for it. That’s how you end up with fragile, layered workarounds that break the “it just works” promise and create the friction that makes developers skip sandboxing altogether.
So we built a new VMM, purpose-built for where coding agents actually run.
It runs natively on all three platforms using each OS’s native hypervisor: Apple’s Hypervisor.framework, Windows Hypervisor Platform, and Linux KVM. A single codebase for three platforms and zero translation layers.
This matters because it means agents get kernel-level isolation optimized for each specific OS. Cold starts are fast because there’s no abstraction tax. A developer on a MacBook gets the same isolation guarantees and startup performance as a developer on a Linux workstation or a Windows machine.
Building a VMM from scratch is not a small undertaking. But the alternative, asking developers to accept slower starts, degraded compatibility, or platform-specific caveats, is exactly the kind of asterisk that makes people run agents on the host instead. Our approach removes that asterisk at the hypervisor level.
Fast Cold Starts
We rebuilt the virtualization layer from scratch, optimizing for fast spin up and fast tear downs. Cold starts are fast. This matters for one reason: if the sandbox is slow, developers skip it. Every friction point between “start agent” and “agent is running” is a reason to run on the host instead. With near-instant starts, there is no performance reason to run outside it.
What This Means In Practice
Here’s the concrete version of what this architecture gives you:
Full development environment. Agents can clone repos, install dependencies, run test suites, build Docker images, spin up multi-container services, and open pull requests, all inside the sandbox. Nothing is stubbed out or simulated. Agents are treated as developers and given what they need to complete tasks end to end.
Scoped access, not all-or-nothing. You define the boundary: exactly which files and directories the agent can see, which network endpoints it can reach, and which secrets it receives. Credentials are injected at runtime and outside the MicroVM boundary, never baked into the environment.
Disposable by design. If an agent goes off track, delete the sandbox and start fresh in seconds. There is no state to clean up and nothing to roll back on your host.
Works with every major agent. Claude Code, Codex, OpenCode, GitHub Copilot, Gemini CLI, Kiro, Docker Agent, and next-generation autonomous systems like OpenClaw and NanoClaw. Same isolation, same speed, one sandbox model across all of them.
For Teams
Individual developers can install and run Docker Sandboxes today, standalone, no Docker Desktop license required.
For teams that want centralized filesystem and network policies that can be enforced across an organization and scale sandboxed execution, get in touch to learn about enterprise deployment.
The Tradeoff That Isn’t
The pitch for sandboxing has always come with an asterisk: yes, it’s safer, but you’ll pay for it in speed, compatibility, or workflow friction.
MicroVMs eliminate that asterisk. You get VM-grade isolation with cold starts fast enough that there’s no reason to skip it, and full Docker support inside the sandbox. There is no tradeoff.
Your agents should be running autonomously. They just shouldn’t be running without any guardrails.
Use Sandboxes in Seconds
Install Sandboxes with a single command.
macOSbrew install docker/tap/sbx
Windows winget install Docker.sbx
Read the docs to learn more.
Quelle: https://blog.docker.com/feed/
Today, AWS announces multi-session support for Amazon Quick, which enables customers to access up to five Amazon Quick accounts simultaneously within the same browser. The feature also includes the Amazon Quick account name in all URLs, enabling users to easily access the correct account when opening agents, spaces, flows, research reports, dashboards, and other assets. Customers use multiple accounts for different environments such as development, testing, and production, and compare insights and resource configurations across multiple accounts for troubleshooting and other application-related jobs. Using multi-session capability in Amazon Quick, customers can now sign in to multiple accounts and manage their resources in a single browser. You can sign in to another account by accessing the Amazon Quick top right menu and selecting the option to sign in to another account. For users accessing global URLs without an account name, Amazon Quick presents an account input page that pre-populates the accounts they are logged into, allowing them to select the desired account. You have the option to log out of the current session in the specific browser tab or log out of all sessions. Amazon Quick multi-account sign-in is available in all supported Amazon Quick regions. To learn more about this, visit Amazon Quick Signing In
Quelle: aws.amazon.com
Amazon Bedrock, the platform for building AI applications and agents at production scale, now offers Claude Opus 4.7– Anthropic’s most capable Opus model to date — delivering meaningful improvements across agentic coding, professional work, and long-running tasks for developers and enterprises building production AI applications.
Claude Opus 4.7 is an upgrade from Claude Opus 4.6, with stronger performance across the workflows teams run in production. Opus 4.7 works better through ambiguity, is more thorough in its problem solving, and folllows instructions more precisely. For coding, the model extends agentic capabilities with improved long-horizon autonomy, systems engineering, and complex code reasoning. For knowledge work, Claude Opus 4.7 advances professional tasks such as slides and document creation, financial analysis, and data visualization. For long-running tasks, the model stays on track over longer horizons with improved reasoning and memory capabilities. Claude Opus 4.7 also advances visual capabilities with high-resolution image support improving accuracy on charts, dense documents, and screen UIs where fine detail matters.
Claude Opus 4.7 is served through Amazon Bedrock’s next-generation inference engine, delivering enterprise-grade infrastructure for production workloads. It provides zero operator data access, meaning customer prompts and responses are never visible to Anthropic or AWS operators, keeping sensitive data private. It also enables enhanced availability through dynamic traffic routing with expanded in-region options, along with improved scalability.
Claude Opus 4.7 is available in select AWS Regions. To learn more about Claude Opus 4.7 and other Anthropic models available in Amazon Bedrock, visit the Amazon Bedrock page. To get started, see the Amazon Bedrock documentation.
Quelle: aws.amazon.com
AWS Elastic Disaster Recovery (AWS DRS) is now available in the AWS European Sovereign Cloud, enabling organizations with data sovereignty requirements to protect their mission-critical workloads with disaster recovery on AWS. AWS DRS minimizes downtime and data loss with fast, reliable recovery of on-premises and cloud-based applications using affordable storage, minimal compute, and point-in-time recovery, with Recovery Point Objectives (RPOs) measured in seconds and Recovery Time Objectives (RTOs) typically in minutes. With AWS DRS, you can recover applications from physical infrastructure, VMware vSphere, Microsoft Hyper-V, and cloud infrastructure. AWS DRS uses a unified process for testing, recovery, and failback for a wide range of applications, including critical databases such as Oracle, MySQL, and SQL Server, and enterprise applications such as SAP. AWS Elastic Disaster Recovery is available in the AWS European Sovereign Cloud (Germany). See the AWS Regional Services List for the latest availability information. To learn more about AWS Elastic Disaster Recovery, visit our product page or documentation.
Quelle: aws.amazon.com

Derzeit gibt es bei Amazon die Apexcam M90 im Angebot. Die Actioncam ist auf deutlich unter 60 Euro reduziert. (Actioncam, Kameras)
Quelle: Golem

Nur für Prime-Mitglieder gibt es derzeit ein 4-in-1-Autoladegerät mit USB-C- und Lightning-Kabeln integriert im Angebot bei Amazon. (USB PD, Amazon)
Quelle: Golem

Laut den Verbraucherschützern liegt es an der Bundesnetzagentur, Klarheit zu schaffen, welche Entschädigung Mobilfunknutzer erhalten, wenn die Datenrate viel zu niedrig ist. (Bundesnetzagentur, Verbraucherschutz)
Quelle: Golem