Three Considerations for Planning your Docker Datacenter Deployment
Congratulations! You’ve decided to make the change your application environment with Docker Datacenter. You&8217;re now on your way to greater agility, portability and control within your environment. But what do you need to get started? In this blog, we will cover things you need to consider (strategy, infrastructure, migration) to ensure a smooth POC and migration to production.
1. Strategy
Strategy involves doing a little work up-front to get everyone on the same page. This stage is critical to align expectations and set clear success criteria for exiting the project. The key focus areas are to determining your objective, plan out how to achieve it and know who should be involved.
Set the objective – This is a critical step as it helps to set clear expectations, define a use case and outline the success criteria for exiting a POC. A common objective is to enable developer productivity by implementing a Continuous Integration environment with Docker Datacenter.
Plan how to achieve it &8211; With a clear use case and outcome identified, the next step is to look at what is required to complete this project. For a CI pipeline, Docker is able to standardize the development environment, provide isolation of the applications and their dependencies and eliminate any “works on my machine” issues to facilitate the CI automation. When outlining the plan, make sure to select the pilot application. The work involved will vary depending on whether it is a legacy application refactoring or new application development.
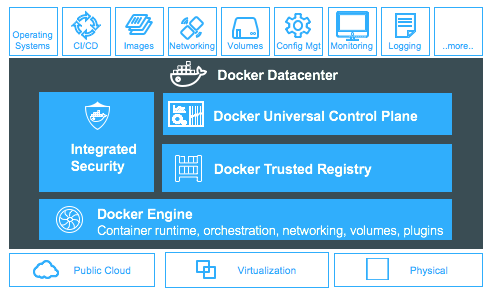
Integration between source control and CI allows Docker image builds to be automatically triggered from a standard Git workflow. This will drive the automated building of Docker images. After Docker images are built they are shipped to the secure Docker registry to store them (Docker Trusted Registry) and role based access controls enable secure collaboration. Images can then be pulled and deployed across a secure cluster as running applications via the management layer of Docker Datacenter (Universal Control Plane).
Know who should be involved &8211; The solution will involve multiple teams and it is important to include the correct people early to avoid any potential barriers later on. These teams can include the following teams, depending on the initial project: development, middleware, security, architects, networking, database, and operations. Understand their requirements and address them early and gain consensus through collaboration.
PRO TIP &8211; Most first successes tend to be web applications with some sort of data tier that can either utilize traditional databases or be containerized with persistent data being stored in volumes.
2. Infrastructure
Now that you understand the basics of building a strategy for your deployment, it’s time to think about infrastructure. In order to install Docker Datacenter (DDC) in a highly available (HA) deployment, the minimum base infrastructure is six nodes. This will allow for the installation of three UCP managers and three DTR replicas on worker nodes in addition to the worker nodes where the workloads will be deployed. An HA set up is not required for an evaluation but we recommend a minimum of 3 replicas and managers for production deployments so your system can handle failures.
PRO TIP &8211; A best practice is to not deploy and run any container workloads on the UCP managers and DTR replicas. These nodes perform critical functions within DDC and are best if they only run the UCP or DTR services.
Nodes are defined as cloud, virtual or physical servers with Commercially Supported (CS) Docker Engine installed as a base configuration.
Each node should consist of a minimum of:
4GB of RAM
16GB storage space
For RHEL/CentOS with devicemapper: separate block device OR additional free space on the root volume group should be available for Docker storage.
Unrestricted network connectivity between nodes
OPTIONAL Internet access to Docker Hub to ease the initial downloads of the UCP/DTR and base content images
Installed with Docker supported operating system
Sudo access credentials to each node
Other nodes may be required for related CI tooling. For a POC built around DDC in a HA deployment with CI/CD, ten nodes are recommended. For a POC built around DDC in a non-HA deployment with CI/CD, five nodes are recommended.
Below are specific requirements for the individual components of the DDC platform:
Universal Control Plane
Commercially Supported (CS) Docker Engine must be used in conjunction with DDC.
TCP Load balancer should be available for UCP in an HA configuration.
A valid DNS entry should be created for the load balancer VIP.
SSL certificate from a trusted root CA should be created (a self-signed certificate is created for UCP and may be used but additional configuration is required).
DDC License for 30 day trial or annual subscription must be obtained or purchased for the POC.
Docker Trusted Registry
Commercially Supported (CS) Docker Engine must be used in conjunction with DDC.
TCP Load balancer should be available for DTR in an HA configuration.
A valid DNS entry should be created for the load balancer VIP.
Image Storage options include a clustered filesystem for HA or blob storage (AWS S3, Azure, S3 compatible storage, or OpenStack Swift)
SSL certificate from a trusted root CA should be created (a self-signed certificate is created for DTR and may be used but additional configuration is required).
LDAP/AD is available for authentication; managed built-in authentication can also be used but requires additional configuration
DDC License for 30 day trial or annual subscription must be obtained or purchased for the POC.
The POC design phase is the ideal time to assess how Docker Datacenter will integrate into your existing IT infrastructure, from CI/CD, networking/load balancing, volumes for persistent data, configuration management, monitoring, and logging systems. During this phase, understand how how the existing tools fit and discover any gaps in your tooling. With the strategy and infrastructure prepared, begin the POC installation and testing. Installation docs can be found here.
3. Moving from POC Into Production
Once you have the built out your POC environment, how do you know if it’s ready for production use? Here are some suggested methods to handle the migration.
Perform the switchover from the non-Dockerized apps to Docker Datacenter in pre-production environments. Have Dev, Test, and Prod environments, switchover Dev and/or Test and run through a set burn in cycle to allow for the proper testing of the environment to look for any unexpected or missing functionality. Once non-production environments are stable, switch over to the production environment.
Start integrating Docker Datacenter alongside your existing application deployments. This method requires that the application can run with multiple instances running at the same time. For example, if your application is fronted by a load balancer, add the Dockerized application to the existing load balancer pool and begin sending traffic to the application running in Docker Datacenter. Should issues arise, remove the Dockerized application running from the load balancer pool until issues can be resolved.
Completely cutover to a Dockerized environment all in one go. As additional applications begin to utilize Docker Datacenter, continue to use a tested pattern that works best for you to provide a standard path to production for your applications.
We hope these tips, learned from first hand experience with our customers help you in planning for your deployment. From standardizing your application environment and simultaneously adding more flexibility for your application teams, Docker Datacenter gives you a foundation to build, ship and run containerized applications anywhere.
3 Considerations for a successful #DockerDatacenter deployment Click To Tweet
Enjoy your Docker Datacenter POC
Get started with your Docker Datacenter POC
See What’s New in Docker Datacenter
Learn more by visiting the Docker Datacenter webpage
Sign up for a free 30 day trial
The post Three Considerations for Planning your Docker Datacenter Deployment appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/