Your Org, Your Tools: Building a Custom MCP Catalog
I’m Mike Coleman, a staff solutions architect at Docker. In this role, I spend a lot of time talking to enterprise customers about AI adoption. One thing I hear over and over again is that these companies want to ensure appropriate guardrails are in place when it comes to deploying AI tooling.
For instance, many organizations want tighter control over which tools developers and AI assistants can access via Docker’s Model Context Protocol (MCP) tooling. Some have strict security policies that prohibit pulling images directly from Docker Hub. Others simply want to offer a curated set of trusted MCP servers to their teams or customers.
In this post, we walk through how to build your own MCP catalog. You’ll see how to:
Fork Docker’s official MCP catalog
Host MCP server images in your own container registry
Publish a private catalog
Use MCP Gateway to expose those servers to clients
Whether you’re pulling existing MCP servers from Docker’s MCP Catalog or building your own, you’ll end up with a clean, controlled MCP environment that fits your organization.
Introducing Docker’s MCP Tooling
Docker’s MCP ecosystem has three core pieces:
MCP Catalog
A YAML-based index of MCP server definitions. These describe how to run each server and what metadata (description, image, repo) is associated with it. The MCP Catalog hosts over 220+ containerized MCP servers, ready to run with just a click.
The official docker-mcp catalog is read-only. But you can fork it, export it, or build your own.
MCP Gateway
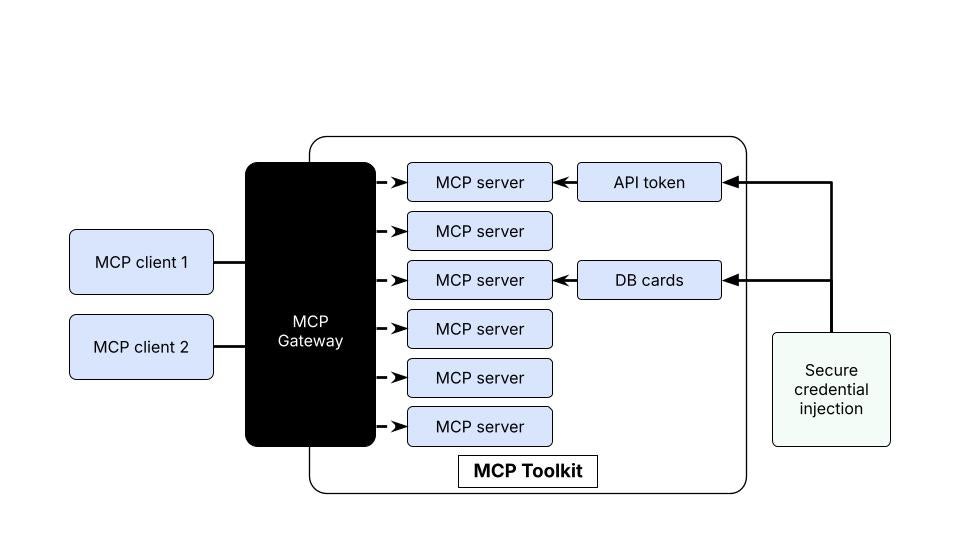
The MCP Gateway connects your clients to your MCP servers. It doesn’t “host” anything — the servers are just regular Docker containers. But it provides a single connection point to expose multiple servers from a catalog over HTTP SSE or STDIO.
Traditionally, with X servers and Y clients, you needed X * Y configuration entries. MCP Gateway reduces that to just Y entries (one per client). Servers are managed behind the scenes based on your selected catalog.
You can start the gateway using a specific catalog:
docker mcp gateway run –catalog my-private-catalog
MCP Gateway is open source: https://github.com/docker/mcp-gateway
Figure 1: The MCP Gateway provides a single connection point to expose multiple MCP servers
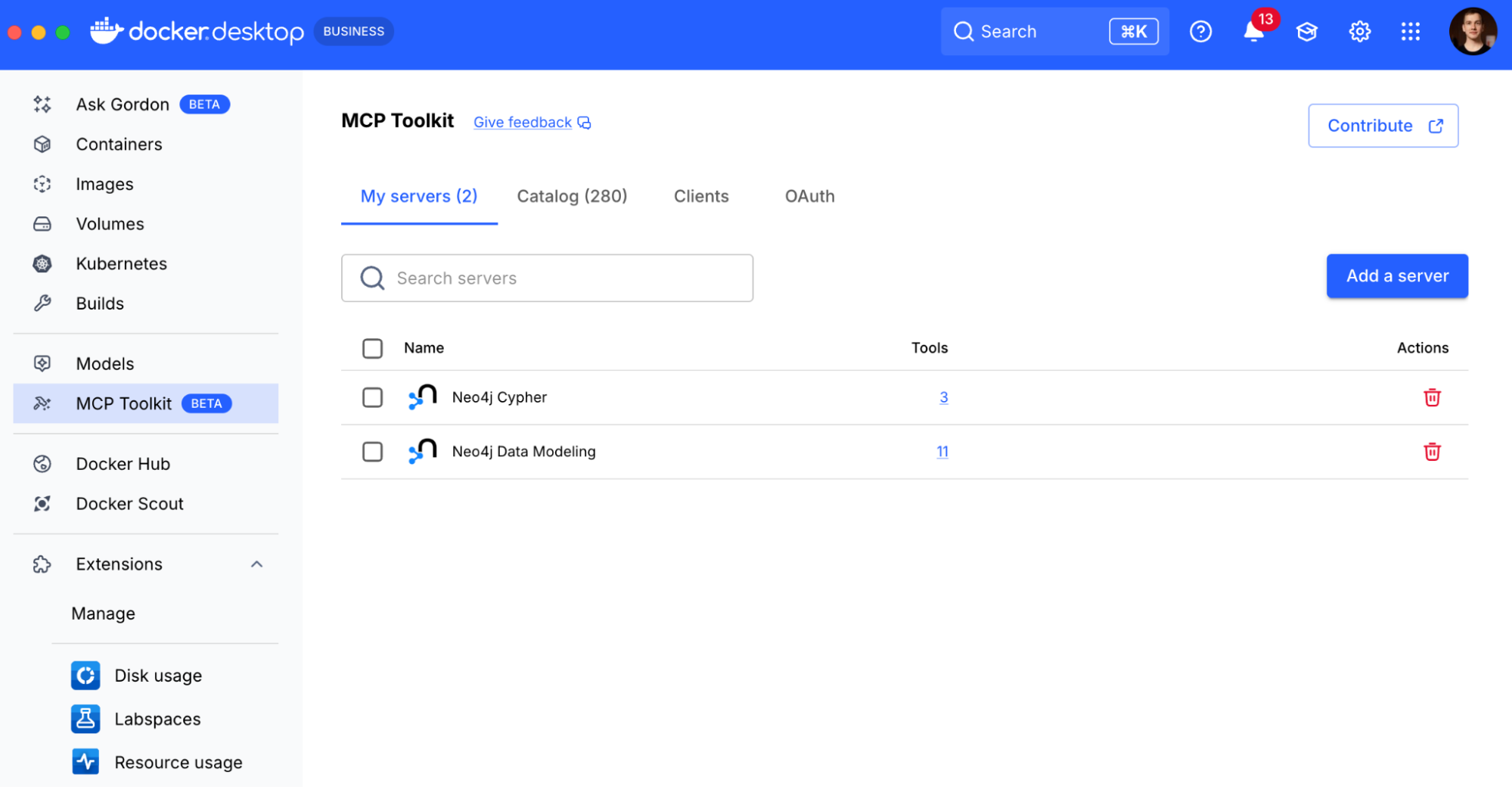
MCP Toolkit (GUI)
Built into Docker Desktop, the MCP Toolkit provides a graphical way to work with the MCP Catalog and MCP Gateway. This allows you to:
Access to Docker’s MCP Catalog via a rich GUI
Secure handling of secrets (like GitHub tokens)
Easily enable MCP servers
Connect your selected MCP servers with one click to a variety of clients like Claude code, Claude Desktop, Codex, Cursor, Continue.dev, and Gemini CLI
Workflow Overview
The workflow below will show you the steps necessary to create and use a custom MCP catalog.
The basic steps are:
Export the official MCP Catalog to inspect its contents
Fork the Catalog so you can edit it
Create your own private catalog
Add specific server entries
Pull (or rebuild) images and push them to your registry
Update your catalog to use your images
Run the MCP Gateway using your catalog
Connect clients to it
Step-by-Step Guide: Creating and Using a Custom MCP Catalog
We start by setting a few environment variables to make this process repeatable and easy to modify later.For the purpose of this example, assume we are migrating an existing MCP server (DuckDuckGo) to a private registry (ghcr.io/mikegcoleman). You can also add your own custom MCP server images into the catalog, and we mention that below as well.
export MCP_SERVER_NAME="duckduckgo"
export GHCR_REGISTRY="ghcr.io"
export GHCR_ORG="mikegcoleman"
export GHCR_IMAGE="${GHCR_REGISTRY}/${GHCR_ORG}/${MCP_SERVER_NAME}:latest"
export FORK_CATALOG="my-fork"
export PRIVATE_CATALOG="my-private-catalog"
export FORK_EXPORT="./my-fork.yaml"
export OFFICIAL_DUMP="./docker-mcp.yaml"
export MCP_HOME="${HOME}/.docker/mcp"
export MCP_CATALOG_FILE="${MCP_HOME}/catalogs/${PRIVATE_CATALOG}.yaml"
Step 1: Export the official MCP Catalog
Exporting the official Docker MCPCatalog gives you a readable local YAML file listing all servers. This makes it easy to inspect metadata like images, descriptions, and repository sources outside the CLI.
docker mcp catalog show docker-mcp –format yaml > "${OFFICIAL_DUMP}"
Step 2: Fork the official MCP Catalog
Forking the official catalog creates a copy you can modify. Since the built-in Docker catalog is read-only, this fork acts as your editable version.
docker mcp catalog fork docker-mcp "${FORK_CATALOG}"
docker mcp catalog ls
Step 3: Create a new catalog
Now create a brand-new catalog that will hold only the servers you explicitly want to support. This ensures your organization runs a clean, controlled catalog that you fully own.
docker mcp catalog create "${PRIVATE_CATALOG}"
Step 4: Add specific server entries
Export your forked catalog to a file so you can copy over just the entries you want. Here we’ll take only the duckduckgo server and add it to your private catalog.
docker mcp catalog export "${FORK_CATALOG}" "${FORK_EXPORT}"
docker mcp catalog add "${PRIVATE_CATALOG}" "${MCP_SERVER_NAME}" "${FORK_EXPORT}"
Step 5: Pull (or rebuild) images and push them to your registry
At this point you have two options:
If you are able to pull from Docker Hub, find the image key for the server you’re interested in by looking at the YAML file you exported earlier. Then pull that image down to your local machine. After you’ve pulled it down, retag it for whatever repository it is you want to use.
Example for duckduckgo
vi "${OFFICIAL_DUMP}" # look for the duckduck go entry and find the image: key which will look like this:
# image: mcp/duckduckgo@sha256:68eb20db6109f5c312a695fc5ec3386ad15d93ffb765a0b4eb1baf4328dec14f
# pull the image to your machine
docker pull
mcp/duckduckgo@sha256:68eb20db6109f5c312a695fc5ec3386ad15d93ffb765a0b4eb1baf4328dec14f
# tag the image with the appropriate registry
docker image tag mcp/duckduckgo@sha256:68eb20db6109f5c312a695fc5ec3386ad15d93ffb765a0b4eb1baf4328dec14f ${GHCR_IMAGE}
# push the image
docker push ${GHCR_IMAGE}
At this point you can move on to editing the MCP Catalog file in the next section.
If you cannot download from Docker Hub you can always rebuild the MCP server from its GitHub repo. To do this, open the exported YAML and look for your target server’s GitHub source repository. You can use tools like vi, cat, or grep to find it — it’s usually listed under a source key.
Example for duckduckgo:
source: https://github.com/nickclyde/duckduckgo-mcp-server/tree/main
export SOURCE_REPO="https://github.com/nickclyde/duckduckgo-mcp-server.git"
Next, you’ll rebuild the MCP server image from the original GitHub repository and push it to your own registry. This gives you full control over the image and eliminates dependency on Docker Hub access.
echo "${GH_PAT}" | docker login "${GHCR_REGISTRY}" -u "${GHCR_ORG}" –password-stdin
docker buildx build
–platform linux/amd64,linux/arm64
"${SOURCE_REPO}"
-t "${GHCR_IMAGE}"
–push
Step 6: Update your catalog
After publishing the image to GHCR, update your private catalog so it points to that new image instead of the Docker Hub version. This step links your catalog entry directly to the image you just built.
vi "${MCP_CATALOG_FILE}"
# Update the image line for the duckduckgo server to point to the image you created in the previous step (e.g. ghcr.io/mikegcoleman/duckduckgo-mcp)
Remove the forked version of the catalog as you no longer need it
docker mcp catalog rm "${FORK_CATALOG}"
Step 7: Run the MCP Gateway
Enabling the server activates it within your MCP environment. Once enabled, the gateway can load it and make it available to connected clients. You will get warnings about “overlapping servers” that is because the same servers are listed in two places (your catalog and the original catalog)
docker mcp server enable "${MCP_SERVER_NAME}"
docker mcp server list
Step 8: Connect to popular clients
Now integrate the MCP Gateway with your chosen client. The raw command to run the gateway is:
docker mcp gateway run –catalog "${PRIVATE_CATALOG}"
But that just runs an instance on your local machine, when what you probably want is to integrate with some client application.
To do this you need to format the raw command so that it works for the client you wish to use. For example, with VS Code you’d want to update the mcp.json as follows:
"servers": {
"docker-mcp-gateway-private": {
"type": "stdio",
"command": "docker",
"args": [
"mcp",
"gateway",
"run",
"–catalog",
"my-private-catalog"
]
}
}
Finally, verify that the gateway is using your new GHCR image and that the server is properly enabled. This quick check confirms everything is configured as expected before connecting clients.
docker mcp server inspect "${MCP_SERVER_NAME}" | grep -E 'name|image'
Summary of Key Commands
You might find the following CLI commands handy:
docker mcp catalog show docker-mcp –format yaml > ./docker-mcp.yaml
docker mcp catalog fork docker-mcp my-fork
docker mcp catalog export my-fork ./my-fork.yaml
docker mcp catalog create my-private-catalog
docker mcp catalog add my-private-catalog duckduckgo ./my-fork.yaml
docker buildx build –platform linux/amd64,linux/arm64 https://github.com/nickclyde/duckduckgo-mcp-server.git
-t ghcr.io/mikegcoleman/duckduckgo:latest –push
docker mcp server enable duckduckgo
docker mcp gateway run –catalog my-private-catalog
Conclusion
By using Docker’s MCP Toolkit, Catalog, and Gateway, you can fully control the tools available to your developers, customers, or AI agents. No more one-off setups, scattered images, or cross-client connection headaches.
Your next steps:
Add more servers to your catalog
Set up CI to rebuild and publish new server images
Share your catalog internally or with customers
Docs:
https://docs.docker.com/ai/mcp-catalog-and-toolkit/
https://github.com/docker/mcp-gateway/
Happy curating.
We’re working on some exciting enhancements to make creating custom catalogs even easier. Stay tuned for updates!
Learn more
Explore the MCP Catalog: Discover containerized, security-hardened MCP servers
Open Docker Desktop and get started with the MCP Toolkit (Requires version 4.48 or newer to launch the MCP Toolkit automatically)
Read about How Open Source Genius Cut Entropy Debt with Docker MCP Toolkit and Claude Desktop
Quelle: https://blog.docker.com/feed/