From Hallucinations to Prompt Injection: Securing AI Workflows at Runtime
How developers are embedding runtime security to safely build with AI agents
Introduction: When AI Workflows Become Attack Surfaces
The AI tools we use today are powerful, but also unpredictable and exploitable.
You prompt an LLM and it generates a Dockerfile. It looks correct. A shell script? Reasonable. You run it in dev. Then something breaks: a volume is deleted. A credential leaks into a log. An outbound request hits a production API. Nothing in your CI pipeline flagged it, because the risk only became real at runtime.
This is the new reality of AI-native development: fast-moving code, uncertain behavior, and an expanding attack surface.
Hallucinations in LLM output are only part of the story. As developers build increasingly autonomous agentic tools, they’re also exposed to prompt injection, jailbreaks, and deliberate misuse of model outputs by adversaries. A malicious user, through a cleverly crafted input, can hijack an AI agent and cause it to modify files, exfiltrate secrets, or run unauthorized commands.
In one recent case, a developer ran an LLM-generated script that silently deleted a production database, an issue that went undetected until customer data was already lost. In another, an internal AI assistant was prompted to upload sensitive internal documents to an external file-sharing site, triggered entirely through user input.
These failures weren’t caught in static analysis, code review, or CI. They surfaced only when the code ran.
In this post, we’ll explore how developers are addressing both accidental failures and intentional threats by shifting runtime security into the development loop, embedding observability, policy enforcement, and threat detection directly into their workflows using Docker.
The Hidden Risks of AI-Generated Code
LLMs and AI agents are great at generating text, but they don’t always know what they’re doing. Whether you’re using GitHub Copilot, LangChain, or building with OpenAI APIs, your generated outputs might include:
Shell scripts that escalate privileges or misconfigure file systems
Dockerfiles that expose unnecessary ports or install outdated packages
Infra-as-code templates that connect to production services by default
Hardcoded credentials or tokens hidden deep in the output
Command sequences that behave differently depending on the context
The problem is compounded when teams start running autonomous agents, AI tools designed to take actions, not just suggest code. These agents can:
Execute file writes and deletions
Make outbound API calls
Spin up or destroy containers
Alter configuration state mid-execution
Execute dangerous database queries
These risks only surface at runtime, after your build has passed and your pipeline has shipped. And that’s a problem developers are increasingly solving inside the dev loop.
Why Runtime Security Belongs in the Developer Workflow
Traditional security tooling focuses on build-time checks, SAST, SCA, linters, compliance scanners. These are essential, but they don’t protect you from what AI-generated agents do at execution time.
Developers need runtime security that fits their workflow, not a blocker added later.
What runtime security enables:
Live detection of dangerous system calls or file access
Policy enforcement when an agent attempts unauthorized actions
Observability into AI-generated code behavior in real environments
Isolation of high-risk executions in containerized sandboxes
Why it matters:
Faster feedback loops: See issues before your CI/CD fails
Reduced incident risk: Catch privilege escalation, data exposure, or network calls early
Higher confidence: Ship LLM-generated code without guesswork
Secure experimentation: Enable safe iteration without slowing down teams
Developer ROI: Catching a misconfigured agent in dev avoids hours of triage and mitigates production risk and reputation risk; saving time, cost, and compliance exposure.
Building Safer AI Workflows with Docker
Docker provides the building blocks to develop, test, and secure modern agentic applications:
Docker Desktop gives you an isolated, local runtime for testing unsafe code
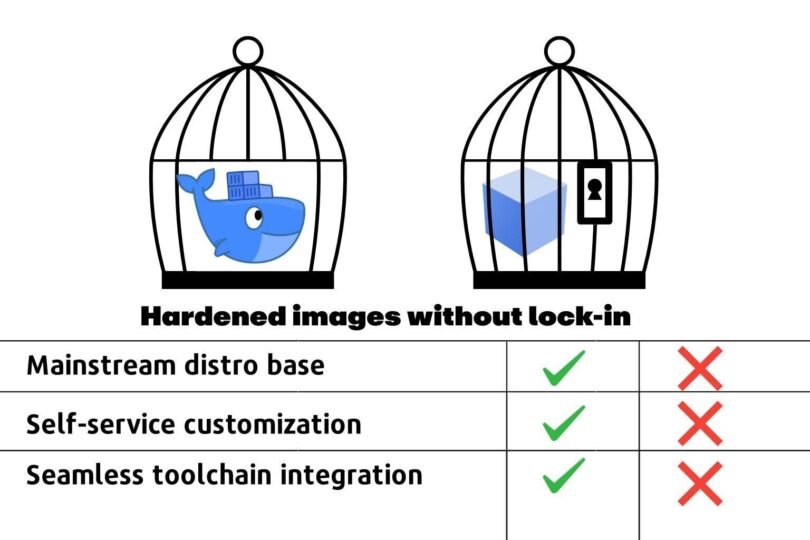
Docker Hardened Images. Secure, minimal, production-ready images
Docker Scout scans container images for vulnerabilities and misconfigurations
Runtime policy enforcement (with upcoming MCP Defender integration) provides live detection and guardrails while code executes
Step-by-Step: Safely Test AI-Generated Scripts
1. Run your agent or script in a hardened container
docker run –rm -it
–security-opt seccomp=default.json
–cap-drop=ALL
-v $(pwd):/workspace
python:3.11-slim
Applies syscall restrictions and drops unnecessary capabilities
Runs with no persistent volume changes
Enables safe, repeatable testing of LLM output
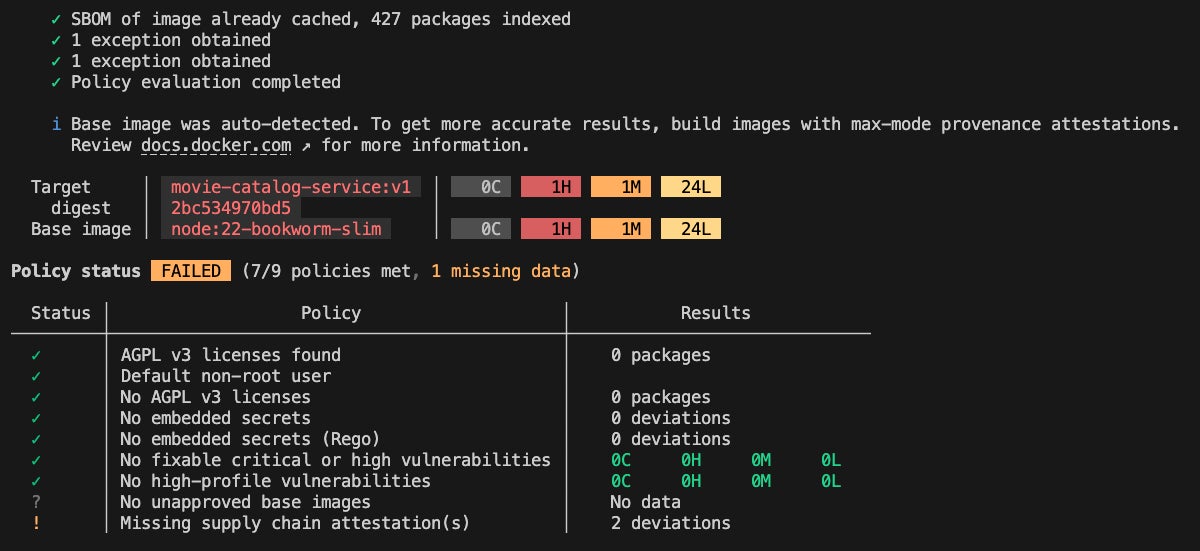
2. Scan the container with Docker Scout
docker scout cves my-agent:latest
Surfaces known CVEs and outdated dependencies
Detects unsafe base images or misconfigured package installs
Available both locally and inside CI/CD workflows
3. Add runtime policy (beta) to block unsafe behavior
scout policy add deny-external-network
–rule "deny outbound to *"
This would catch an AI agent that unknowingly makes an outbound request to an internal system, third-party API, or external data store.
Note: Runtime policy enforcement in Docker Scout is currently in development. CLI and behavior may change upon release.
Best Practices for Securing AI Agent Containers
Practice
Why it matters
Use slim, verified base images
Minimizes attack surface and dependency drift
Avoid downloading from unverified sources
Prevents LLMs from introducing shadow dependencies
Use .dockerignore and secrets management
Keeps secrets out of containers
Run containers with dropped capabilities
Limits impact of unexpected commands
Apply runtime seccomp profiles
Enforces syscall-level sandboxing
Log agent behavior for analysis
Builds observability into experimentation
Integrating Into Your Cloud-Native Workflow
Runtime security for AI tools isn’t just for local testing, it fits cleanly into cloud-native and CI/CD workflows too.
GitHub Actions Integration Example:
jobs:
security-scan:
runs-on: ubuntu-latest
steps:
– uses: actions/checkout@v3
– name: Build container
run: docker build -t my-agent:latest .
– name: Scan for CVEs
run: docker scout cves my-agent:latest
Works across environments:
Local dev via Docker Desktop
Remote CI/CD via GitHub Actions, GitLab, Jenkins
Kubernetes staging environments with policy enforcement and agent isolation
Cloud Development Environments (CDEs) with Docker + secure agent sandboxes
Dev teams using ephemeral workspaces and Docker containers in cloud IDEs or CDEs can now enforce the same policies across local and cloud environments.
Real-World Example: AI-Generated Infra Gone Wrong
A platform team uses an LLM agent to auto-generate Kubernetes deployment templates. A developer reviews the YAML and merges it. The agent-generated config opens an internal-only service to the internet via LoadBalancer. The CI pipeline passes. The deploy works. But a customer database is now exposed.
Had the developer run this template inside a containerized sandbox with outbound policy rules, the attempt to expose the service would have triggered an alert, and the policy would have prevented escalation.
Lesson: You can’t rely on static review alone. You need to see what AI-generated code does, not just what it looks like.
Why This Matters: Secure-by-Default for AI-Native Dev Teams
As LLM-powered tools evolve from suggestion to action, runtime safety becomes a baseline requirement, not an optional add-on.
The future of secure AI development starts in the inner loop, with runtime policies, observability, and smart defaults that don’t slow you down.
Docker’s platform gives you:
Developer-first workflows with built-in security
Runtime enforcement to catch AI mistakes early
Toolchain integration across build, test, deploy
Cloud-native flexibility across local dev, CI/CD, and CDEs
Whether you’re building AI-powered automations, agent-based platforms, or tools that generate infrastructure, you need a runtime layer that sees what AI can’t, and blocks what it shouldn’t do.
What’s Next
Runtime protection is moving left, into your dev environment. With Docker, developers can:
Run LLM-generated code in secure, ephemeral containers
Observe runtime behavior before pushing to CI
Enforce policies that prevent high-risk actions
Reduce the risk of silent security failures in AI-powered apps
Docker is working to bring MCP Defender into our platform to provide this protection out-of-the-box, so hallucinations don’t turn into incidents.
Ready to Secure Your AI Workflow?
Sign up for early access to Docker’s runtime security capabilities
Watch our Tech Talk on “Building Safe AI Agents with Docker”
Explore Docker Scout for real-time vulnerability insights
Join the community conversation on Docker Community Slack or GitHub Discussions
Let’s build fast, and safely.
Quelle: https://blog.docker.com/feed/