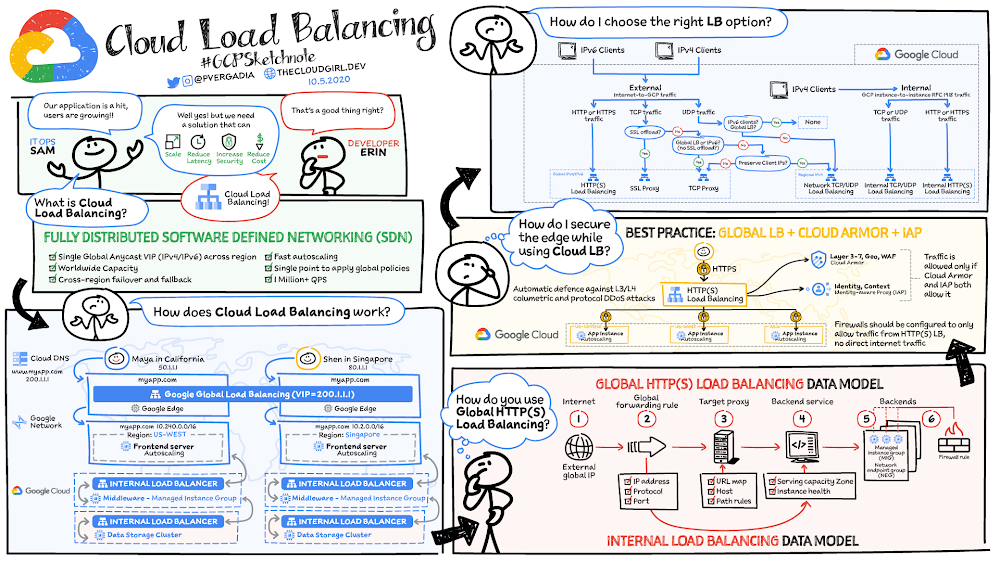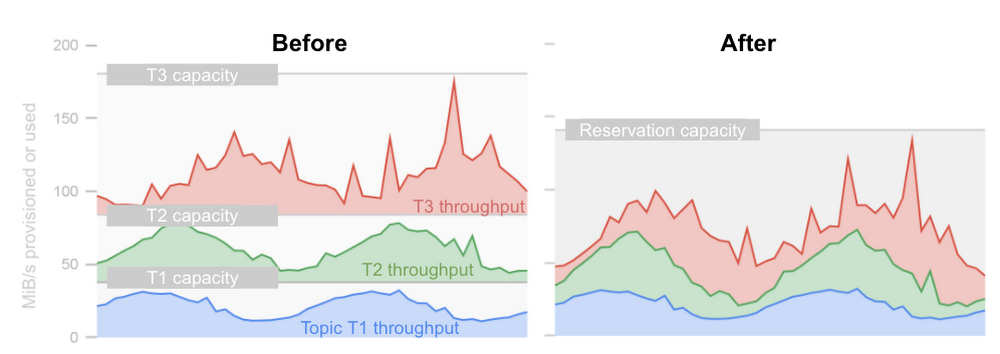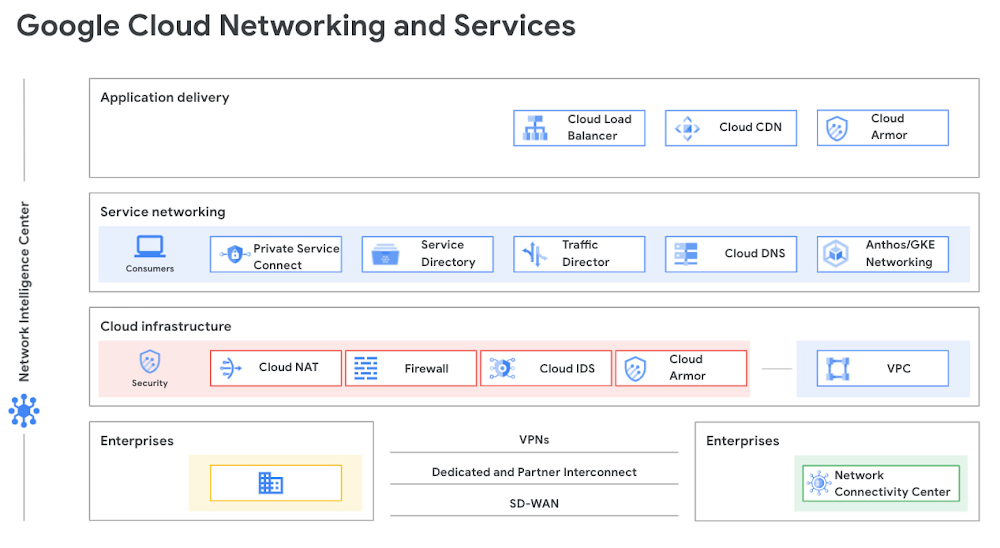
Building and expanding network services for a smart and connected world
Organizations are increasingly adopting multicloud implementations and hybrid deployments as a part of their cloud strategy. Networking is at the foundation of this digital transformation. Google has built a massive planet-scale network infrastructure serving billions of users every day. Our global network continues to expand in footprint with four new regions announced this year in Chile, Germany, Saudi Arabia and Israel. Regions in Delhi NCR, Melbourne, Warsaw and Toronto are now open. We also announced six new subsea cables which connect different parts of the world. Google Cloud offers a broad portfolio of networking services built on top of planet-scale infrastructure that leverages automation, advanced AI, and programmability, enabling enterprises to connect, scale, secure, modernize and optimize their infrastructure, without worrying about the complexity of the underlying network. In the past year, we’ve made several advancements to our networking services stack, from layer 1 to layer 7, so you can easily and flexibly scale your business. And what better time to discuss this progress as we gear up for Next ’21!Click to enlargeSimplify connectivity for hybrid environmentsLet’s start with connectivity. Networking can get complex, especially in hybrid and multicloud deployments. That’s why we introduced Network Connectivity Center in March as a single place to manage global connectivity. Network Connectivity Center provides deep visibility into the Google Cloud network with tight integration with third-party solutions. In May, we integrated Network Connectivity Center with Cisco, Fortinet, Palo Alto Networks, Versa Networks and VMware to be able to use their SD-WAN and firewall capabilities with Google Cloud, and Network Connectivity Center will be generally available for all customers in October. Operate confidently with advanced securityThe network security portfolio secures applications from fraudulent activity, malware, and attacks. Cloud Armor, our DDoS protection and WAF service, has four new updates:Integration with Google Cloud reCAPTCHA Enterprise bot and fraud management (in Preview). Learn more in the blog here.Per-client rate limiting, including two rule actions: throttle- and rate-based-ban are available (also in Preview). Both bot management and rate limiting are available in Standard and Managed Protection Plus tiers. Edge security policies allow you to configure filtering and access control policies for content that is stored in cache for Cloud CDN and Cloud Storage; this feature is also now in Preview. Adaptive Protection, our ML-based, application-layer DDoS detection and WAF protection mechanism, is now Generally Available. Other updates in the area of network security include: Cloud IDS, developed with threat detection technologies from Palo Alto Networks, was announced in July and is currently in Preview.In Cloud firewalls, the Firewall Insights capability has expanded, and hierarchical rules became available earlier this year. Cloud NAT has released in Preview new scaling features: destination-based NAT rules and dynamic port allocation.The solution blueprint for Cloud network forensics and telemetry, along with a companion blog comparing methods for harvesting telemetry for network security analytics are both available.Consume services faster with service-centric networkingPrivate Service Connect is a service-centric approach to networking that simplifies consumption and delivery of applications in the cloud. We’re adding support for HTTP(S) Load Balancer, which gives you granular control over your policies, and enables new capabilities such as vanity domain names and URL filtering. It provides tighter integration with services running on Google Kubernetes Engine (GKE) and provides more flexibility for the producers offering managed services. You can connect to services like Bloomberg, Elastic and MongoDB via Private Service Connect so you can develop apps faster and securely on Google Cloud.“MongoDB’s partnership with Google is an integral part of our strategy to support modern apps and mission-critical databases and to become a cloud data company. Private Service Connect allows our customers to connect to MongoDB Atlas on Google Cloud seamlessly and securely and we’re excited for customers to have this additional and important capability.” said Andrew Davidson, VP of Cloud Product at MongoDB.Lastly, managed services in Private Service Connect are now auto-registered with Service Directory in the consumer network, making service consumption even simpler. Service-centric networking extends to GKE and Anthos, which provide a consistent development and operations experience for hybrid and multicloud environments. With Anthos network gateway in Preview, you get more service-centric networking control for your Anthos clusters, with features like Egress NAT Gateway and BGP-based load balancing. With Anthos network gateway, you can streamline costs by removing dependencies on third-party vendors. We’ve added Multi-NIC pod capabilities to our Anthos clusters, allowing customers and partners to offer services by using containerized network functions.Finally, as your GKE clusters grow in size, scalability becomes a big concern. With discontiguous pod CIDR, IP addresses are now a mutable resource, allowing you to increase your cluster size dynamically. No more deleting and recreating the cluster to increase their cluster size.Deliver applications to users anywhereWith Google Cloud’s extensive global network footprint, Cloud Load Balancing can help bring apps in single or multiple regions as close to your users as possible. Cloud Load Balancing now includes advanced traffic management for finer-grained control over your network traffic. These also include Regional Load Balancers which provide additional jurisdiction compliance for workloads that require it. Additionally we support hybrid load balancing capabilities where you can load balance on-prem and multicloud services. In order to serve apps to users quickly with the right level of redundancy and granularity, we are announcing DNS Routing Policiesin Cloud DNS. Now in Preview, this feature lets you steer traffic using DNS, with support for geo-location and weighted round robin policies. We’re also excited to announce that Cloud Domains will be generally available in October. Cloud Domains makes it easy for our cloud customers to register new domains or transfer in existing ones. Cloud Domains is integrated with Cloud DNS to make it easy to create public DNS zones and enable DNSSEC.Adopt proactive network operationsWe have made some exciting strides in Network Intelligence Center, our network monitoring, verification and optimization platform designed to help you move from reactive to proactive network operations. We announced General Availability of Dynamic Reachability within Connectivity Tests module, and General Availability of the Global Performance Dashboard. With Dynamic Reachability, you can get VM-level granularity for loss and latency measurements. Global Performance Dashboard shows real-time overall Google Cloud network performance metrics such as latency and packet loss, so you can correlate per-project performance metrics to the rest of Google Cloud. Find out more at Next ‘21 We have some great deep dive networking sessions at Next ‘21 with our product managers and engineers. Please join us and hear from our product leaders, partners and customers on how to leverage the Google Cloud network for your next cloud initiative. Register for Next and build your custom session playlist today!Sessions:INF105 – What’s new and what’s next with networkingINF205 – Simplifying hybrid networking and servicesINF212 – Delivering 5G networks and ecosystems with distributed cloudINF304 – Next generation load balancingINF305 – Monitor and troubleshoot your network infrastructure with centralized monitoringPAR205 – Google Cloud IDS for Network-based Threat Detection with Palo Alto NetworksSEC211 – Innovations in DDoS, WAF, firewall & network-based threat detectionHOL115 – HTTP Load Balancer with Cloud Armor
Quelle: Google Cloud Platform