Functions, events, triggers oh my! How to build event-driven app
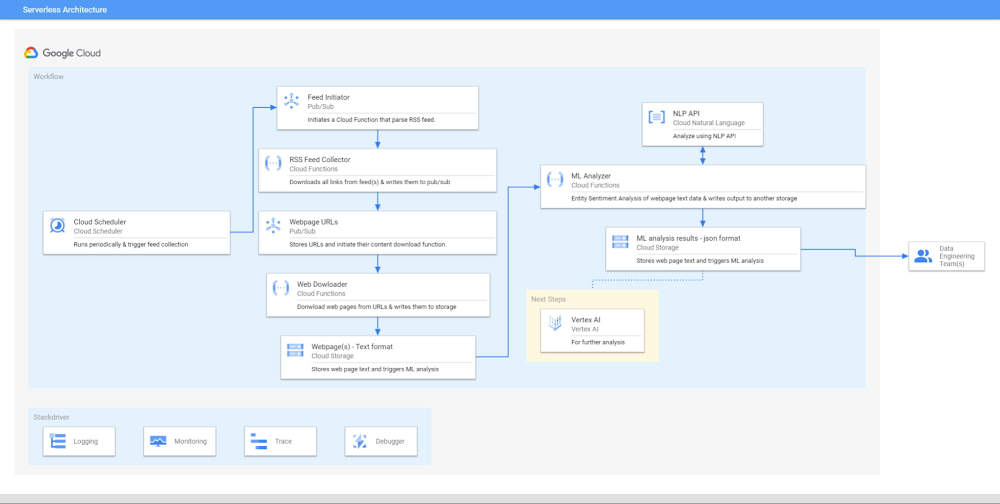
Today, many developers want to design applications using an event-driven architecture (EDA). This software architecture paradigm promotes the production, detection, consumption of, and reaction to events. It’s an architectural pattern best applied to design and implement applications and systems that transmit events among loosely-coupled software components and services. You can build event-driven applications using Cloud Functions, our Functions-as-a-Service (FaaS) product, leveraging events and triggers. Events are all kinds of activities or things like changes to data in a database, files added to a storage system, or a new virtual machine instance being created etc., that happens within your cloud environment that you might want to take action on. You can evoke a function when any events occur via a trigger. Cloud Functions offers scalable pay-as-you-go functions as a service (FaaS) that can run your code with zero server management, and can work in events and triggers.This blog explains how you can use Cloud Functions, events, and triggers together to help build scalable event-driven architecture. Using an example of a recent news event, we’ll explain the architecture and the step-by-step process of building an entity-sentiment metadata repository for all known entities (such as person, location, organization, event, consumer goods, etc.) using Cloud Functions, events, triggers, and the Natural Language API. You can then use this repository to determine the sentiment (positive or negative) expressed about different entities within the news. For example, Google Cloud Next ‘21 took place October 12-14, 2021, where there were discussions about a broad range of Google Cloud products. Understanding how these products were received by various media outlets or developer blogs can be valuable information to understand the overall effectiveness of the event.Understanding Cloud Functions, events, and triggersBefore we go into our example, let’s review the various components of the architecture.Events are all kinds of activities or things like changes to data in a database, files added to a storage system, or a new virtual machine instance being created etc., that happen within a cloud environment that might require reactive action. Cloud Functions supports events from the following providers:HTTPCloud StorageCloud Pub/SubCloud FirestoreFirebase (Realtime Database, Cloud Storage, Analytics, Auth)Cloud LoggingFor example, a new message published to a Cloud Pub/Sub topic or a change to a Cloud Storage bucket can generate an event which can trigger an action. An event can result in a change to the application state. For example, when a customer purchases a product, the product state changes from “available” to “sold”. In addition to these primary event sources, many other sources may provide messages via Pub/Sub, such as Cloud Build notifications, or Cloud Scheduler Jobs.There are two distinct types of Cloud Functions: HTTP functions, and event-driven functions. Further, event-driven functions can be either background functions or CloudEvent functions, depending on which Cloud Functions runtime they are written for.HTTP functionsHTTP functions can be invoked from standard HTTP requests. Clients sending these HTTP requests wait for the response synchronously, and HTTP functions can support handling of common HTTP request methods like GET, PUT, POST, DELETE, and OPTIONS. Event-driven functionsCloud Functions can use event-driven functions to handle events from your Cloud infrastructure, such as messages on a Pub/Sub topic, or changes in a Cloud Storage bucket. Cloud Functions supports two sub-types of event-driven functions:Background functions: Event-driven functions written for the Node.js, Python, Go, and Java Cloud Functions runtimes are known as background functions. See Writing Background Functions for more details.CloudEvent functions: Event-driven functions written for the .NET, Ruby, and PHP runtimes are known as CloudEvent functions. See Writing CloudEvent Functions for more details.Event-driven functions such as Background Functions and CloudEvent Functions can be used when Cloud Functions are invoked indirectly in response to an event, such as a message on a Pub/Sub topic, a change in a Cloud Storage bucket, or a Firebase event. CloudEvent functions are conceptually similar to background functions. The principal difference between the two types of functions is that CloudEvent functions use an industry-standard event format known as CloudEvents. Another difference is that Cloud Functions itself can invoke CloudEvent functions using HTTP requests, which can be reproduced in other compute platforms. Taken together, these differences can enable CloudEvent functions to be moved seamlessly between compute platforms.We will use CloudEvent functions throughout this blog to build a demo that explains how to build event-driven architectures using Cloud Functions.Understanding event-driven architecture (EDA)Event-driven architecture (EDA) is a software architecture paradigm promoting the production, detection, consumption of, and reaction to events. This architectural pattern can be best applied to design and implement applications and systems that transmit events among loosely coupled software components and services. Putting everything together with an exampleThis example focuses on creating an event-driven architecture to build a service that analyzes RSS feeds content using managed services like Cloud Functions (event-driven), Cloud Scheduler, and the Google Cloud Machine Learning APIs.Goal With this example, we want to collect, analyze, and store RSS feeds and their Entity Sentiment Analysis at a given interval every day, using Machine Learning APIs. Entity Sentiment Analysis combines both entity analysis and sentiment analysis and attempts to determine the sentiment (positive or negative) expressed about entities within the text. This can be useful when:You want to identify all the entities like product, company, or person mentioned in any blog or news article.You want to discover sentiment expressed about the entity. With these kinds of use cases, data engineering teams can look at recent trends like entities mentioned the most in news, and their sentiment to understand how they are perceived in the market. Architecture:Click to enlargeThe above architecture illustrates the workflow of how an RSS feed can be analyzed as soon as it is collected. Here is the logic: Step 1: One RSS feed link will contain one or many URLs. Write a function to parse these URLs from RSS feed links and store them in a queue. Step 2: Write a function that reads URLs from the queue in Step 1, one by one, and download their web page contents. Store all web page contents in persistent storage.Step 3: Finally, write another function that reads web page contents from stored persistent storage in Step 2, analyze them, and write the results to another persistent storage target. Here is a step-by-step process to build the above steps using Google Cloud managed services: Step 1: Cloud Scheduler writes a sample message to Pub/Sub. This is just to invoke a cloud function that is configured to start as soon as this event occurs.A configuration like above writes a message to a Pub/Sub topic at 5 AM PDT every day. Step 2: An RSS feed contains one or many web page URLs. A message written to Pub/Sub in Step 1 triggers a cloud function that downloads the contents of the RSS feed and parses a list of web page URLs from its content. These URLs are then written to another Pub/Sub topic for further processing.With a configuration such as the one above, Cloud Functions starts executing at 5AM when the scheduler event arrives via the Pub/Sub trigger.Here is sample code written in C#, .NET core 3.1, to parse RSS feed(s) and collect web page URLs from it.Function PublishMessageWithRetrySettingsAsync can be found here.Step 3: A URL entry written to Pub/Sub in Step 2 triggers a new cloud function that downloads web page text and writes the text to a Cloud Storage bucket.With a configuration like the one above, a cloud function will execute for each web page URL collected from the RSS feed and written to Pub/Sub in Step 2. Here is sample code written in Python 3.9 to download web page text and store it in Cloud Storage. BeautifulSoup library is used to parse web pages and extract text.Step 3 will result in web page text stored in Cloud Storage as shown below:Step 4:A new file creation event in Step 3 triggers a new cloud function that does entity sentiment analysis on the web page text and writes results to another Cloud Storage bucket.With a configuration like this, a cloud function will execute for each web page text downloaded and stored in a Cloud Storage bucket.Here is sample code written in Nodejs 14 to read data from a Cloud Storage bucket, parse the download web page text, and store it in Cloud Storage.analyzeEntitySentiment function does Entity Sentiment Analysis. Natural Language API has several methods for performing analysis and annotation on text data. Here are examples of how to perform analysis on text data using Natural Language API.The analysis data collected can be used by data engineering teams to find out answers to questions like: ‘Which entities (person, product etc) were discussed the most in recent times?’ and ‘What is the sentiment associated with these entities?’ These questions can help in understanding the overall effectiveness of existing marketing campaigns or latest trends, to help create better marketing or public relations campaigns. Resources:All logs from above services will be available in Cloud Logging. Cloud Functions can be tested and debugged locally. All services are loosely coupled. Vertex AI can be used to analyze the meta data collected at the end..Summary: Cloud Functions can be powerful services that can be used to build event-driven applications with minimal effort. The above walkthrough demonstrates Cloud Functions events, trigger integrations with different Google Cloud services, and its multi-language support. To get started, check out the references below.References:Calling Cloud FunctionsTesting Event-Driven FunctionsCloud Functions Local DevelopmentDeploying Cloud FunctionsRelated ArticleTips for writing and deploying Node.js apps on Cloud FunctionsFollow these tips for writing performant, observable, Node.js applications that run on Cloud Functions.Read Article
Quelle: Google Cloud Platform