TechEd 2021: What’s new for SAP customers on Google Cloud
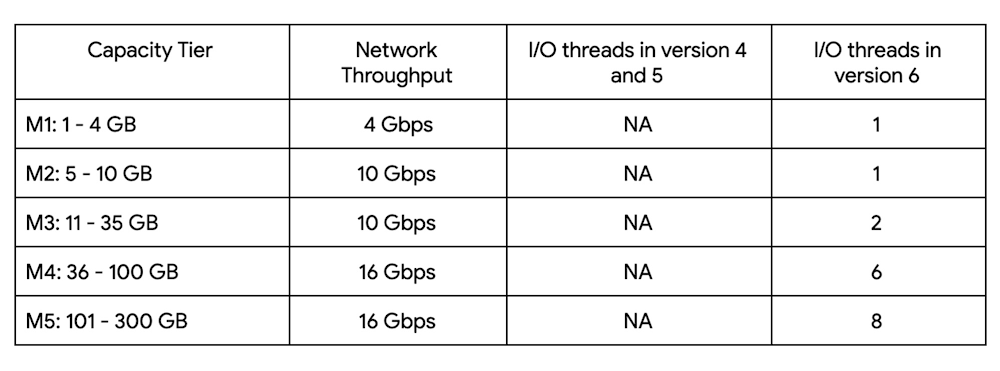
SAP’s TechEd 2021 is the premier developer and IT-focused virtual event for any business that runs — or is planning to run — SAP applications, and it gets under way this week. What better time to take stock and share how, together, we’re creating value for SAP customers? For Google Cloud, 2021 has easily been the most productive year in our working relationship with SAP, as we continue our joint focus on helping enterprises complete their journey to the cloud as quickly and successfully as possible. In the last 12 months alone, we’ve added three times the number of SAP customers as the year prior. Here’s what new and what’s just ahead for SAP customers on Google Cloud: Google Cloud rollouts for SAP Business Technology PlatformWe’re excited to announce that a new instance of SAP Business Technology Platform (BTP) is now available on Google Cloud, and we’re kicking off our BTP rollouts in North America and Europe during Q4 of 2021. This will be followed by BTP rollouts for our customers in Asia Pacific Japan (APJ) with a BTP instance available in India during Q1 of 2022.SAP Business Technology Platform enables SAP customers to move quickly to leverage the cloud, even for relatively complex use cases. And it puts an emphasis on freedom of choice by allowing customers to choose the right blend of cloud solutions to address their unique needs — and to pivot quickly with new capabilities as those needs change.Perhaps most important, running BTP (or any other set of SAP technologies) on Google Cloud gives customers the benefits of operating on the industry’s most extensive, fully owned and operated, global network infrastructure. That gives SAP customers some unique and very important network security and latency advantages.HANA Cloud to launch on Google CloudSAP’s fully managed HANA Cloud is an important component of SAP’s cloud portfolio, offering a database that can serve OLTP, OLAP, and xOLTP use cases. Like any business-critical application running in the cloud, it’s important to ensure that HANA Cloud delivers flawless performance — something that can be a major challenge for SAP customers looking to minimize network latency.That makes Google Cloud, with its low-latency global networking capabilities and flexible Compute Engine application platform, an ideal partner for SAP customers running HANA Cloud as part of their SAP portfolio. HANA Cloud also provides data virtualization capabilities with BigQuery, allowing customers flexibility in managing their enterprise data footprint. We’re pleased to announce that HANA Cloud is officially launched on Google Cloud in North America, with expansion to EMEA customers expected later this quarter (Q4 2021). We’re also launching HANA Cloud on Google Cloud for our APAC customers, with a rollout in India planned for early 2022.Even SAP customers who aren’t currently Google Cloud customers can take advantage of our HANA Cloud rollout — giving them the same performance and latency benefits even if they choose to run other SAP applications on other hyperscalers or within on-premises environments.Filestore Enterprise for RISE with SAPAnother key element of our SAP partnership centers on RISE with SAP — a “business transformation as a service” offering that gives enterprises a faster, lower-risk strategy for migrating their SAP environments to the cloud. Now, SAP is integrating our Filestore Enterprise technology as a standard part of RISE with SAP S/4HANA Cloud, private edition solutions. With its 99.99% regional-availability SLA, Filestore Enterprise is a fully-managed, cloud-native NFS solution designed for applications that demand high availability. With a few clicks (or a few lines of gCloud CLI or API calls), you can simply provision NFS shares that are synchronously replicated across three zones within a region. Filestore also lets you take periodic snapshots of the file system, and easily recover an individual file or an entire file system in less than 10 minutes from any prior snapshot recovery points.For HEC/RISE with SAP customers, Filestore Enterprise will be an important capability in terms of ensuring high availability, high performance, high levels of redundancy, and higher SLAs for business-critical SAP applications. It’s another way to give SAP customers a simpler, lower-risk path to the cloud.VPC Network Peering: More value for RISE with SAPFinally, we wanted to call out an existing Google Cloud capability with significant benefits for RISE with SAP customers: VPC Network Peering.When SAP implements a PCE or HEC environment on Google Cloud, it also manages the VPC — a virtualized network that provides the same functionality, performance, and security benefits as a dedicated physical network — for that environment. When you connect your SAP environment with Google Cloud services and applications through VPC Network Peering, the traffic between peered VPC networks remains securely within Google’s network. This is a big advantage for customers concerned with protecting business-critical SAP applications and data while connecting seamlessly to other applications running on Google Cloud.A partnership built to create lasting valueAll of these announcements build on the things that already make Google Cloud a natural partner for SAP customers: security, reliability, flexibility, and freedom of choice. Best of all, as a trusted partner in this journey with SAP and its customers, we know that even bigger successes are coming on the road ahead. Learn more about Google Cloud solutions for SAP customers.
Quelle: Google Cloud Platform