Coop reduces food waste by forecasting with Google’s AI and Data Cloud
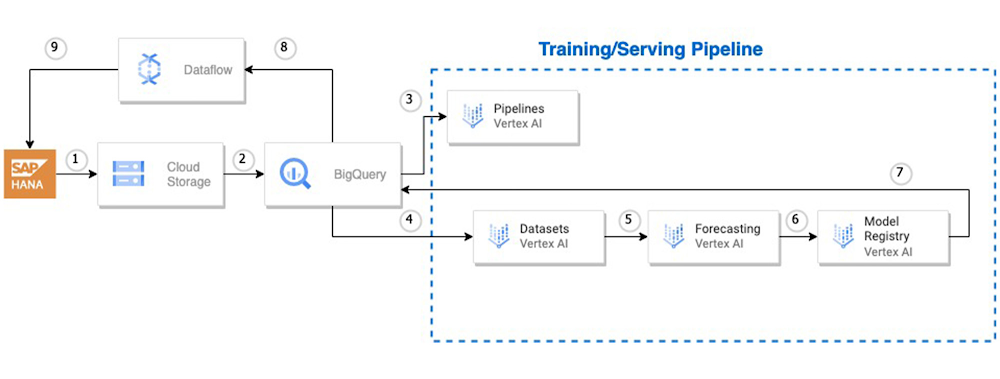
Although Coop has a rich history spanning nearly 160 years, the machine learning (ML) team supporting its modern operations is quite young. Its story began in 2018 with one simple mission: to leverage ML-powered forecasting to help inform business decisions, such as demand planning based on supply chain seasonality and expected customer demand. The end goal? By having insight into not only current data but also projections of what could happen in the future, the business can optimize operations to keep customers happy, save costs, and support its sustainability goals (more on that later!).Coop’s initial forecasting environment was one on-premises workstation that leveraged open-source frameworks such as PyTorch and TensorFlow. Fine tuning and scaling models to a larger number of CPUs or GPUs was cumbersome. In other words, the infrastructure couldn’t keep up with their ideas.So when the question arose of how to solve these challenges and operationalize the produced outcomes beyond those local machines, Coop leveraged the company’s wider migration to Google Cloud to find a solution that could stand the test of time.Setting up new grounds for innovationOver a two-day workshop with the Google Cloud team, Coop kicked things off by ingesting data from its vast data pipelines and SAP systems to BigQuery. At the same time, Coop’s ML team implemented physical accumulation cues of incoming new information and sorted out what kind of information this was. The team was relieved to not have to worry about setting up infrastructure and new instances.Next, the Coop team turned to Vertex AI Workbench to further develop its data science workflow, finding it surprisingly fast to get started. The goal was to train forecasting models to support Coop’s distribution centers so they could optimize their stock of fresh produce based on accurate numbers. Achieving higher accuracy, faster, to better meet customer demandDuring the proof-of-concept (POC) phase, Coop’s ML team had two custom-built models competing against an AutoML-powered Vertex AI Forecast model, which the team ultimately operationalized on Vertex AI: a single Extreme Gradient Boosting model and a Temporal Fusion Transformer in PyTorch. The team established that using Vertex AI Forecast was faster and more accurate than training a model manually on a custom virtual machine (VM).On the test set in the POC, the team reached 14.5 WAPE (Weighted Average Percentage Error), which means Vertex AI Forecast provided a 43% performance improvement relative to models trained in-house on a custom VM.After a successful POC and several internal tests, Coop is building a small-scale pilot (to be put live in production for one distribution center) that will conclude with the Coop ML team eventually streaming back the forecasting insights to SAP, where processes such as carrying out orders to importers and distributors take place. Upon successful completion and evaluation of the small-scale pilot in production in the next few months, they could possibly scale it out to full blown production across distribution centers throughout Switzerland. The architecture diagram below approximately illustrates the steps involved in both stages. The vision is of course to leverage Google’s data and AI services, including forecasting and post-forecasting optimization, to support all of Coop’s distribution centers in Switzerland in the near futureLeveraging Google Cloud to increase the relative forecasting accuracy by 43% over custom models trained by the Coop team can significantly affect the retailer’s supply chain. By taking this POC to pilot and possibly production, the Coop ML team hopes to improve its forecasting model to better support wider company goals, such as reducing food waste.Driving sustainability by reducing food wasteCoop believes that sustainability must be a key component of its business activity. With the aim to become a zero-waste company, its sustainability strategy feeds into all corporate divisions, from how it selects suppliers of organic, animal-friendly, and fair-trade products to efforts for reducing energy, CO2 emissions, waste materials, and water usage in its supply chains. Achieving these goals boils down to an optimal control problem. This is known as a Bayesian framework: Coop must carry out quantile inference to determine the scope of its distributions. For example, is it expecting to sell between 35 and 40 tomatoes on a given day, or is its confidence interval between 20 and 400? Reducing this amount of uncertainty with more specific and accurate numbers means Coop can order the precise number of units for distribution centers, ensuring customers can always find the products they need. At the same time, it prevents ordering in excess, which reduces food waste. Pushing the envelope of what can be achieved company-wideHaving challenged its in-house models against the Vertex AI Forecast model in the POC, Coop is in the process of rolling out a production pilot to one distribution center in the coming months, and possibly all distribution centers across Switzerland later thereafter. In the process, one of the most rewarding things was realizing that the ML team behind the project could use different Google Cloud tools, such as Google Kubernetes Engine and BigQuery, and Vertex AI to create its own ML platform. Beyond using pre-trained Vertex AI models, the team can automate and create data science workflows quickly so it’s not always dependent on infrastructure teams.Next, Coop’s ML team aims to use BigQuery as a pre-stage for Vertex AI. This will allow the entire data streaming process to flow more efficiently, serving data to any part of Vertex AI when needed. “The two tools integrate seamlessly, so we look forward to trying that combination for our forecasting use cases and potentially new use cases, too. We are also exploring the possibility of deploying different types of natural language processing-based solutions to other data science departments within Coop that are relying heavily on TensorFlow models,” says Martin Mendelin, Head of AI/ML Analytics, Coop. “By creating and customizing our own ML platform on Google Cloud, we’re creating a standard for other teams to follow, with the flexibility to work with open-source programs but in a stable, reliable environment where their ingenuity can flourish,” Mendelin adds. “The Google team went above and beyond with its expertise and customer focus to help us make this a reality. We’re confident that this will be a nice differentiator for our business.”
Quelle: Google Cloud Platform