Cloud CISO Perspectives: February 2022
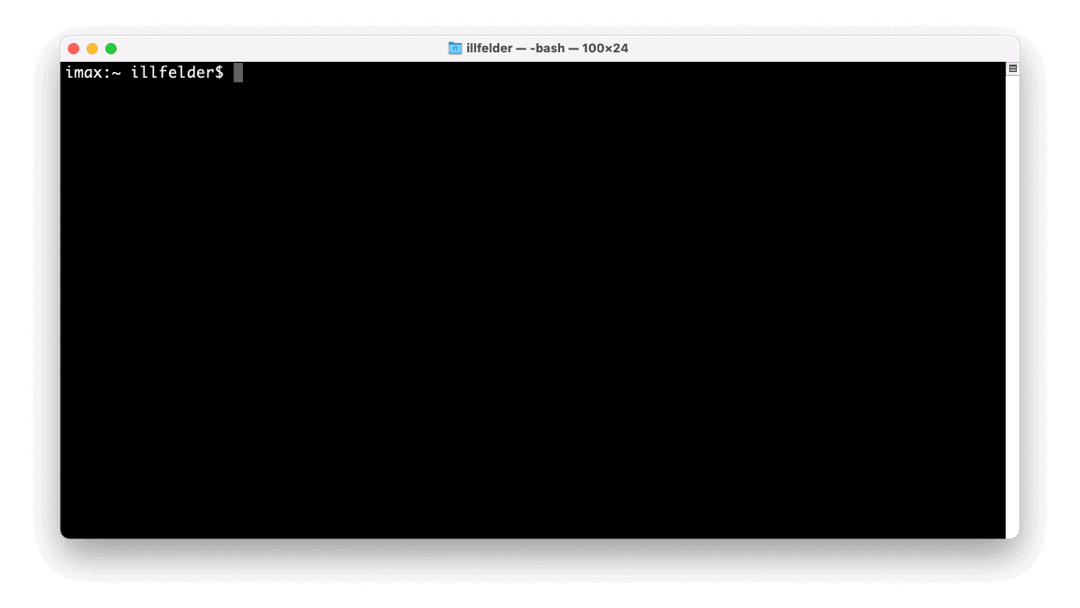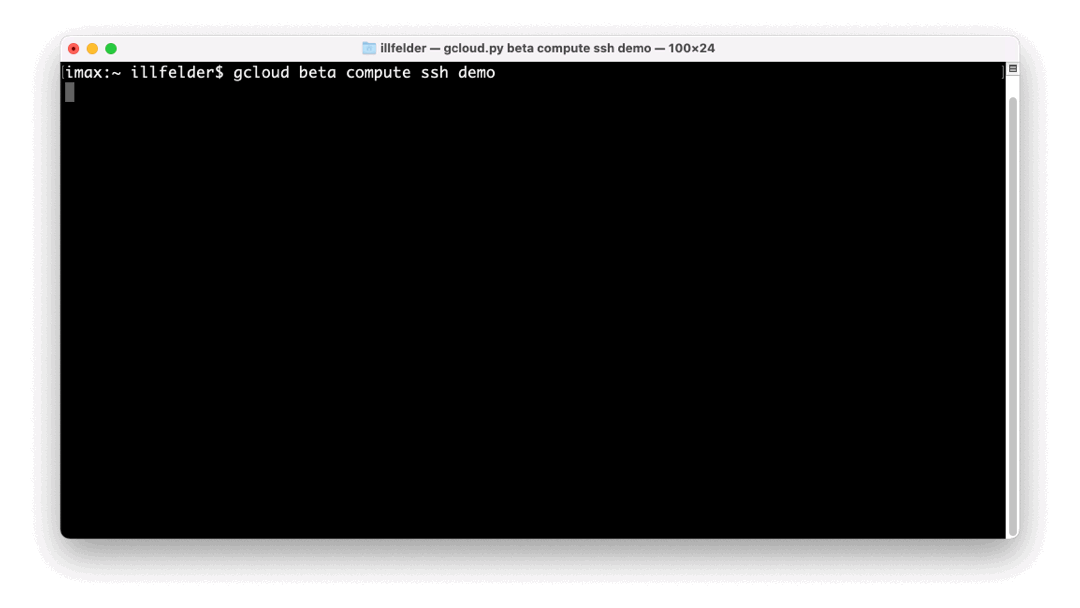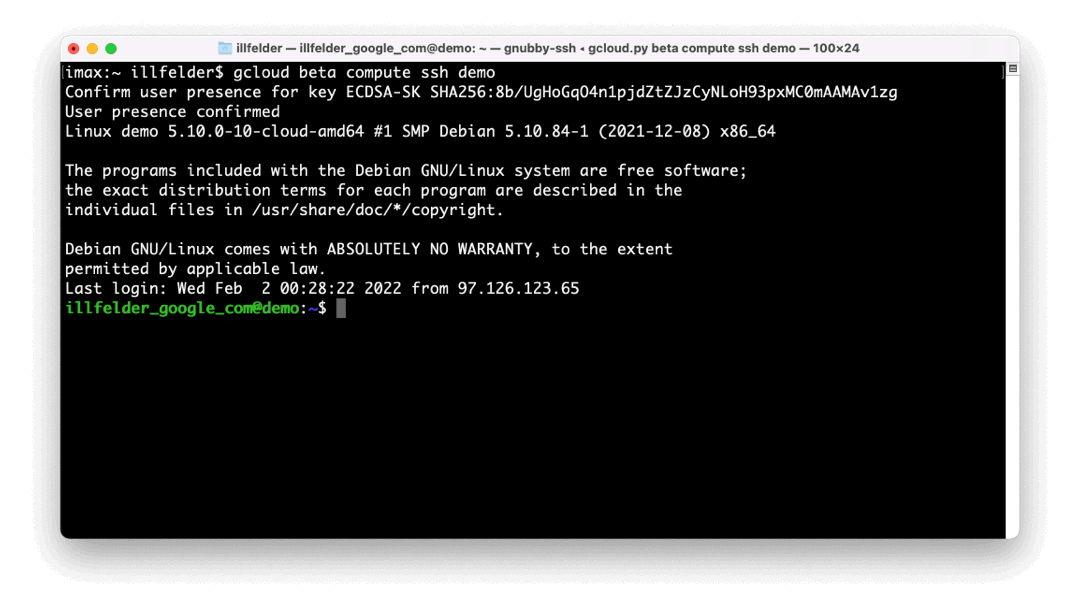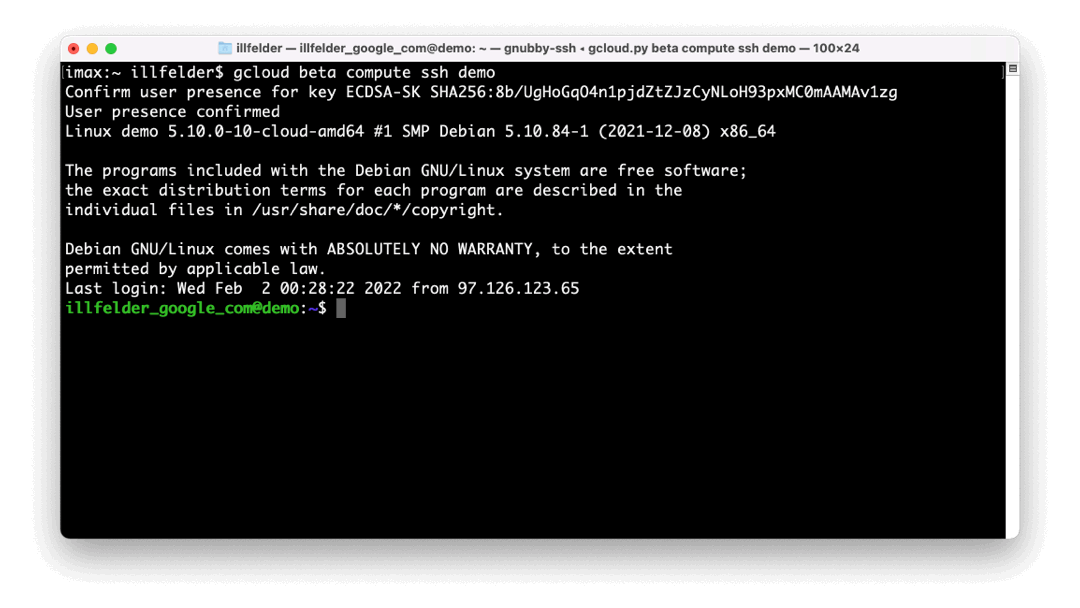
As the war in Ukraine continues to unfold, I want to update you on how we’re supporting our customers and partners during this time. Google is taking a number of actions. Our security teams are actively monitoring developments, and we offer a host of security products and services designed to keep customers and partners safe from attacks. We have published security checklists for small businesses and medium-to-large enterprises, to enable entities to take necessary steps to promote resilience to malicious cyber activity.Below, I’ll recap the latest efforts from the Google Cybersecurity Action Team such as our second Threat Horizons Report, and highlight new capabilities from our cloud security product teams who have been working to deliver new controls, security solutions and more to earn the trust of our customers globally. Munich Cyber Security ConferenceEarlier this month, I joined a panel at the Munich Cyber Security Conference (Digital Edition) to discuss supply chain risks and cyber resiliency. It was great to see a packed agenda featuring diverse voices from the security industry along with government leaders and policymakers coming together to discuss the challenges we’re working to collectively solve in cybersecurity. One area of particular focus is securing the software supply chain. During the panel, we talked about Google’s approach to building our own internal software and incorporating open source code in a secure way. This has been the foundation of our BeyondProd approach.We implement multiple layers of safeguards like multi-party change controls and a hardened build process that produces digitally signed software that our infrastructure explicitly validates before executing. We’ve since turned this into an open framework that all organizations can use to assess themselves and their supply chains: SLSA. How we collectively as an industry secure the software supply chain and prevent vulnerabilities in open source software will continue to be critical for cloud and SaaS providers, governments and maintainers throughout 2022. Google Cloud Security Talks On March 9, we’ll host our first Cloud Security Talks of 2022 that will focus on how enterprises can modernize their approach to threat detection and response with Google Cloud. Sessions will highlight how SecOps teams can leverage our threat detection, investigation and response capabilities across on-premise, cloud, and hybrid environments, including new SOAR capabilities from our recent acquisition of Siemplify. Registerhere. Google Cybersecurity Action Team Highlights Here are the latest updates, products, services and resources from our cloud security teams this month: Security FIDO security key support for GCE VMs: Physical security keys can now be used to authenticate to Google Compute Engine virtual machine (VM) instances that use our OS Login service for SSH management. Security keys offer some of the strongest protection against phishing and account takeovers and are strongly recommended in administrative workflows like this.IAM Conditions and Tags support in Cloud SQL: We introduced IAM Conditions and Tags in Cloud SQL which bring powerful new capabilities for finer-grained administrative and connection access control for Cloud SQL instances. Achieving Autonomic Security Operations: Anton Chuvakin and Iman Ghanizada from the Cybersecurity Action Team shared their latest blog post on how organizations can achieve Autonomic Security Operations by leveraging key learnings from SRE principles. The post highlights multiple ways automation can serve as a force multiplier to achieve better outcomes in your SOC.Certificate Manager integration with External HTTPS Load Balancing: We released the public preview of our Certificate Manager service and integration with External HTTPS Load Balancing to help simplify the way you deploy HTTPS services for your customers. You can bring your own TLS certificates and keys if you have an existing certificate lifecycle management solution or use Google Cloud’s fully managed TLS offerings. Another helpful feature of this release is integration of alerts on certificate expiry into Cloud Logging.Virtual Machine Threat Detection: The cloud is impacted by unique threat vectors but also offers novel opportunities to build effective detection into the platform natively. This dynamic underpins our latest Security Command Center Premium capability: Virtual Machine Threat Detection (VMTD). VMTD helps ensure strong protection for VM-based workloads by providing agentless memory scanning that can detect threats like cryptomining malware inside your Google Compute Engine VMs.Chrome Browser Cloud Management: A large part of enterprise security is protecting endpoints that access the web overall and a big part of this is not only using a secure browser like Chrome, but also how you get to manage and support that. We have a lot of these capabilities in Chrome Browser Cloud Management along with our overall zero trust approach. We also recently extended CIS benchmark coverage to include Chrome. Google Cloud architecture diagramming tool: We recently launched the brand new Google Cloud Architecture Diagramming Tool. This is an awesome tool for cloud architects, developers and security teams alike, and it’s another opportunity for us to be helpful in providing pre-baked reference architectures into the tools. Watch out for more on this as we build in more security patterns. Some of the Best Security Tools Might Not be “Security Tools”: Remember, there are many problems in risk management, security and compliance that don’t need specialist security tools. In fact some of the best tools might be from our data analysis and AI stacks such as our Vertex AI capability. Check out these new training features from the team. Stopping website attacks with reCAPTCHA Enterprise: reCAPTHA Enterprise is a great solution that mitigates many of the issues in the OWASP Automated Threat Handbook and can be deployed seamlessly for your website. Industry updatesOpen source software security: Just a few weeks after technology companies (including Google) and industry foundations convened at the White House summit on open source security, the OpenSSFannounced the Alpha-Omega project. The project aims to help improve software supply chain security for 10,000 OSS projects through direct engagement of software security experts and automated testing. Microsoft and Google are supporting the Alpha-Omega Project with an initial investment of $5 million. Building cybersecurity resilience in healthcare: Taylor Lehmann and Seth Rosenblatt from Google’s Cybersecurity Action team recently outlined best practices healthcare leaders can adopt to build resilience for IT systems, overcome attacks to improve both security and business outcomes, and above all, protect patient care and data. Threat IntelligenceThreat Horizons Report Issue 2: Providing timely, actionable cloud threat intelligence to our customers so they can take action to protect their environments is critical and this is the aim of our Threat Horizons report series. Customers benefit from guidance on how to securely use and configure the cloud, which is why we operate within a “shared fate” model that exemplifies a true partnership with our customers regarding their security outcomes. In the latest Google Cybersecurity Action Team Threat Horizons Report, we observed vulnerable instances of Apache Log4j are still being sought by attackers, which requires continued vigilance by customers and cloud providers alike in ensuring patching is effective. Additionally, Google Cloud Threat Intelligence has observed that the Sliver framework is being used by adversaries post initial compromise in attempts to ensure they maintain access to networks. Check out the fullreport for this month’s findings and best practices you can adopt to stay protected against these and other evolving threats.ControlsAssured Workloads for EU: Organizations around the world need confidence they can meet their unique and evolving needs for security, privacy, and digital sovereignty as they use cloud services. Assured Workloads for EU, now GA, allows GCP customers to create and maintain workloads with data residency in their choice of EU Google Cloud regions, personnel access and customer support restricted to EU persons located in the EU, and cryptographic control over data access using encryption keys stored outside Google Cloud infrastructure.Client Authorization for gRPC Services with Traffic Director: One way developers use the open source gRPC framework is for backend service-to-service communications. The latest release of Traffic Director now supports client authorization by proxyless gRPC services. This release, in conjunction with Traffic Director’s capability for managing mTLS credentials for Google Kubernetes Engine (GKE) enables customers to centrally manage access between workloads using Traffic Director.Don’t forget to sign-up for our newsletter if you’d like to have our Cloud CISO Perspectives post delivered every month to your inbox. We’ll be back next month with more updates and security-related news.Related ArticleCloud CISO Perspectives: January 2022Google Cloud CISO Phil Venables shares his thoughts on the latest security updates from the Google Cybersecurity Action Team.Read Article
Quelle: Google Cloud Platform