Introducing Autonomic Security Operations for the U.S. public sector
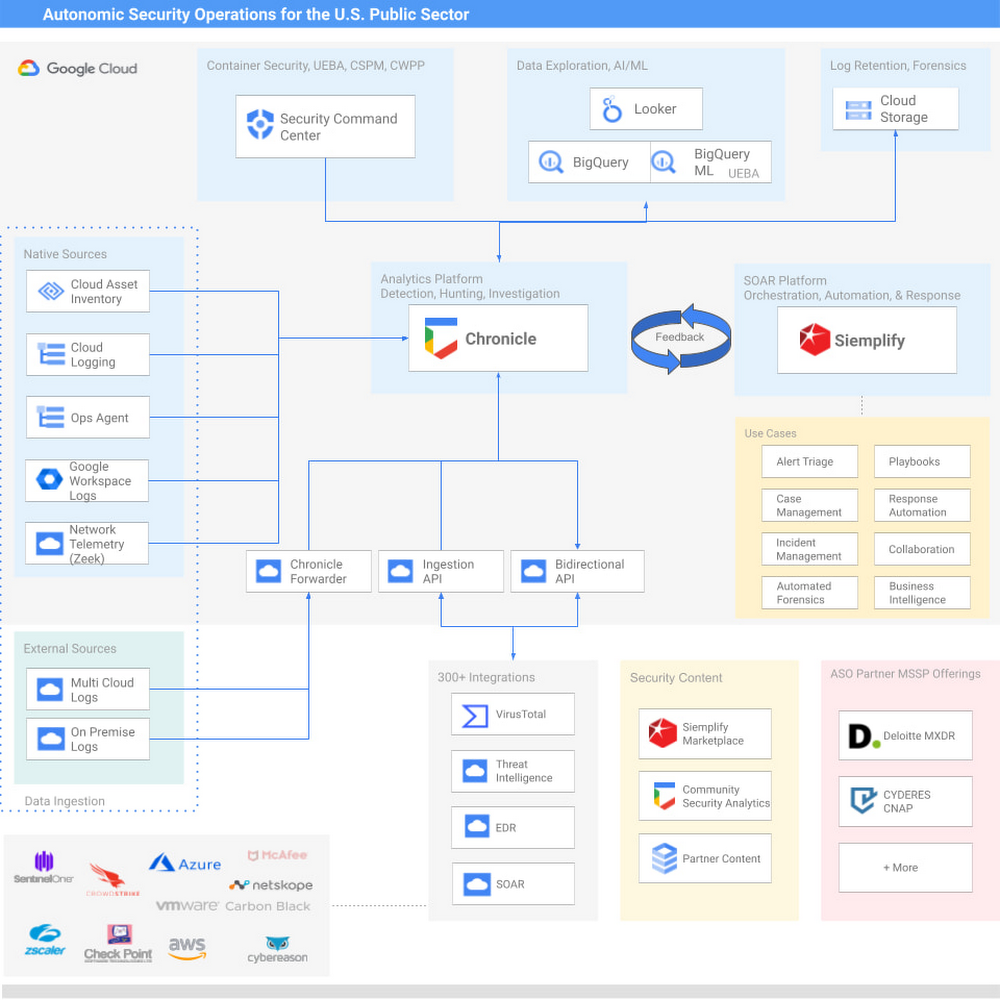
As sophisticated cyberattack campaigns increasingly target the U.S. public and private sectors during the COVID era, the White House and federal agencies have taken steps to protect critical infrastructure and remote-work infrastructure. These include Executive Order 14028 and the Office of Management and Budget’s Memorandum M-21-31, which recommend adopting Zero Trust policies, and span software supply chain security, cybersecurity threat management, and strengthening cyberattack detection and response.However, implementation can be a challenge for many agencies due to cost, scalability, engineering, and a lack of resources. Meeting the requirements of the EO and OMB guidance may require technology modernization and transformational changes around workforce and business processes. Today we are announcing Autonomic Security Operations (ASO) for the U.S. public sector, a solution framework to modernize cybersecurity analytics and threat management that’s aligned with the objectives of EO 14028 and OMB M-21-31. Powered by Google’s Chronicle and Siemplify, ASO helps agencies to comprehensively manage cybersecurity telemetry across an organization, meet the Event Logging Tier requirements of the White House guidance, and transform the scale and speed of threat detection and response. ASO can support government agencies in achieving continuous detection and continuous response so that security teams can increase their productivity, reduce detection and response time, and keep pace with – or ideally, stay ahead of – attackers. While the focus of OMB M-21-31 is on the implementation of technical capabilities, transforming security operations will require more than just technology. Transforming processes and people in the security organization is also important for long-term success. ASO provides a more comprehensive lens through which to view the OMB event logging capability tiers, which can help drive a parallel transformation of security-operations processes and personnel.Modern Cybersecurity Threat Detection and ResponseGoogle provides powerful technical capabilities to help your organization achieve the requirements of M-21-31 and EO 14028:Security Information & Event Management (SIEM) – Chronicle provides high-speed petabyte-scale analysis, and is capable of consuming log types outlined in the Event Logging (EL) tiers in a highly cost-effective manner.Security Orchestration, Analytics, and Response (SOAR) – Siemplify offers dozens of out-of-box playbooks to deliver agile cybersecurity response and drive mission impact, including instances of automating 98% of Tier-1 alerts and driving an 80% reduction in caseload.User and Entity Behavior Analytics (UEBA) – For agencies that want to develop their own behavioral analytics, agencies can use BigQuery, Google’s petabyte scale data lake, to store, manage, and analyze diverse data types from many sources. Telemetry can be exported out of Chronicle, and custom data pipelines can be built to import other relevant data from disparate tools and systems, such as IT Ops, HR and personnel data, and physical security data. From there, users can leverage BQML to readily generate machine learning models without needing to move the data out of BigQuery. For Google Cloud workloads, our Security Command Center Premium product offers native, turnkey UEBA across GCP workloads.Endpoint Detection and Response (EDR)– For most agencies, EDR is a heavily adopted technology that has broad applicability in Security Operations. We offer integrations to many EDR vendors. Take a look at our broad list of Chronicle integrations here.Threat intelligence – Our solution offers a native integration with VirusTotal, has the ability to operationalize threat intelligence feeds natively in Chronicle, and integrates with various TI and TIP solutions.Community Security AnalyticsTo increase collaboration across public-sector and private-sector organizations, we recently launched our Community Security Analytics (CSA) repository, where we’ve partnered with the MITRE Engenuity Center for Threat-Informed Defense, CYDERES, and others to develop open-source queries and rules that support self-service security analytics for detecting common cloud-based security threats. CSA queries are mapped to the MITRE ATT&CK® framework of tactics, techniques and procedures (TTPs) to help you evaluate their applicability in your environment and include them in your threat model coverage.“Deloitte is excited to collaborate with Google Cloud on their transformational public sector Autonomic Security Operations (ASO) solution offering. Deloitte has been recognized as Google Cloud’s Global Services Partner of the Year for four consecutive years, and also as their inaugural Public Sector Partner of the Year in 2020,” said Chris Weggeman, managing director of GPS Cyber and Strategic Risk, Google Cloud Cyber Alliance Leader, Deloitte & Touche LLP. “Our deep bench of more than 1,000 Google Cloud certifications, capabilities spanning the Google Cloud security portfolio, and decades of delivery experience in the government and public sector makes us well-positioned to help our clients undertake critical Security Operations Center transformation efforts with Google Cloud ASO.”Cost-effective for government agenciesTo help Federal Agencies meet the requirements of M-21-31 and the broader EO, Google’s ASO solutions can drive efficiencies and help manage the overall costs of the transformation. ASO can make petabyte-scale data ingestion and management more viable and cost-effective. This is critical at a time when M-21-31 is requiring many agencies to ingest and manage dramatically higher volumes of data that had not been previously budgeted for. PartnersWe’re investing in key partners who can help support U.S. government agencies on this journey. Deloitte and CYDERES both have deep expertise to help transform agencies’ Security Operations capabilities, and we continue to expand our partners to support the needs of our clients. A prototypical journey can be seen below.“Cyderes shares Google Cloud’s mission to transform security operations, and we are honored to deliver the Autonomic Security Operations solution to the U.S. public sector. As the number one MSSP in the world (according to Cyber Defense Magazine’s 2021 Top MSSPs List) with decades of advisory and technology experience detecting and responding to the world’s biggest cybersecurity threats, Cyderes is uniquely positioned to equip federal agencies and departments to go far beyond the requirements of the executive order to transform their security programs entirely via Google’s unique ASO approach,” said Robert Herjavec, CEO of CYDERES. “As an original launch partner of Google Cloud’s Chronicle, our deep expertise will propel our joint offering to modernize security operations in the public sector, all with significant cost efficiency compared to competing solutions.” said Eric Foster, President of CYDERES.Embracing ASOAutonomic Security Operations can help U.S. government agencies advance their event logging capabilities in alignment with OMB maturity tiers. More broadly, ASO can help the U.S. government undertake a larger transformation of technology, process, and people, toward a model of continuous threat detection and response. As such, we believe that ASO can help address a number of challenges presently facing cybersecurity teams, from the global shortage of skilled workers, to the overproliferation of security tools, to poor cybersecurity situational awareness and analyst burnout caused by an increase of data without sufficient context or tools to automate and scale detection and response.We believe that by embracing ASO, agencies can help agencies achieve:10x technology, through the use of cloud-native tools that help agencies meet event logging requirements in the near term, while powering a longer-term transformation in threat management; 10x process, by redesigning workflows and using automation to achieve Continuous Detection and Continuous Response in security operations; 10x people, by transforming the productivity and effectiveness of security teams and expanding their diversity; and10x influence across the enterprise through a more collaborative and data-driven approach to solving security problems between security teams and non-security stakeholders.To learn more about Google’s Autonomic Security Operations solution for the U.S. public sector, please read our whitepaper. More broadly, Google Cloud continues to provide leadership and support for a wide range of critical public-sector initiatives, including our work with the MITRE Engenuity Center for Threat-Informed Defense, the membership of Google executives on the President’s Council of Advisors on Science and Technology and the newly established Cyber Safety Review Board; Google’s White House commitment to invest $10 billion in Zero Trust and software supply chain security, and Google Cloud’s introduction of a framework for software supply chain integrity. We look forward to working with the U.S. government to make the nation more secure.Visit our Google Cloud for U.S. federal cybersecurity webpage.Related posts:Autonomic Security Operations for the U.S. Public Sector Whitepaper“Achieving Autonomic Security Operations: Reducing toil”“Achieving Autonomic Security Operations: Automation as a Force Multiplier”“Advancing Autonomic Security Operations: New resources for your modernization journey”Related ArticleRead Article
Quelle: Google Cloud Platform