Assembling and managing distributed applications using Google Cloud Networking solutions
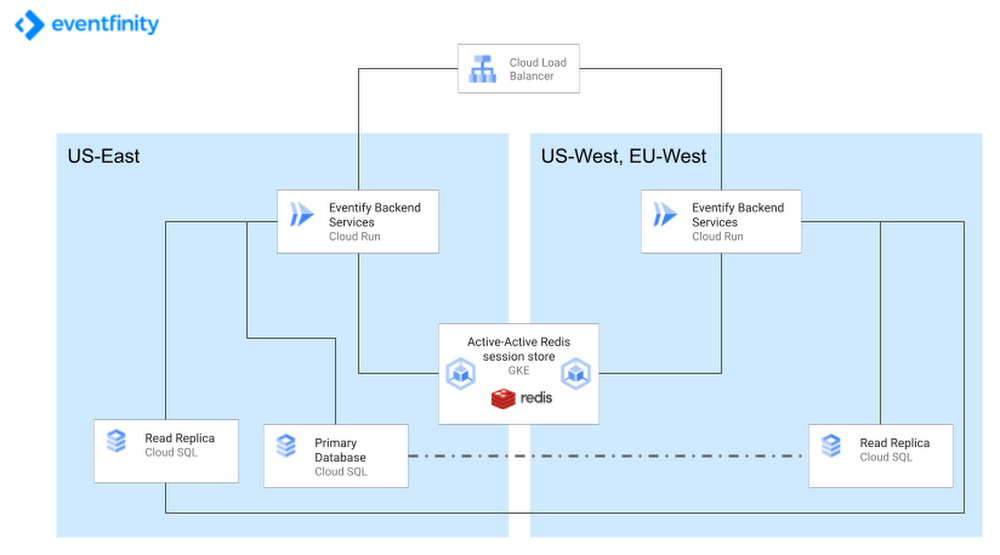
In the cloud era, modern applications are assembled from services running across different environments. The benefit of this approach is that organizations can choose which services to use that best serve their needs when building applications. But assembling applications from disparate component services also brings complexity, including:How to connect services together in a reliable and secure mannerEfficiently managing traffic in a consistent way across distributed servicesDefining clear boundaries between the teams that build services vs teams that consume themAs we discussed at the Google Cloud Networking Spotlight, Next-generation application delivery with Google Cloud, we recently introduced solutions to help you reduce the complexity of assembling and managing distributed applications. These solutions include three core networking solutions that allow you to more efficiently orchestrate services into cohesive applications, and include:New Cloud Load Balancers based on the Open Source Envoy Proxy. These Load Balancers give you common traffic management capabilities when using our fully-managed Load Balancers, or when using xDS-based solutions, such as the Envoy Proxy. Ultimately, these Load Balancers allow common traffic management capabilities to be used in services running across different environments.Hybrid Load Balancing and Hybrid Connectivity solutions that connect services across hybrid network environments, so that services work together no matter in which environment the services reside. These include connecting services together that run in Google Cloud, in multicloud environments, or on-premises.Private Service Connect, which allows you to more seamlessly connect services together across different networks. This solution also clearly separates the organizations that develop and maintain services (service producers) from organizations that use the services (service consumers).The Google Cloud networking stackfig 1. Overview of core Google Cloud network productsTo put these solutions into context, let’s first review a high-level overview of core Google Cloud network products.At the foundation of the Google Cloud product stack are connectivity solutions such as Network Connectivity Center, which includes physical Interconnects and VPNs that enable secure and reliable connectivity to on-premises and multicloud deployments into a single coherent connectivity layer.The next layer consists of cloud infrastructure tools that secure your network perimeter, allowing you to make enterprise-wide guarantees of what data can get in and out of your network. Layered on top of that, service networking products let your developers think in services. Instead of worrying about lower-level network constructs like IPs and ports, these tools let developers think in terms of assembling reusable services into business applications. At the top of the stack are application delivery solutions, allowing you to deliver applications at massive scale. These solutions include Cloud Load Balancers, CDN and Cloud Armor products. And wrapped around it all is Network Intelligence Center, a single-pane of glass view of what’s happening with your network.Together, these solutions are enable three primary Google Cloud Networking capabilities, including:Universal advanced traffic management with Cloud Load Balancing and the Envoy ProxyConnecting services across multicloud and on-premises hybrid network deploymentsSimplifying and securing service connectivity with Private Service ConnectFor the remainder of this blog we will explore these solutions in more detail, and how they work together to give your users the best experience consuming your distributed applications, wherever they are in the world.Advanced traffic management with Cloud Load Balancing and Envoy ProxyWe are excited to introduce our next generation of Google Cloud Load Balancers. They include a new version of our Global External HTTPS Load Balancer and a new Regional External HTTPS Load Balancer. These new load balancers join our existing Internal HTTPS Load Balancer and represent the next generation of our load balancer capabilities. These new Cloud Load Balancers use the Envoy Proxy, a Cloud Native Computing Foundation (CNCF) open source project, providing a consistent data plane and feature set that supports advanced traffic management.fig 2. Overview of the next generation Google Cloud Load BalancersOur next-generation Cloud Load Balancers provide new traffic management capabilities such as advanced routing and traffic policies so you can steer traffic with the flexibility required for complex workloads. A few examples of the advanced traffic management capabilities include:Request mirroring for use cases such as out-of-path feature validationWeighted traffic splitting for use cases such as canary testingFault injection to enable reliability validation such as chaos testingNew load balancing algorithms and session-state affinity optionsAnd because our next-generation Load Balancers are based on open-source technology, they can be used to modernize and efficiently manage services across distributed environments. For example, you can use our Cloud Load Balancers in conjunction with open source Envoy sidecar proxies running in a multicloud or on-premises environment to create a universal traffic control and data-plane solution across heterogeneous architectures. You can optionally use Traffic Director, a fully managed control plane for service mesh architectures to more efficiently manage traffic across xDS-compatible proxies, such as Envoy Proxies.For an example of how to use this universal traffic management architecture across distributed applications, imagine you want to roll out a new service that is used in a distributed system, for example, a shopping cart service that is used in multiple commerce applications. To properly canary-test the rollout, you can use the weighted backend service capability built into Cloud Load Balancers, and in Envoy Sidecar proxies managed by Traffic Director. Here, by incrementally varying the weights, you can safely deploy a new feature or version of a service across distributed applications in a coordinated and consistent manner, and enable uniform canary testing of a new service across your full architecture.fig 3. Canary testing across distributed applicationsHere are more resources for learning about advanced traffic management on Google Cloud:Overview of Google Cloud load balancersAdvanced Traffic management overview for global external HTTP(S) load balancersExternal HTTPs LB with Advanced Traffic Management (Envoy) CodelabSolutions for managing hybrid architectures, multicloud and on-premises deploymentsConsider when you have distributed applications that run on on-premises, inside Google Cloud or in other cloud or software-as-a-service (SaaS) providers. Hybrid Load Balancing and Hybrid Connectivity lets you bring the distributed pieces together. It helps you take a pragmatic approach to adapt to changing market demands and incrementally modernize applications, leveraging the best service available and ultimately providing flexibility to adapt to changing business demands. Hybrid Load Balancing intelligently manages and distributes traffic across a variety of distributed application use cases.fig 4. Hybrid Load Balancing and Hybrid Connectivity use casesGoogle Cloud Hybrid Load Balancing and Hybrid Connectivity solutions include components designed to securely and reliably connect services and applications across different networks. These connectivity options include private Interconnects (Partner & Direct), VPN, or even the public internet, so you can use both private and public connectivity to assemble application services. And our Cloud Load Balancers can manage traffic regardless of where the backend services reside.fig 5. Hybrid Load Balancing deploymentsHybrid Load Balancing and Connectivity can be combined with our next generation of Google Cloud Load Balancers to provide advanced traffic management across Google Cloud, on-premises and in multicloud distributed application deployments. Check out these resources for more on managing hybrid, multicloud and on-premises architectures:Hybrid Load Balancing overviewExternal HTTP(s) Hybrid load balancer CodelabSimplifying and securing connectivity with Private Service ConnectServices that are used across distributed applications are often authored and maintained by one team (service producers) and used by other teams building individual applications (service consumers). This approach provides significant benefits when assembling distributed applications as it enables service reuse and separation of roles for teams building and using services. However, there are also complexities connecting and managing these services across environments.Private Service Connect provides a network-agnostic connectivity layer and a built-in service ownership structure to efficiently reuse services across distributed applications. Private Service Connect provides a method of connecting two cloud networks together without peering and also without sharing IP address space — a seamless way of communicating with services within Google Cloud or across on-premises or multicloud deployments.Private Service Connect provides you with a private IP address from inside your VPC. You can use it to privately access Google services such as Google Cloud Storage or BigQuery, third-party SaaS services such as MongoDB or Snowflake, or even your own services that may be deployed across different VPCs within your organization.fig 6. Private Service Connect overviewPrivate Service Connect also lets you separate the concerns of consumers (the teams that initiate a connection to a service) from the producers (the teams offering a service to be connected to). Because these roles are built-in to Private Service Connect, you don’t have to go through the toil of defining your own organizational structure, but can simply leverage the identity and access permissions already available to you on Google Cloud. Here are more resources on Private Service Connect:Private Service Connect OverviewPrivate Service Connect CodelabConclusionWe hope the solutions presented here give engineers and cloud architects the tools to build robust distributed applications in a hybrid and multicloud environment at scale, allowing you to think less about the details of your network, and more about assembling applications from services that deliver the best value to your users. To learn more about these advanced use cases — and to see how our customers use Google Cloud Networking tools in action — register for our Networking Spotlight today May 24, or on demand thereafter.Related ArticleIntroducing Media CDN—the modern extensible platform for delivering immersive experiencesWe’re excited to announce the general availability of Media CDN — a content and media distribution platform with unparalleled scale.Read Article
Quelle: Google Cloud Platform