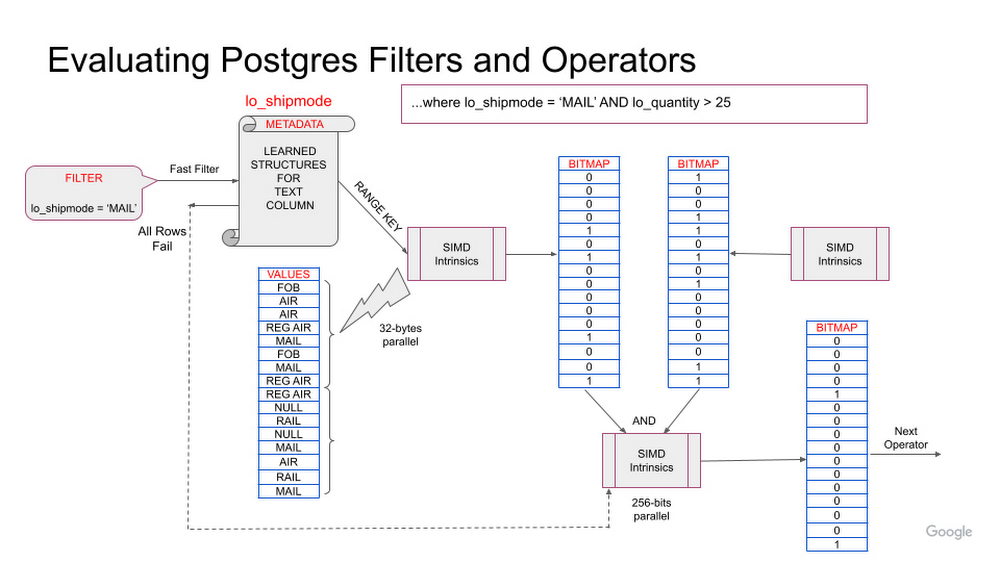
Recently, at Google I/O, we announced AlloyDB for PostgreSQL, a fully-managed, PostgreSQL-compatible database for demanding, enterprise-grade transactional and analytical workloads. Imagine PostgreSQL plus the best of the cloud: elastic storage and compute, intelligent caching, and AI/ML-powered management. Further, AlloyDB delivers unmatched price-performance: In our performance tests, it’s more than 4x faster on transactional workloads, and up to 100x faster on analytical queries than standard PostgreSQL, all with simple, predictable pricing. Designed for mission-critical applications, AlloyDB offers extensive data protection and an industry leading 99.99% availability SLA, inclusive of maintenance. Multiple innovations underpin the performance, and availability gains of AlloyDB for PostgreSQL. In the first part of our “AlloyDB for PostgreSQL under the hood” series, we discussed AlloyDB’s intelligent storage layer, and today, we are covering AlloyDB’s vectorized columnar execution engine, which enables analytical acceleration. PostgreSQL and hybrid workload patternsGeneral-purpose databases like PostgreSQL often support a wide variety of workloads. Some of those workloads are purely transactional in nature, and in the previous post, we discussed how our intelligent storage layer contributes to making AlloyDB more than 4x faster than standard PostgreSQL for such workloads based on our performance tests. However, PostgreSQL also has rich querying functionality that many users leverage both inside and outside of their applications. Analytical queries, i.e., queries involving scans, joins, and aggregations over a large amount of data, are a core part of many relational database workloads. These can include:Queries within an application that serves end-users, for example: an ecommerce application that shows most popular products segmented by region based on recent sales across multiple propertiesReal-time business insights for analysis that requires access to the most up-to-date data. For example: a recommendation engine in a retail application that shows suggested add-on purchases based on what the user has in their cart, the time of day, and historical purchase behaviorAd-hoc querying, where a developer or user might need to query the database directly to answer a question, for example, running an audit on recent transactions for a regulatorTuning operational databases to perform well in these varying use cases can be difficult. Historically, users with these types of workloads have had to create indexes and optimize schemas to ensure sufficient query performance. This not only increases management complexity, but can also impact transactional performance. Slow query performance can also constrain what developers are able to deliver to their end users, and deter development of real-time business insights.AlloyDB provides a better way. Powered by a columnar engine, AlloyDB performed up to 100x faster than standard PostgreSQL for analytical queries based on our performance tests, with no schema changes, application changes, or ETL required. This technology keeps frequently queried data in an in-memory, columnar format for faster scans, joins, and aggregations. The embedded machine learning in AlloyDB makes accessing this technology easier than ever. AlloyDB automatically organizes your data between row-based and columnar formats, choosing the right columns and tables based on learning your workload, and converting them to columnar format automatically. The query planner smartly chooses between columnar and row-based execution plans, so transactional performance is maintained. This allows AlloyDB to deliver excellent performance for a wide range of queries, with minimal management overhead.A refresher on column-oriented data representationTraditional databases are row-oriented and store data in fixed-sized blocks. This organization is optimal for access patterns that request information across a whole row, for example, when an application needs to look up information pertaining to a particular user. Row-oriented storage is optimized for these types of access patterns. Analytical queries require different access patterns. In order to answer analytical queries from a row-oriented data store, whole tables need to be scanned, reading through every column of every row, even though much of the data stored in the table is not relevant to answering the questions. Column-oriented data representation enables answering analytical questions faster, by keeping the values in a single column together. By focusing access to only the relevant columns, column-oriented databases can deliver faster responses to analytical queries.AlloyDB columnar engine Google has a long history of innovation in large-scale data analytics, especially with services like BigQuery. These services offer fast, scalable query processing through the use of optimized, columnar data layouts, state-of-the-art query processing techniques, and hardware acceleration. AlloyDB embeds some of the same technological advancements directly into a PostgreSQL-compatible operational database. It combines a row-based format for transactional processing and storage with a columnar format and execution engine to provide the best of both worlds.The columnar engine is a modern, vectorized query processing engine that efficiently processes chunks of columnar data by making optimal use of the system caches and vector processing instructions provided by today’s CPUs.Beyond leveraging the capabilities of modern hardware, the columnar engine includes several algorithmic optimizations to further speed up query processing. It makes use of column-specific metadata, such as minimum and maximum values, to speed up scans, and can perform other operations like aggregation directly on the relevant columns without materializing the results of a scan. Finally, hybrid execution combines both columnar and row-oriented query processing techniques where beneficial.Columnar data formatThe columnar engine intelligently determines the data format and metadata for each column; it learns from both the content of the column and the type of query operations that are executed. Learned metadata is used both to encode the data values efficiently and to accelerate query processing. For example, when a string column that has a small number of distinct values is used in filters, the columnar engine may decide to generate a list of the distinct values as metadata. This can then be used to accelerate both equality and range-based filters. As another example, the columnar engine may keep minimum and maximum values of a date column (for a given range of rows) as metadata; this may then be used to skip that range of rows when processing certain filters. In addition, the columnar engine may also use compression techniques to make efficient use of memory and speed up query processing. Query accelerationThe columnar engine transforms queries into a series of operations on columns and their metadata. Typically this involves first looking up the metadata to determine the most efficient type of operation to perform on an array of column values. These operations on column values, called vectorized operations, are designed to be executed using hardware-accelerated vectorized (SIMD) instructions that are available on modern CPUs.The columnar engine can also perform table scan operations efficiently without fully materializing the result of the table scan; for example, if an aggregation operation needs to be performed after a table scan, it may use the result of evaluating the filters to directly perform vectorized aggregation operations on the relevant columns. Join operations are transparently accelerated using bloom filters, depending on selectivity; this optimization uses the power of vectorized filtering to reduce the number of rows that need to be processed by the join operation.Let’s take a look at how some of these optimizations apply to a simple query involving a table scan based on a schema similar to the Star Schema benchmark. This query scans the list of sales, filtering by shipping mode and date. The following figure illustrates how the table scan with two filters is executed. For the filter lo_shipmode = ‘MAIL’, the columnar engine first checks the column’s metadata to see if the value ‘MAIL’ is present in this dataset. If ‘MAIL’ does occur, the columnar engine proceeds by searching using SIMD instructions. The resulting bitmap of passing rows is further filtered using the result set from the next filter. Alternatively, if the value ‘MAIL’ had not occured in the column metadata, the columnar engine could have skipped searching a large number of values. Similarly, the columnar engine may also use min/max metadata on the lo_quantity column to skip some rows based on the range filter on that column.Figure 1: Example query operation with table scans with two filtersAutomatic, intelligent data populationWe designed AlloyDB with automation in mind, given that workloads vary widely and workload characteristics change over time. AlloyDB uses machine learning (ML) techniques along with analytical models to intelligently select the best tables/columns to keep in columnar format, and provides mechanisms to automatically maintain this data in memory. It also determines the best format to use for the columnar data representation, and what metadata would be most useful for each column, based on the values in the column and the query operations performed on it. This allows end users to take advantage of columnar technology immediately, without evaluating the details of their queries. It also means that the columnar engine will continue to optimize performance as query patterns change.Query plan executionAfter the data is initially loaded into memory, AlloyDB monitors changes to the data and ensures that it is refreshed automatically. Depending on the data changes as well as the query operations being performed, it may be best to execute queries fully on columnar data, fully on row-oriented data, or a hybrid of the two. The AlloyDB query planner uses a costing model to automatically choose the best mode of execution for each node in the query plan.Figure 2: Hybrid scans can scan multiple columnar tables, and access the row-store at the same timeQuery performanceWhile we expect the columnar engine to significantly improve the performance of analytic queries in general, the magnitude of improvement will depend on the specific query. The largest improvements from the columnar engine can be seen for queries with selective filters on wide tables (tables with a large number of columns — as is typical in many analytic use cases) that access a small fraction of the columns in the table. Selective joins, especially with small tables, will also benefit significantly from the columnar engine, through the use of efficient bloom filtering. We are continuously innovating in this area and building new capabilities to broaden the performance impact of the columnar engine on different query patterns. To illustrate how the magnitude of the performance improvement varies based on the above factors, we compared performance with and without the columnar engine for a few example queries. These queries are based on the Star Schema benchmark, and were run with Scale factor = 10 on a 16-vCPU AlloyDB instance:Example 1: Get the total revenue from sales with a specific discount and quantity; this query has a highly selective (0.18%) filter, along with aggregation on one column117x improvementcode_block[StructValue([(u’code’, u’select sum(lo_revenue) as revenuernfrom lineorderrnwhere lo_discount = 1rnand lo_quantity = 1′), (u’language’, u”)])]Example 2: For each ship mode, get the total revenue from sales where the discount and quantity were within a specific range; this query has a less selective (13%) filter, group by and aggregation on one column19x improvementcode_block[StructValue([(u’code’, u’select lo_shipmode, sum(lo_revenue) as revenuernfrom lineorderrnwhere lo_discount between 1 and 3 and lo_quantity < 25rngroup by lo_shipmode’), (u’language’, u”)])]Example 3: Get the total revenue from sales in a given year for which the discount and quantity were within a specific range; this query has a selective join (join selectivity = 14%) and the columnar engine uses a bloom filter to accelerate it. 8x improvementcode_block[StructValue([(u’code’, u’select sum(lo_revenue) as revenuernfrom lineorderrn left join date on lo_orderdate = d_datekeyrnwhere d_year = 1993 and lo_discount between 1 and 3rn and lo_quantity < 25′), (u’language’, u”)])]Example 4: Get the total revenue from sales in or before a given year for which the discount and quantity were within a specific range; this query has a much less selective join (join selectivity = 90%).2.6x improvementcode_block[StructValue([(u’code’, u’select sum(lo_revenue) as revenuernfrom lineorderrn left join date on lo_orderdate = d_datekeyrnwhere d_year <= 1997 and lo_discount between 1 and 3rn and lo_quantity < 25′), (u’language’, u”)])]We do not guarantee the same results illustrated by these examples because your results will be dependent on your data sets, database configurations and the queries that you run.Query plan exampleThe plan of a query executed using the columnar engine shows additional statistics that help identify various columnar optimizations that were invoked in order to make the query run faster. Key parts of the plan of example query 1:code_block[StructValue([(u’code’, u’Aggregate (cost=1006.43..1006.44 rows=1 width=8) (actual time=8.219..8.220 rows=1 loops=3)rn -> Parallel Append (cost=0.00..883.88 rows=49017 width=4) (actual time=0.221..8.208 rows=1 loops=3)rn -> Parallel Custom Scan (columnar scan) on lineorder (cost=20.00..879.88 rows=49016 width=4) (actual time=0.220..8.205 rows=36230 loops=3)rn Filter: ((lo_discount = 1) AND (lo_quantity = 1))rn Rows Removed by Columnar Filter: 19959121rn Rows Aggregated by Columnar Scan: 21216rn CU quals: ((lo_quantity = 1) AND (lo_discount = 1))rn Columnar cache search mode: nativern -> Parallel Seq Scan on lineorder (cost=0.00..4.01 rows=1 width=4) (never executed)rn Filter: ((lo_discount = 1) AND (lo_quantity = 1))’), (u’language’, u”)])]Understanding the query plan nodes:Custom Scan: This node is the Columnar Scan node that applies filters on the column store. It shows 19959121 rows removed by the Columnar Filter and 21216 rows aggregated by the columnar engine.Seq Scan: This node is the traditional Postgres row-store Sequential Scan node that is invoked only when the query planner decides to use hybrid execution mode, which it did not use in this case.Append: This node merges the results from Columnar Scan node (Custom Scan) and Row-store Sequential Scan node.ConclusionOur columnar engine enables analytical queries to run up to 100x faster than the traditional PostgreSQL engine based on our performance tests. This query processing technology enables you to run analytics and reporting directly against your operational database for real-time insights. Powered by ML-driven auto-population and management, the columnar engine automatically optimizes to your applications, completely transparently on each instance and with minimal management overhead, delivering fine-tuned performance with refreshing ease of use. To try AlloyDB out for yourself, visit cloud.google.com/alloydb.The AlloyDB technical innovations described in this and subsequent posts would not have been possible without the exceptional contributions of our engineering team.Related ArticleIntroducing AlloyDB for PostgreSQL: Free yourself from expensive, legacy databasesAlloyDB for PostgreSQL combines the best of Google with full PostgreSQL compatibility to achieve superior performance, availability, and …Read Article
Quelle: Google Cloud Platform