Posted by Grace Mollison, Solutions Architect
Using Google Cloud Deployment Manager is a great way to manage and automate your cloud environment. By creating a set of declarative templates, Deployment Manager lets you consistently deploy, update and delete resources like Google Compute Engine, Google Container Engine, Google BigQuery, Google Cloud Storage and Google Cloud SQL. As one of the less well known features of Google Cloud Platform (GCP), let’s talk about how to use Deployment Manager.
Deployment Manager uses three types of files:
a Configuration file written in YAML
Template files, based on Jinja 2.7.3 or Python 2.7
Schema files, which define a set of rules that a configuration file must meet if it wants to use a particular template
Using templates is the recommended method of using Deployment Manager, and requires a configuration file as a minimum. The configuration file defines the resources you wish to deploy and their configuration properties such as zone and machine type.
Deployment manager supports a wide array of GCP resources. Here’s a complete list of supported resources and associated properties, which you can also retrieve with this gcloud command:
$ gcloud deployment-manager types list
Deployment Manager is often used alongside a version control system into which you can check in the definition of your infrastructure. This approach is commonly referred to as “infrastructure as code” It’s also possible to pass properties to Deployment Manager directly using gcloud command, but that’s not a very scalable approach.
Anatomy of a Deployment Manager configuration
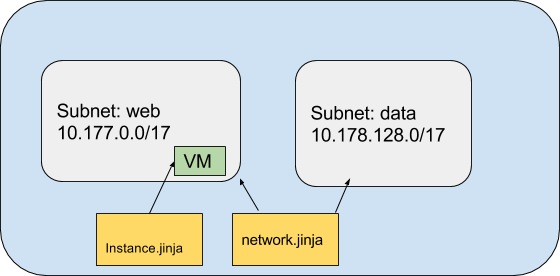
To understand how things fit together, let’s look at the set of files that are used to create a simple network with two subnets and a single deployed instance.
The configuration consists of three files:
net-config.yaml – configuration file
network.jinja – template file
instance.jinja – template file
You can use template files as logical units that break down the configuration into smaller and reusable parts. Templates can then be composed into a larger deployment. In this example, network configuration and instance deployment have been broken out into their own templates.
Understanding templates
Templates provide the following benefits and functionality:
Composability, making it easier to manage, maintain and reuse the definitions of the cloud resources declared in the templates. In some cases you may not want to recreate the end-to-end configuration as defined in the configuration file. In that case, you can just reuse one or more templates to help ensure consistency in the way in which you create resources.
Templates written in your choice of Python or Jinja2. Jinja2 is a simpler but less powerful templating language than Python. It uses the same syntax as YAML but also allows the use of conditionals and loops. Python templates are more powerful and allow you to programmatically generate the contents of your templates.
Template variables – an easy way to reuse templates by allowing you to declare the value to be passed to the template in the configuration file. This means that you can change a specific value for each configuration without having to update the template. For example, you may wish to deploy your test instances in a different zone to your production instances. In that case, simply declare within the template a variable that inherits the zone value from the master configuration file.
Environment variables, which also help you reuse templates across different projects and deployments. Examples of an environment variable include things like the Project ID or deployment name, rather than resources you want to deploy.
Here’s how to understand the distinction between the template and environment variables. Imagine you have two projects where you wish to deploy identical instances, but to different zones. In this case, name your instances based on the Project ID and Deployment name found from the environment variables, and set the zone through a template variable.
A Sample Deployment Manager configuration
For this example, we’ve decided to keep things simple and use templates written in Jinja2.
The network file
This file creates a network and its subnets whose name and range are passed through from the variable declaration in net-config.yaml, the calling configuration file.
The “for” subnet loop repeats until it has read all the values in the subnets properties. The config file below declares two subnets with the following values:
Subnet name
IP range
web
10.177.0.0/17
data
10.178.128.0/17
The deployment will be deployed into the us-central1 region. You can easily change this by changing the value of the “region” property in the configuration file without having to modify the network template itself.
The instance file
The instance file, in this case “instance.jinja,” defines the template for an instance whose machine type, zone and subnet are defined in the top level configuration file’s property values.
The configuration file
This file, called net-config.yaml, is the main configuration file that marshals the templates that we defined above to create a network with a single VM.
To include templates as part of your configuration, use the imports property in the configuration file that calls the template (going forward, the master configuration file). In our example the master configuration file is called net-config.yaml and imports two templates at lines 15 – 17:
The resource network is defined by the imported template network.jinja.
The resource web-instance is defined by the imported template instance.jinja.
Template variables are declared that are passed to each template. In our example, lines 19 – 27 define the network values that are passed through to the network.ninja template.
Lines 28 to 33 define the instance values.
To deploy a configuration, pass the configuration file to Deployment Manager via the gcloud command or the API. Using gcloud command, type the following command:
$ gcloud deployment-manager deployments create net –configuration net-config.yaml
You’ll see a message indicating that the deployment has been successful
You can see the deployment from Cloud Console.
Note that the instance is named after the deployment specified in instance.jinja.
The value for the variable “deployment” was passed in via the gcloud command “create net” where “net” is the name of the deployment
You can explore the configuration by looking at the network and Compute Engine menus:
You can delete a deployment from Cloud Console by clicking the delete button or with the following gcloud command:
$ gcloud deployment-manager deployments delete net
You’ll be prompted for verification that you want to proceed.
Next steps
Once you understand the basics of Deployment Manager, there’s a lot more you can do. You can take the example code snippets that we walked through here and build more complicated scenarios, for example, implementing a VPN that connects back to your on premises environment. There are also many Deployment Manager example configurations on Github.
Then, go ahead and start thinking about advanced Deployment Manager features such as template modules and schemas. And be sure to let us know how it goes.
Quelle: Google Cloud Platform